
妙啊!无人机直连卫星传Token
妙啊!无人机直连卫星传Token这便是中国电信人工智能研究院(TeleAI),刚刚在WAIC 2026提出的新技术路线;其背后这套融合AI、通信和网络的技术体系,则是智传网(AI Flow)。就在此次发布前一天,智传网(AI Flow)还拿下了WAIC大会最高奖项卓越人工智能引领者奖(SAIL)中的赋能(Applicative)奖。
来自主题: AI资讯
9265 点击 2026-07-18 16:45
 搜索
搜索
这便是中国电信人工智能研究院(TeleAI),刚刚在WAIC 2026提出的新技术路线;其背后这套融合AI、通信和网络的技术体系,则是智传网(AI Flow)。就在此次发布前一天,智传网(AI Flow)还拿下了WAIC大会最高奖项卓越人工智能引领者奖(SAIL)中的赋能(Applicative)奖。

50多个智算中心,超过1000 EFLOPS的智能算力规模,平均利用效率却远远没有跑满。是石给出的解法,叫拓元(Vectron),一座国产Token优化工厂。是石科技依托国家级计算中心工程经验积淀,持续投入大规模集群研发,建设万卡级国产大集群,持续稳定运营,优化推理效率,构筑了深厚壁垒
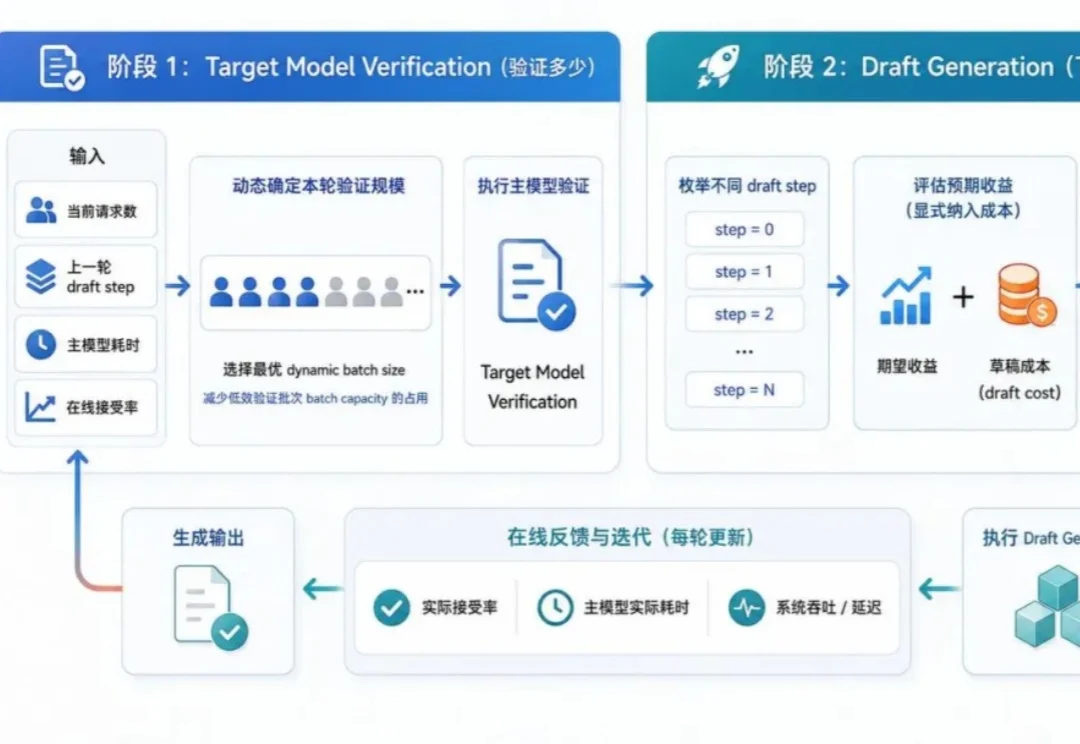
随着 DeepSeek 发布 DSpark,动态 MTP(多 Token 预测)成为了对抗高并发、提升 GPU 利用率的绝对焦点。然而,DSpark 高度绑定特定模型且需要额外训练。

7 月 16 日,月之暗面正式发布 Kimi K3:总参数量 2.8 万亿(2.8T),原生视觉理解,100 万 token 上下文,并且——开源权重。这是历史上第一个摸到 2.8 万亿参数量级的开源模型。前任"开源最大模型"的纪录保持者?也是它自己。

