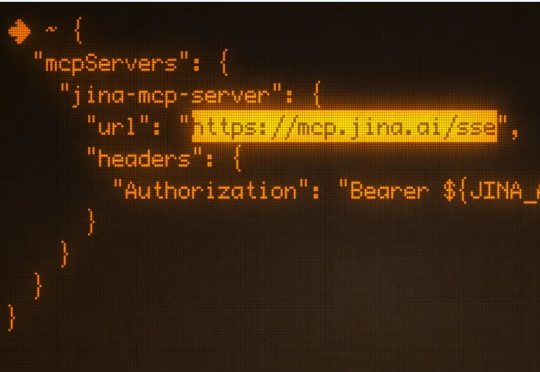
Jina官方MCP三板斧:搜、读、筛
Jina官方MCP三板斧:搜、读、筛模型上下文协议 (MCP) 是连接 LLM/Agent 与外部工具的通信标准。它允许 LLM 动态发现并调用 API工具,将他们串成一个完整的工作流,从而实现自主规划、推理与执行。 上个月我们悄悄发布
来自主题: AI技术研报
10507 点击 2025-10-06 13:23
 搜索
搜索
模型上下文协议 (MCP) 是连接 LLM/Agent 与外部工具的通信标准。它允许 LLM 动态发现并调用 API工具,将他们串成一个完整的工作流,从而实现自主规划、推理与执行。 上个月我们悄悄发布

构建有价值的AI Agent需审慎选择场景,避免滥用。应用前需评估任务复杂性、价值是否匹配成本、模型核心能力有无硬伤及出错风险容忍度。开发时坚持极简原则,聚焦环境、工具集、系统提示三大核心要素。优化调试的关键在于理解Agent有限上下文视角,模拟其受限决策状态。
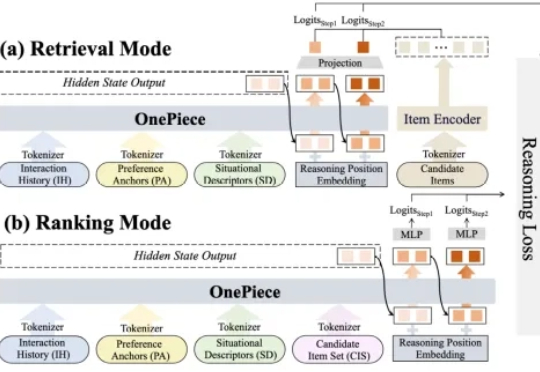
2025 年,生成式推荐(Generative Recommender,GR)的发展如火如荼,其背后主要的驱动力源自大语言模型(LLM)那诱人的 scaling law 和通用建模能力(general-purpose modeling),将这种能力迁移至搜推广工业级系统大概是这两年每一个从业者孜孜不倦的追求。

9 月 26 日,Flowith 再次迎来了大更新,这一次,它的核心所指,正是「上下文腐烂」以及更加「自由的创作」。接下来,我们分享全面实测体验。从我的实际体验来看,这次的 Flowith 更新,终于让上下文「活」起来了。
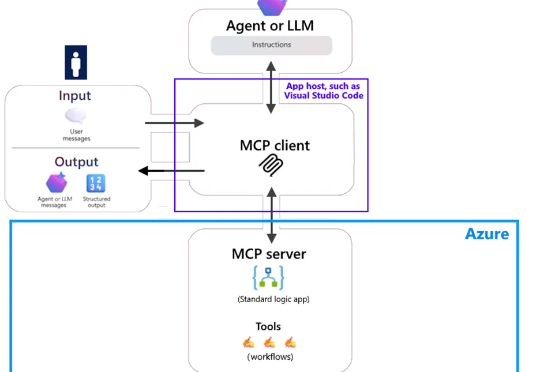
最近,微软宣布了一项新功能的公开预览。该功能使 Azure Logic Apps(标准版)能够充当 MCP 服务器,为开发者提供了一种灵活的方式来构建和管理代理。在 Azure Logic Apps 中,用户可以重新配置 Standard Logic App 使其充当远程模型上下文协议(MCP)服务器,快速启动这些工具的构建工作。
刚刚,Meta FAIR推出了代码世界模型!CWM(Code World Model),一个参数量为32B、上下文大小达131k token的密集语言模型,专为代码生成和推理打造的研究模型。这是全球首个将世界模型系统性引入代码生成的语言模型。

xAI重磅推出Grok 4 Fast,创新融合推理与非推理双模式,支持200万token上下文。在NYT Connections基准和AA智能指数中表现卓越,超越多家顶级模型,标志着AI智能获取门槛的进一步降低。

Notion 应该是传统互联网工具产品 AI 转型最成功的一个。昨晚,他们更新了 Notion 3.0,现在的 Notion 可以看作一个你有所有上下文的通用 Agent 产品,而且你可以在这里用所有顶尖模型完成任务。
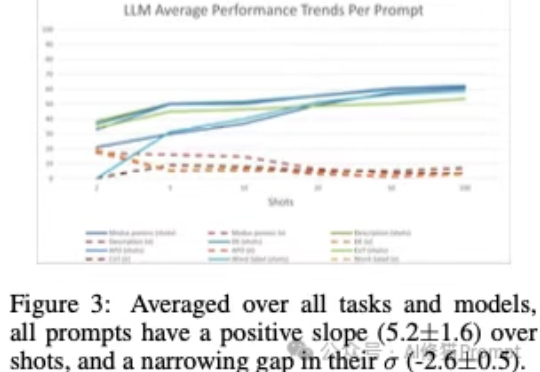
上下文学习”(In-Context Learning,ICL),是大模型不需要微调(fine-tuning),仅通过分析在提示词中给出的几个范例,就能解决当前任务的能力。您可能已经对这个场景再熟悉不过了:您在提示词里扔进去几个例子,然后,哇!大模型似乎瞬间就学会了一项新技能,表现得像个天才。
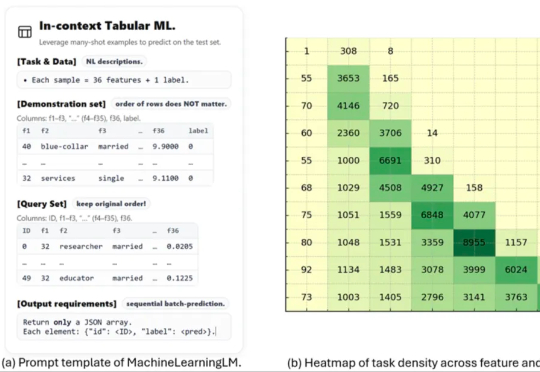
这项名为 MachineLearningLM 的新研究突破了这一瓶颈。该研究提出了一种轻量且可移植的「继续预训练」框架,无需下游微调即可直接通过上下文学习上千条示例,在金融、健康、生物信息、物理等等多个领域的二分类 / 多分类任务中的准确率显著超越基准模型(Qwen-2.5-7B-Instruct)以及最新发布的 GPT-5-mini。