
深度解读|为什么飞书和安克要联合发布一个随身录音设备?
深度解读|为什么飞书和安克要联合发布一个随身录音设备?AI 时代飞书更大的价值,与打开更丰富「上下文」的输入端口紧密相关。
来自主题: AI资讯
8230 点击 2026-01-19 16:45
 搜索
搜索
AI 时代飞书更大的价值,与打开更丰富「上下文」的输入端口紧密相关。
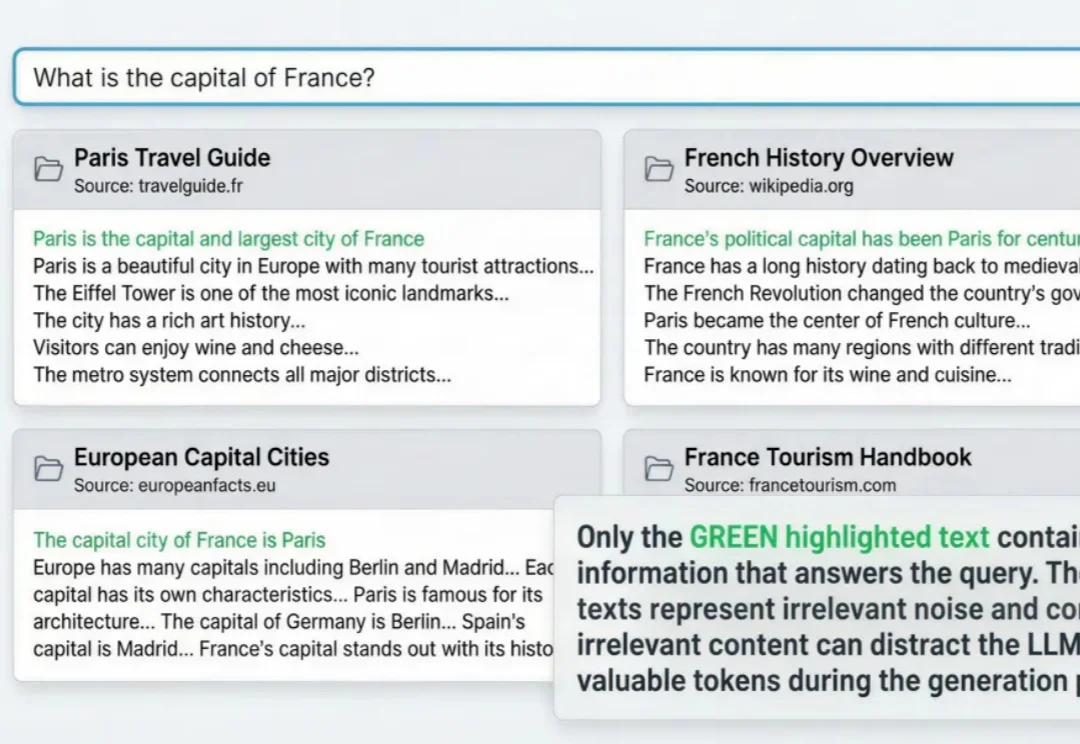
RAG与agent用到深水区,一定会遇到这个问题: 明明架构很完美,私有数据也做了接入,但项目上线三天,不但token账单爆了,模型输出结果也似乎总差点意思。
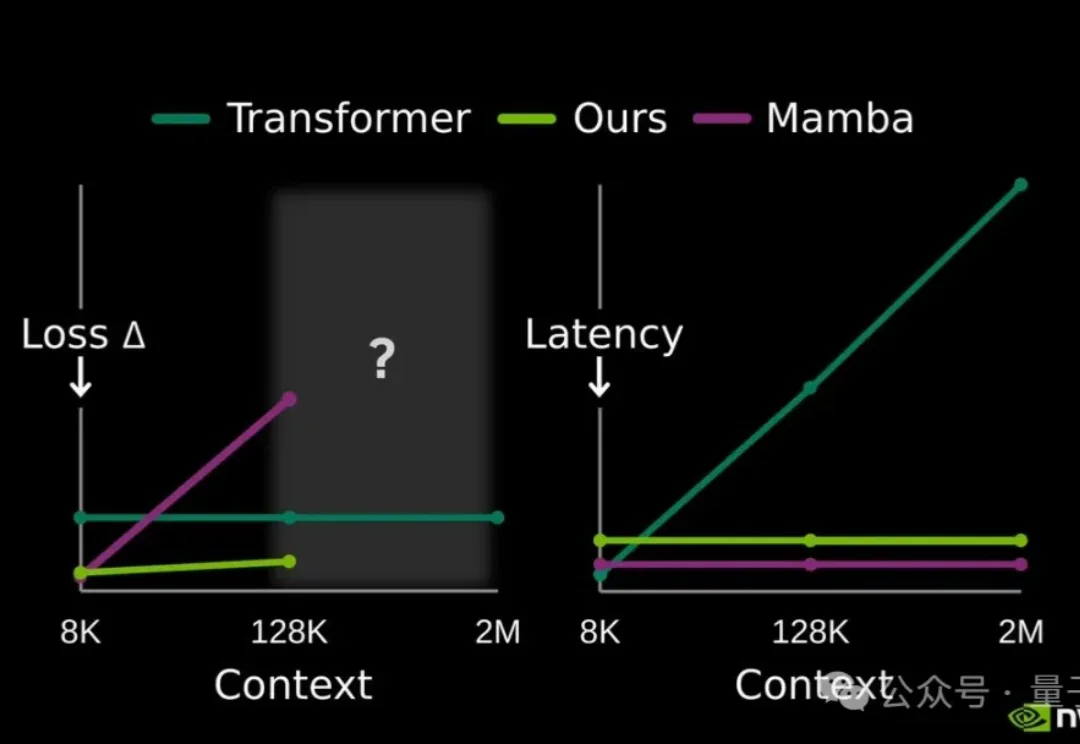
提高大模型记忆这块儿,美国大模型开源王者——英伟达也出招了。
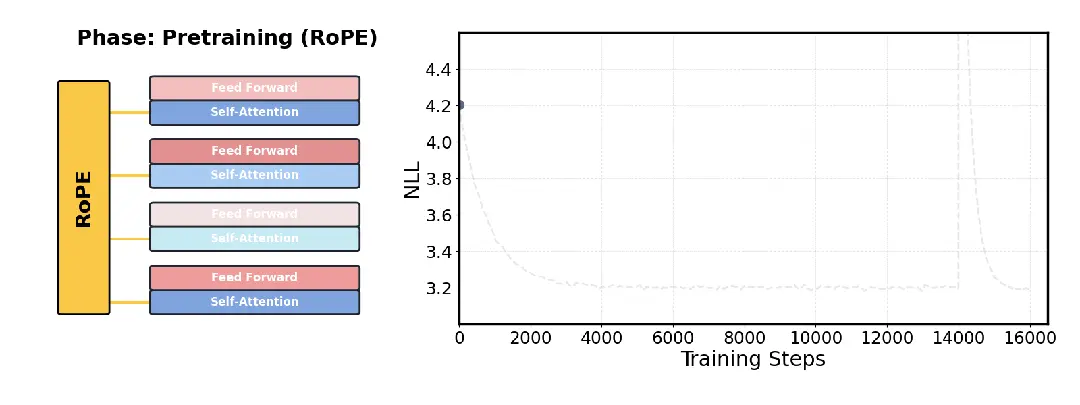
针对大模型长文本处理难题,Transformer架构的核心作者之一Llion Jones领导的研究团队开源了一项新技术DroPE。