时至今日,全球大模型格局已成定数,还有必要耗费巨资从零开始训练一个新模型吗?
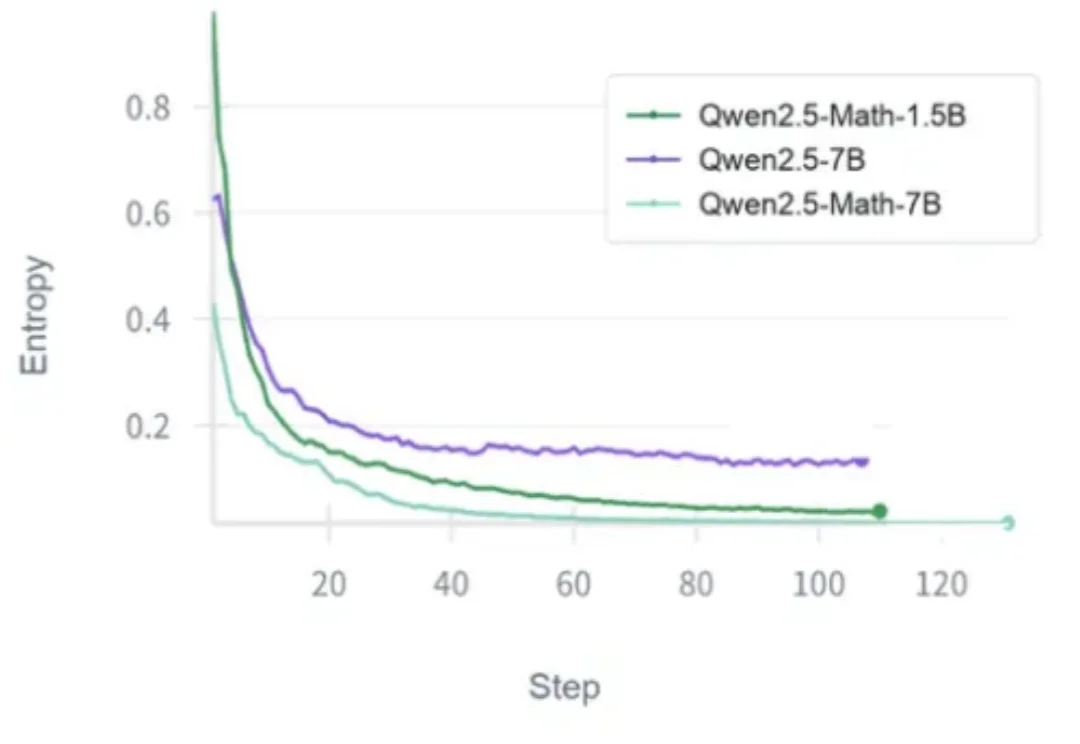
基于可验证奖励的强化学习(Reinforcement Learning with Verifiable Rewards,RLVR)正在成为大模型后训练的关键技术。数学题能判对错,代码能跑测试,可验证奖励让大模型可以通过强化学习持续提升推理能力。

推理大模型 (如 DeepSeek-R1、o1) 靠长思维链拿高分,却普遍「想太多」: 研究统计了五个代表性模型里,发现有 41–52% 的 token 是在模型给出它的最终答案之后生成的。
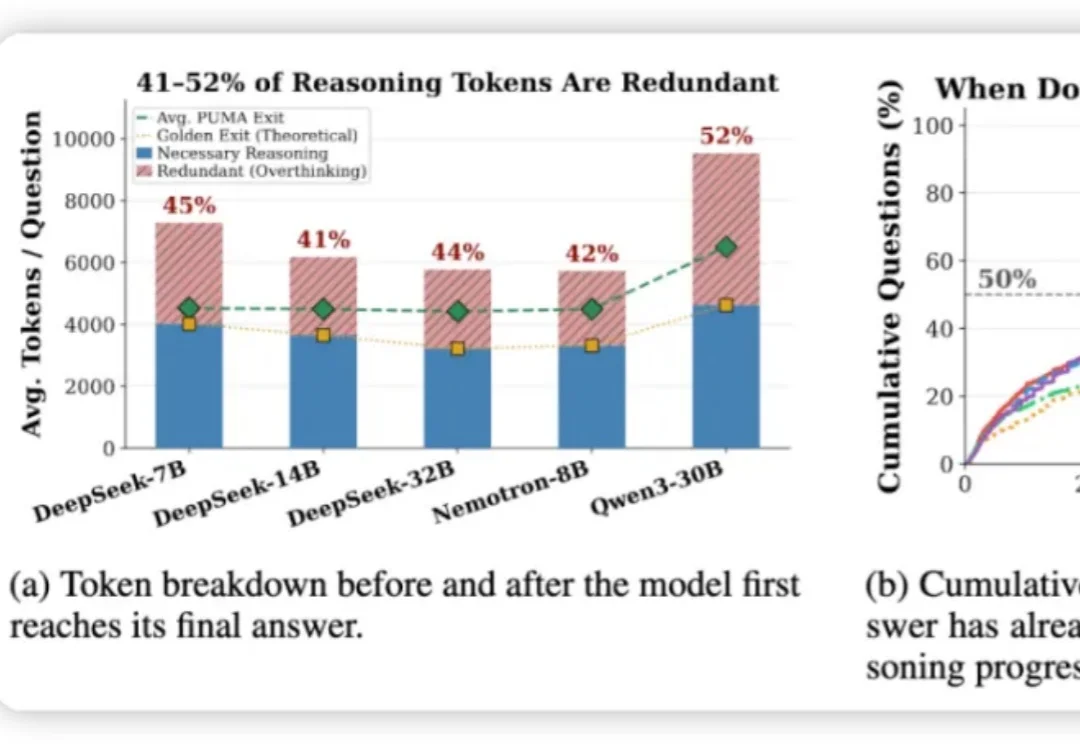
推理大模型 (如 DeepSeek-R1、o1) 靠长思维链拿高分,却普遍「想太多」: 研究统计了五个代表性模型里,发现有 41–52% 的 token 是在模型给出它的最终答案之后生成的。
一笔融资进入我们视野——今日(7月13日),趋境科技A轮融资浮出水面,由河南投资集团汇融基金重磅领投,真知资本、尚势资本、星连资本、上海国方创新、弘晖基金、华控基金、杭州福成等老股东继续超额增投。

“购买使用AI时,钱可能要付两遍!”