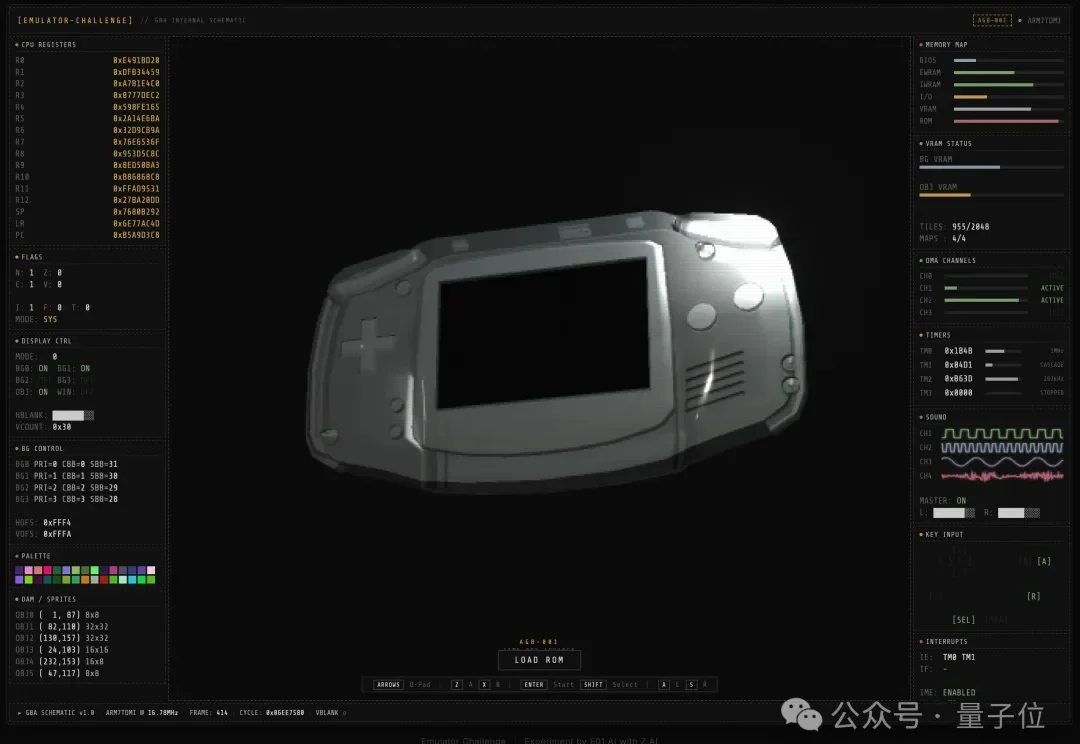
GLM-5真够顶的:超24小时自己跑代码,700次工具调用、800次切上下文!
GLM-5真够顶的:超24小时自己跑代码,700次工具调用、800次切上下文!当看到GLM-5正式发布后的能力,才惊觉前几天神秘模型Pony Alpha的热度还是有点保守了。
来自主题: AI技术研报
6873 点击 2026-02-13 12:08
 搜索
搜索
当看到GLM-5正式发布后的能力,才惊觉前几天神秘模型Pony Alpha的热度还是有点保守了。

DiscoX构建了一套200题的长文翻译数据集,以平均长度1,712 tokens的长篇章做评测单元,要求整个长文文本作为一个整体来翻译,除翻译准确度外,重点考察跨段落的逻辑与风格一致性、上下文中的术语精确性、以及专业写作规范,贴合用户真实的使用场景。
这两天 AI 圈真的太热闹了,就在网传 DeepSeek 要更新支持 100 万 Token 上下文的新模型时,MiniMax 率先冲锋,更新了他们的新旗舰模型:MiniMax-M2.5。更有意思的是,国外网友这段时间对国内 AI 大模型的更新节奏格外关注,他们甚至把这种争先更新的现象称为:Happy Chinese new year!
春节假期还没到,DeepSeek 就先把礼物拆了一半。
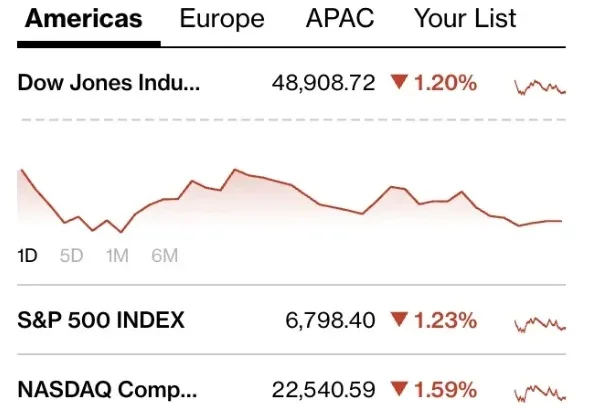
最强的大模型,已经把scaling卷到了一个新维度:百万级上下文。

