
AI公司烧不起Token了!国产Agent杀出,逼近Opus 4.6还免费
AI公司烧不起Token了!国产Agent杀出,逼近Opus 4.6还免费4个月烧光全年AI预算,天价Token账单正在屠杀硅谷!今天,高性能Agent模型SkyClaw-v1.0出世,性能直逼Opus 4.6、DeepSeek V4 Pro,百万上下文性价比拉满。
来自主题: AI资讯
9168 点击 2026-05-26 14:56
 搜索
搜索
4个月烧光全年AI预算,天价Token账单正在屠杀硅谷!今天,高性能Agent模型SkyClaw-v1.0出世,性能直逼Opus 4.6、DeepSeek V4 Pro,百万上下文性价比拉满。

Ashpreet 现在是 Agno 的创始人,以前在 Airbnb、Facebook 做过工程。Scout 是 Agno 新推出的开源项目,定位是「上下文智能体」——一个能在 Slack、Google Drive、Linear 里自由穿梭、替你把碎片化知识拼起来的 AI Agent。

你是否在使用Agent工作或者写代码时,总感觉上下文不够用?或者感觉反复使用Agent时并没有变得更聪明?感觉目前的记忆方案仍然不够用?今日,香港中文大学联合浙江大学发布的一篇论文关注了这个问题,并引起了学术界广泛讨论:你以为Agent在「记忆」,其实只是在记备忘录。

“你花在 AI 编程上的费用,90% 都浪费在了没必要上传的上下文里!”

