
满血DeepSeek V4塞进办公室!专属「Token工厂」成标配
满血DeepSeek V4塞进办公室!专属「Token工厂」成标配一夜之间,Tokenmaxxing成为硅谷热议话题!
来自主题: AI技术研报
7709 点击 2026-07-23 10:40
 搜索
搜索
一夜之间,Tokenmaxxing成为硅谷热议话题!
这家公司是Fireworks AI,按现在流行的话说,Fireworks AI是一家Token工厂。既不训练前沿大模型,也不做面向消费者的AI应用,只做推理,帮企业把开源模型微调好、托管好,然后按调用量收钱。今年GTC大会上,黄仁勋和Lin Qiao有场对谈,老黄直言,“In a lot of ways, you're the TSMC of AI factories.”
“ 硅基流动却带亏上市:中美Token中间商,为何同人不同命?” “中美Token分发商,正在走向两条截然不同的路。”某国产大模型厂商的 API 生态负责人王栋告诉雷峰网。近日,全球头部大模型 API 聚合平台 OpenRouter 被曝寻求“卖身”,正与多家科技巨头洽谈收购机会。

2026年WAIC的展厅里,人潮涌动。大模型厂商在秀参数,算力厂商在秀集群规模。

五千名工程师,四个月,把Uber一整年的AI预算烧成了灰。

“「出海四巨头」智谱、Kimi、千问......谁最受外企欢迎? ” 作者丨胡清文 编辑丨徐晓飞 去年这个时候,硅谷讨论的还是中国模型能不能打。但在今年,这个问题已经被一组数据碾过。 OpenRout

就在今年的WAIC上,无问芯穹一口气亮出了「前店后厂一中心」,一整套完整的Agentic Infra战略布局:算力集散中心(一中心):Agentic Infra自主式基础设施平台;Token工厂(后厂):Agentic MaaS大模型服务平台;

“芯片的定价权越强,模型和应用公司的成本刚性就越难消解。” 当下,仅豆包一家大模型的日均Token调用量就已突破180万亿;国家数据局的统计显示,全国日均调用量在今年3月已超过140万亿——无论从哪个口径衡量,这都是一条两年内从“近乎为零”飙涨超千倍的曲线。
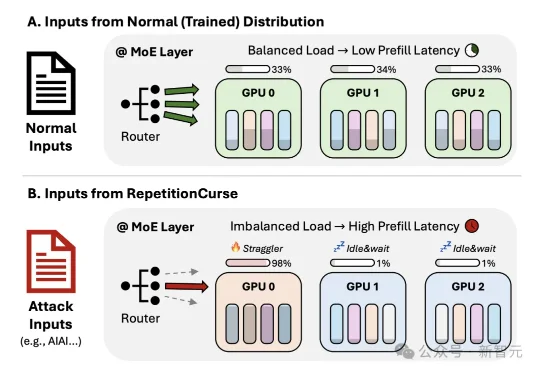
来自港科大的研究团队提出了RepetitionCurse,这是一种针对MoE大模型服务的黑盒压力测试方法。它不需要模型权重,不需要梯度,也不需要知道后端专家如何部署,只利用高度重复的输入模式,就能诱导专家路由把大量token路由到同一小批专家上。

Kimi K3 是一个 2.8 万亿参数模型,基于 KDA 混合线性注意力机制(Kimi Delta Attention)和注意力残差(Attention Residuals)技术构建,原生支持视觉理解,并拥有 100 万 token 上下文窗口。它是全球首个开源的 3 万亿级别模型,面向长程编程、知识工作和推理等前沿智能场景而设计。