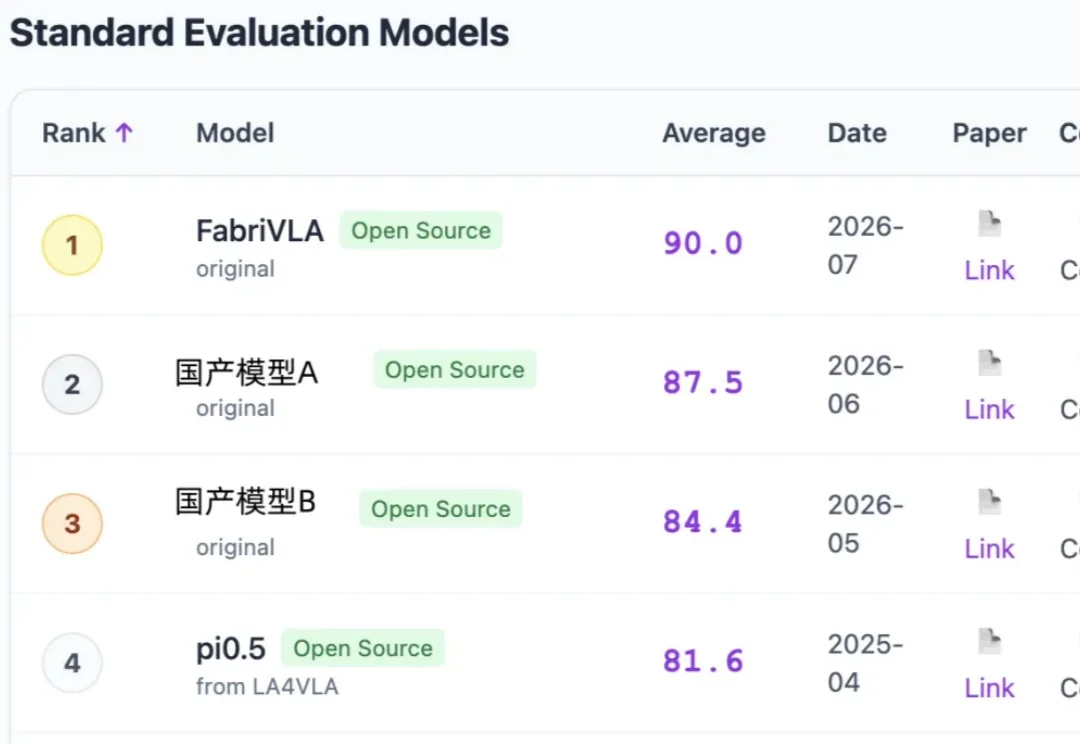
超越π0,中国团队用1B参数模型登顶具身智能榜单
超越π0,中国团队用1B参数模型登顶具身智能榜单谁能想到,在全球具身智能操作能力的顶级榜单上,打败海外标杆模型π0的,居然是一个只有1B级参数的轻量级模型。
来自主题: AI资讯
8880 点击 2026-07-23 16:33
 搜索
搜索
谁能想到,在全球具身智能操作能力的顶级榜单上,打败海外标杆模型π0的,居然是一个只有1B级参数的轻量级模型。

大家好,我是瓦力,具身算法研究员。 我有个习惯,隔三差五都会去 PI 的官网刷一下,看他有没有新东西。最近这三个月,官网主页是一动没动,停在四月的 π0.7。
今天凌晨,Physical Intelligence发布了全新的VLA模型π0.7,狠狠敲了世界模型一记闷棍。π0.7第一次在机器人领域证明了Compositional Generalization(组合泛化),且VLA。