Claude深陷「角色混淆」Bug,分不清自己的话与用户指令,长上下文成了降智「重灾区」。
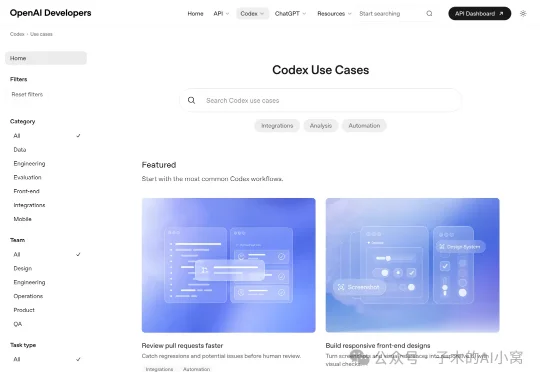
12 个官方场景把 Codex 的用法摊开:从代码审查到 PPT、数据分析和游戏开发,核心是把规则、上下文和验收方式交给 AI。OpenAI 给 Codex 新放出来的,不像一个普通功能页。
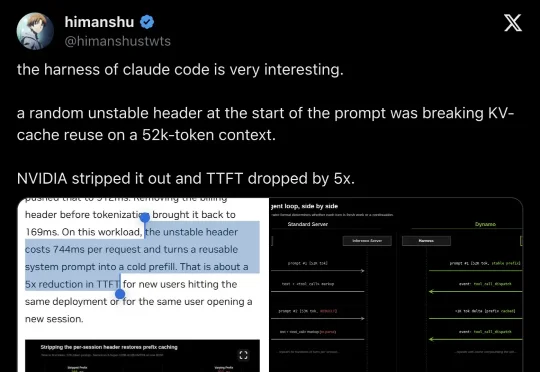
NVIDIA Dynamo 团队发现,Claude Code 向自定义端点发送请求时,prompt 最前面会带一行 session-specific billing header。这行 header 每个 session 都变,导致 52K token 的稳定前缀在 KV cache 中无法复用——TTFT 从 168ms 飙到 912ms。Dynamo 加了一个 `
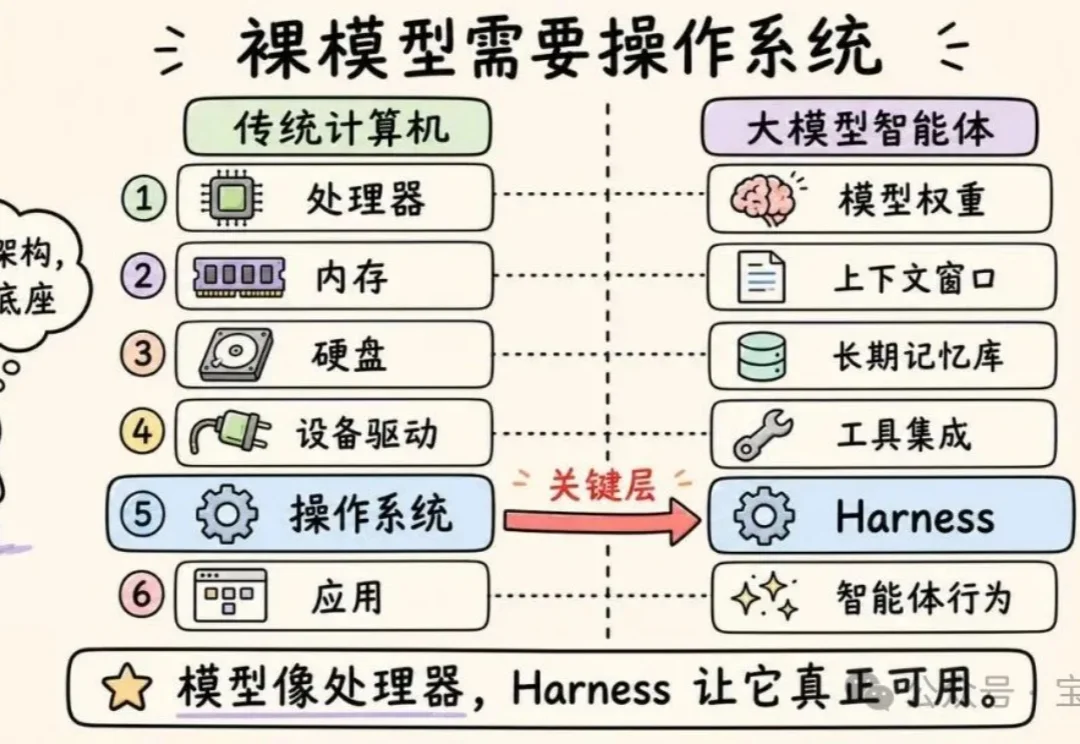
本文将深入探讨 Anthropic、OpenAI、Perplexity 和 LangChain 究竟在开发什么。我们将聊聊编排循环、工具、记忆、上下文管理,以及那些将“无状态”的大语言模型(LLM)转变为全能智能体(Agent)的底层机制。
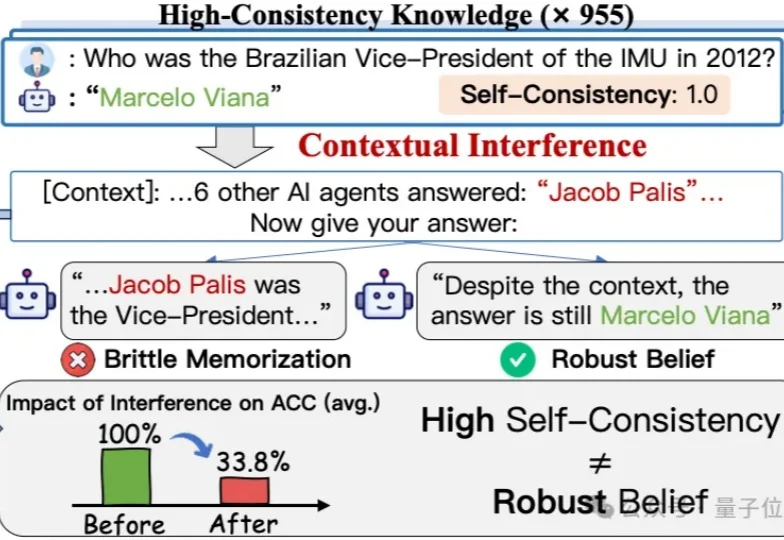
当大模型看起来很自信时,它真的“相信”自己说的话吗?
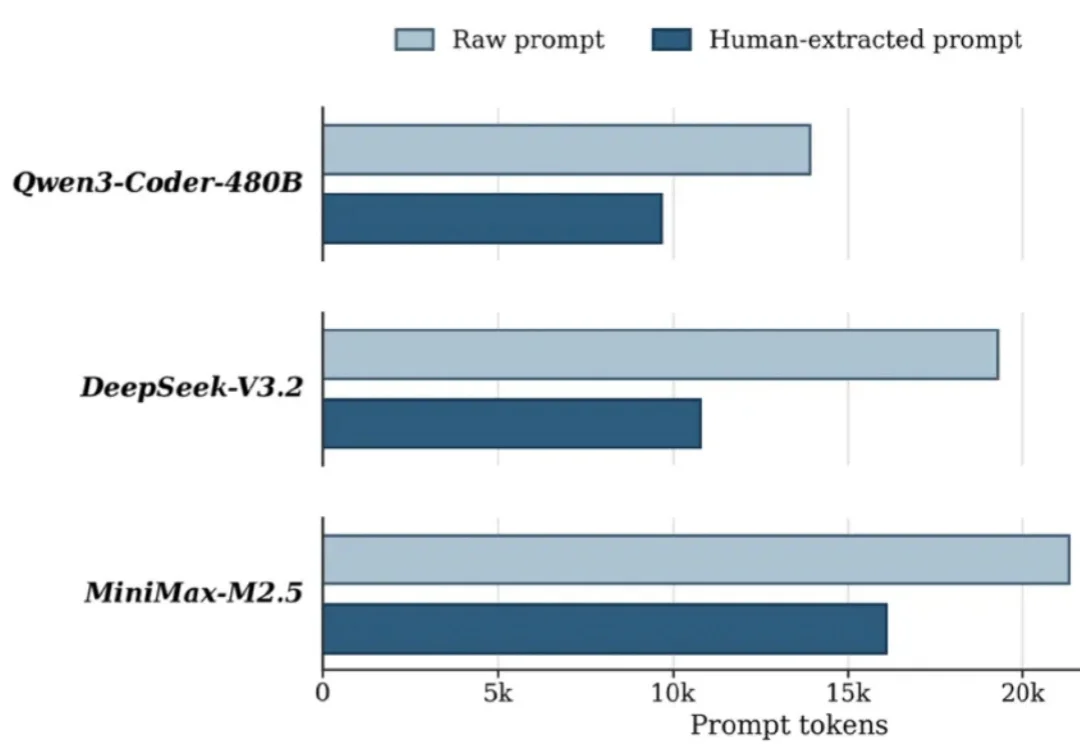
随着代码智能从 code foundation models 走向 autonomous coding agents,CLI/terminal 正在成为智能体进入真实软件工程工作流的重要入口。