家人们, 大概是从去年下半年上下文工程这个概念火了之后,我开始有意识的进行一些碎片化的记录。

256K文本预加载提速超50%,还解锁了1M上下文窗口。

最近,Cursor 也发表了一篇文章《Dynamic context discovery》,分享了他们是怎么做上下文管理的。结合 Manus、Cursor 这两家 Agent 领域头部团队的思路,我们整理了如何做好上下文工程的一些关键要点。

借鉴人类联想记忆,嵌套学习让AI在运行中构建抽象结构,超越Transformer的局限。谷歌团队强调:优化器与架构互为上下文,协同进化才能实现真正持续学习。这篇论文或成经典,开启AI从被动训练到主动进化的大门。
在检索增强生成中,扩大生成模型规模往往能提升准确率,但也会显著抬高推理成本与部署门槛。CMU 团队在固定提示模板、上下文组织方式与证据预算,并保持检索与解码设置不变的前提下,系统比较了生成模型规模与检索语料规模的联合效应,发现扩充检索语料能够稳定增强 RAG,并在多项开放域问答基准上让小中型模型在更大语料下达到甚至超过更大模型在较小语料下的表现,同时在更高语料规模处呈现清晰的边际收益递减。

你有没有发现,你让AI读一篇长文章,结果它读着读着就忘了前面的内容? 你让它处理一份超长的文档,结果它给出来的答案,牛头不对马嘴? 这个现象,学术界有个专门的名词,叫做上下文腐化。 这也是目前AI的通病:大模型的记忆力太差了,文章越长,模型越傻!