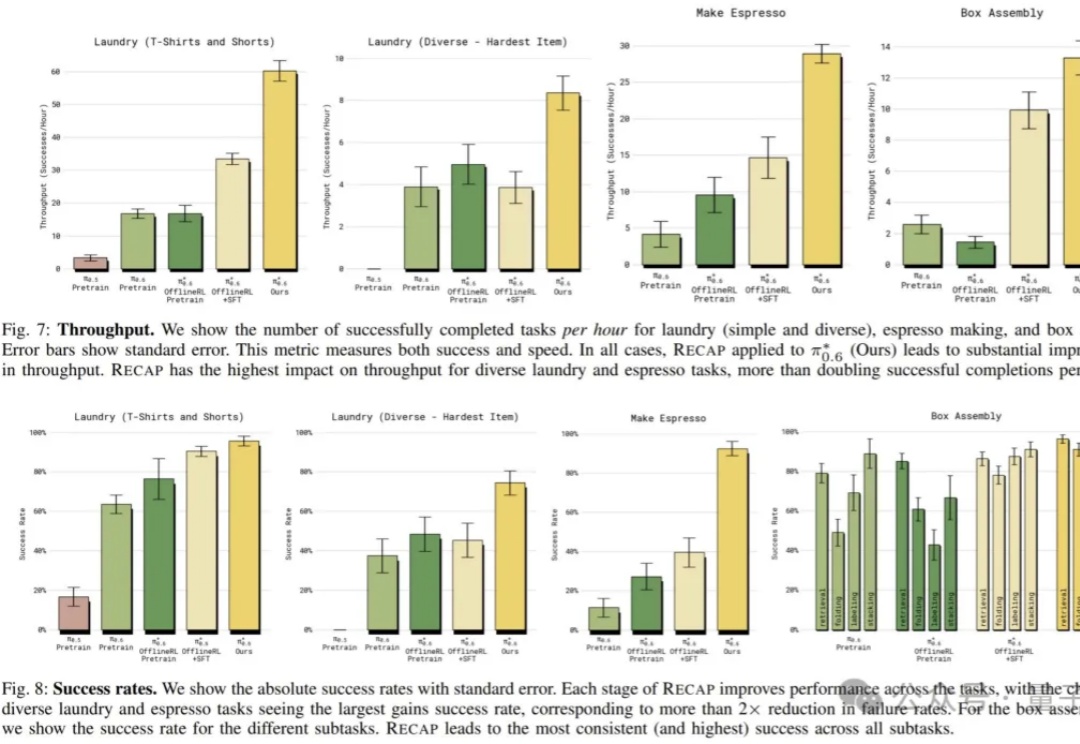
极佳视界具身大模型 GigaBrain-0.5M*,以世界模型预测未来状态驱动机器人决策,并实现了持续自我进化,超越π*0.6 实现 SOTA!该模型在叠衣、冲咖啡、折纸盒等真实任务中实现接近 100% 成功率;相比主流基线方法任务成功率提升近 30%;基于超万小时数据训练,其中六成由自研世界模型高保真合成。

2022年,Google Cloud 将π计算到100万亿位,在2025年,高性能计算界的知名评测机构 StorageReview只用了4个月的时间,花了不到一千美元电费就将π算到314万亿位,这可不是为了炫技,而是说明高性能计算也可以很节能。

在 Physical Intelligence 最新的成果 π0.6 论文里,他们介绍了 π0.6 迭代式强化学习的思路来源:

