
超越π0.5,复旦团队首创「世界模型+具身训练+强化学习」闭环框架
超越π0.5,复旦团队首创「世界模型+具身训练+强化学习」闭环框架Vision–Language–Action(VLA)策略正逐渐成为机器人迈向通用操作智能的重要技术路径:这类策略能够在统一模型内同时处理视觉感知、语言指令并生成连续控制信号。
来自主题: AI技术研报
9831 点击 2025-12-05 09:27
 搜索
搜索
Vision–Language–Action(VLA)策略正逐渐成为机器人迈向通用操作智能的重要技术路径:这类策略能够在统一模型内同时处理视觉感知、语言指令并生成连续控制信号。
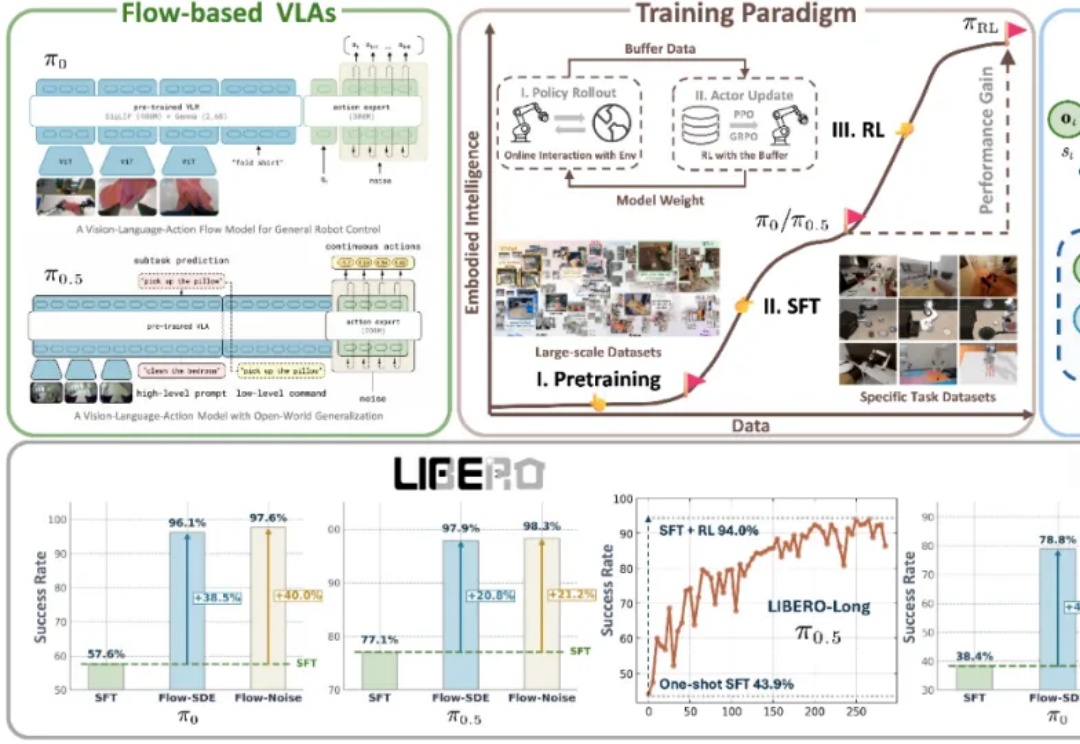
近年来,基于流匹配的 VLA 模型,特别是 Physical Intelligence 发布的 π0 和 π0.5,已经成为机器人领域备受关注的前沿技术路线。流匹配以极简方式建模多峰分布,能够生成高维且平滑的连续动作序列,在应对复杂操控任务时展现出显著优势。

具身智能最大的挑战在于泛化能力,即在陌生环境中正确完成任务。最近,Physical Intelligence推出全新的π0.5 VLA模型,通过异构任务协同训练实现了泛化,各种家务都能拿捏。
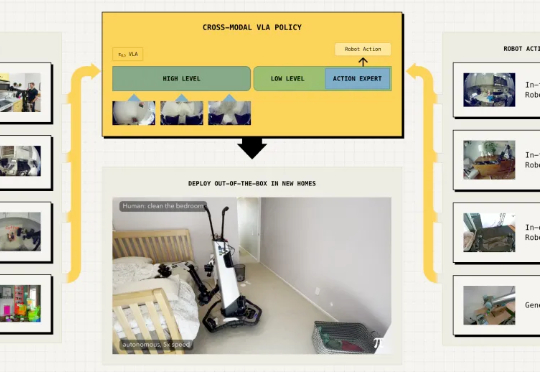
今天,美国具身智能公司 Physical Intelligence 推出了一个基于 π0 的视觉-语言-动作(VLA)模型 π0.5,其利用异构任务的协同训练来实现广泛的泛化,可以在全新的家中执行各种任务。