不久前在 AGI-Next 前沿峰会上,姚顺雨曾分享过一个核心观点:模型想要迈向高价值应用,核心瓶颈就在于能否「用好上下文(Context)」。

Clawdbot(现改名为 OpenClaw) 体验下来,持久的记忆管理系统很是让人惊艳——全天候保持上下文,无限期地记住对话并在此基础上持续深化互动。

过去一年,几乎所有 AI 产品都在谈一个词:记忆。
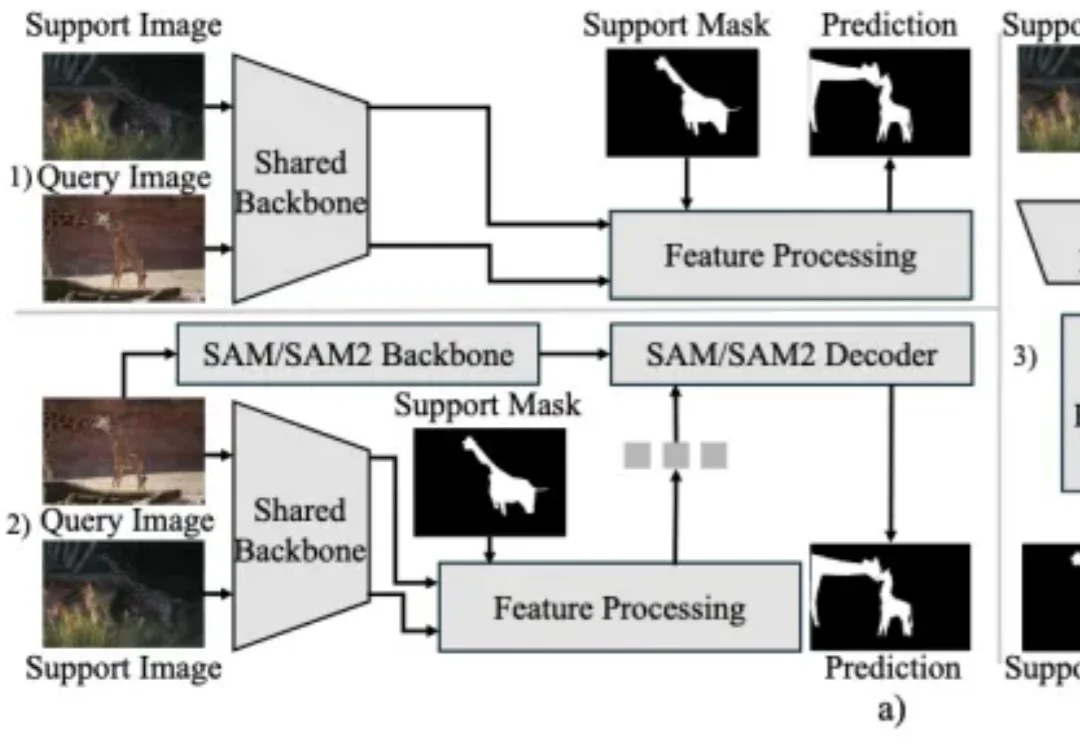
上下文分割(In-Context Segmentation)旨在通过参考示例指导模型实现对特定目标的自动化分割。尽管 SAM 凭借卓越的零样本泛化能力为此提供了强大的基础,但将其应用于此仍受限于提示(如点或框)构建,这样的需求不仅制约了批量推理的自动化效率,更使得模型在处理复杂的连续视频时,难以维持时空一致性。
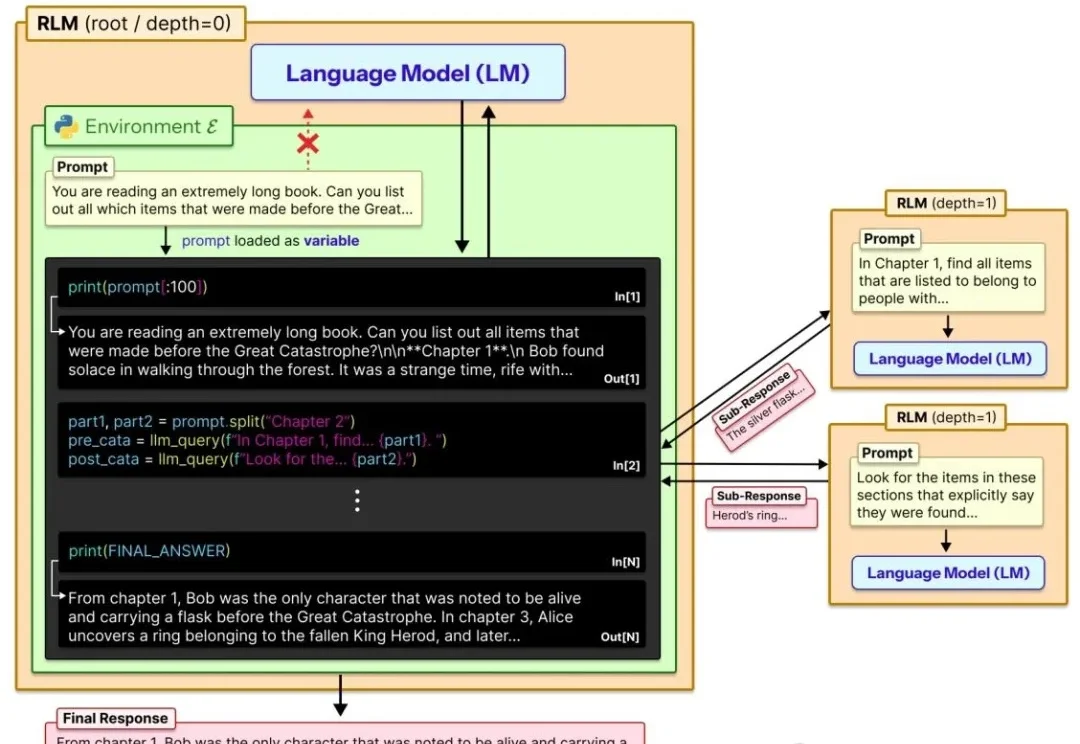
让大模型轻松处理比自身上下文窗口长两个数量级的超长文本!