Vision–Language–Action(VLA)策略正逐渐成为机器人迈向通用操作智能的重要技术路径:这类策略能够在统一模型内同时处理视觉感知、语言指令并生成连续控制信号。
看似轻描淡写,实则力透纸背。
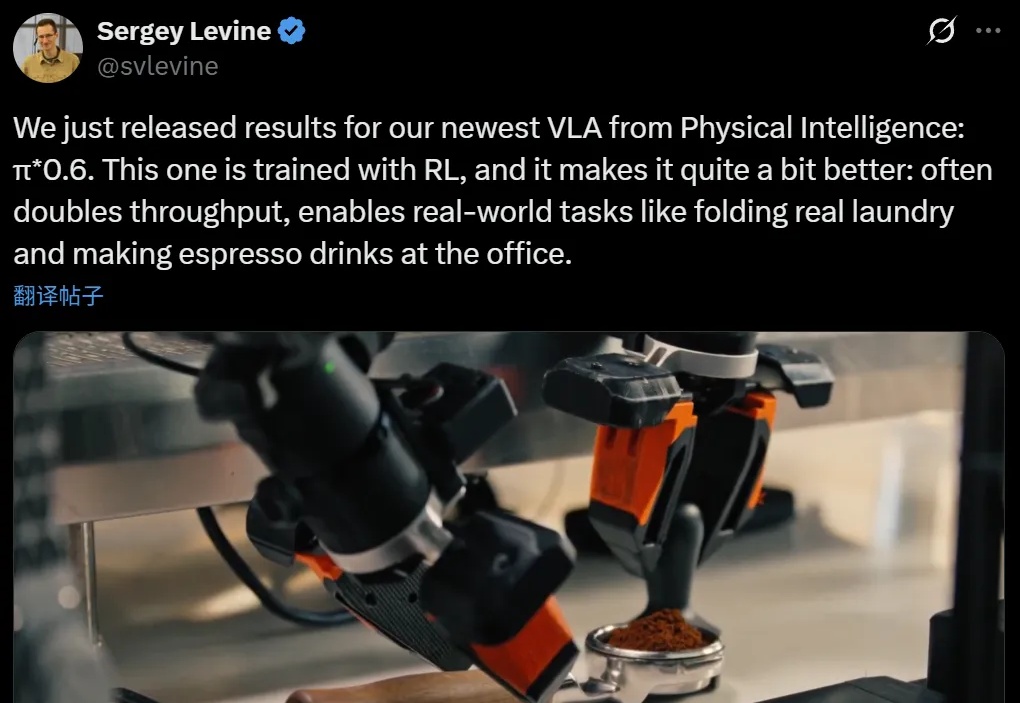
本周,美国具身智能创业公司 Physical Intelligence(简称 PI 或 π)发布了旗下的最新机器人基础模型 π*0.6。PI 是一家总部位于旧金山的机器人与 AI 创业公司,其使命是将通用人工智能从数字世界带入物理世界:他们的首个机器人通用基础模型名为 π₀,让同一套软件控制多种物理平台执行各类任务。
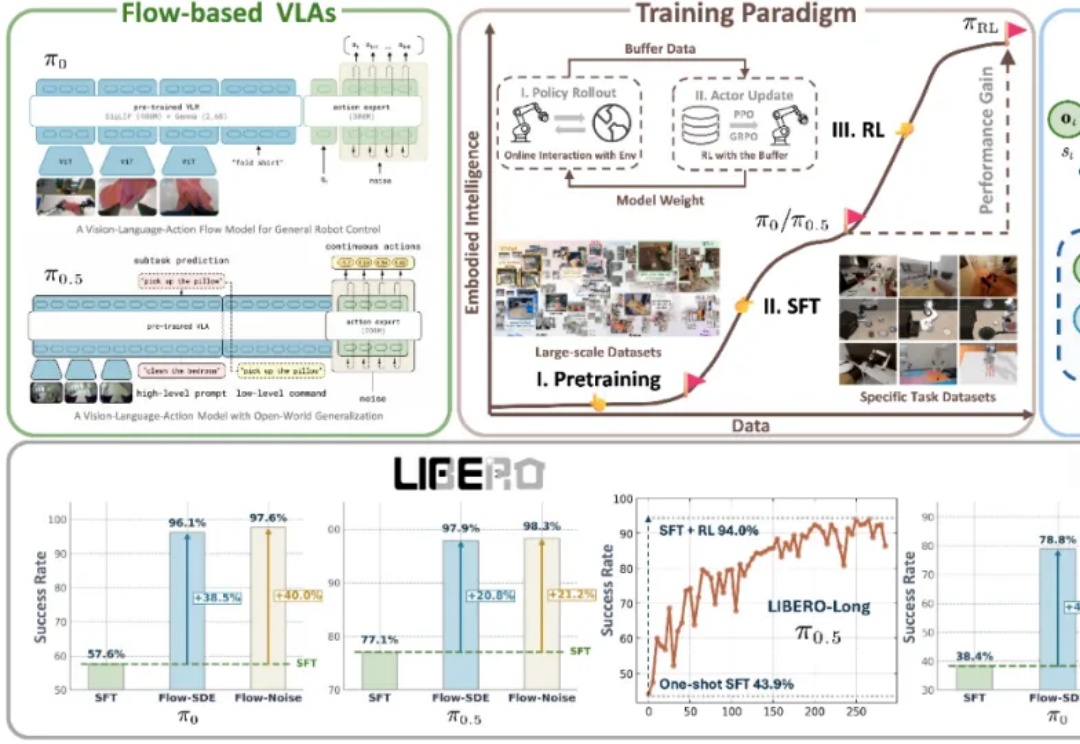
近年来,基于流匹配的 VLA 模型,特别是 Physical Intelligence 发布的 π0 和 π0.5,已经成为机器人领域备受关注的前沿技术路线。流匹配以极简方式建模多峰分布,能够生成高维且平滑的连续动作序列,在应对复杂操控任务时展现出显著优势。