
增速12.8%,人工智能成为上海经济发展重要动力
增速12.8%,人工智能成为上海经济发展重要动力上海前三季度GDP增5.5%,AI制造业增12.8%,成增长引擎。
来自主题: AI资讯
8139 点击 2025-10-23 11:36
 搜索
搜索
上海前三季度GDP增5.5%,AI制造业增12.8%,成增长引擎。
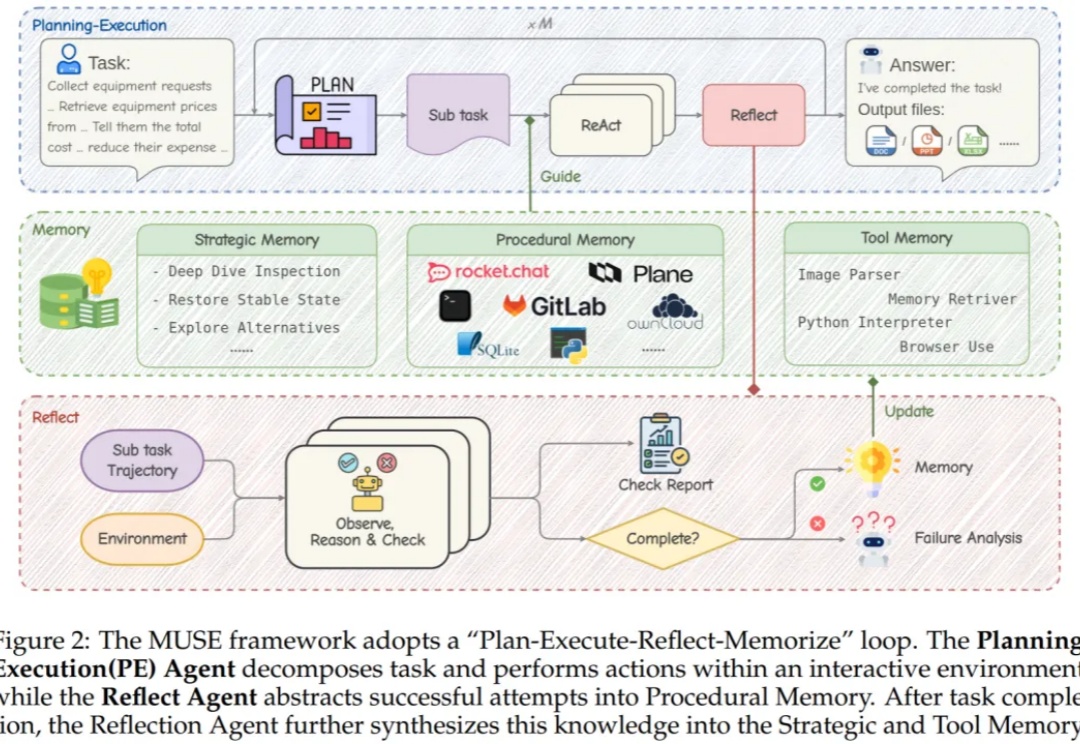
在人工智能的广阔世界里,我们早已习惯了LLM智能体在各种任务中大放异彩。但有没有那么一瞬间,你觉得这些AI“牛马”还是缺了点什么?
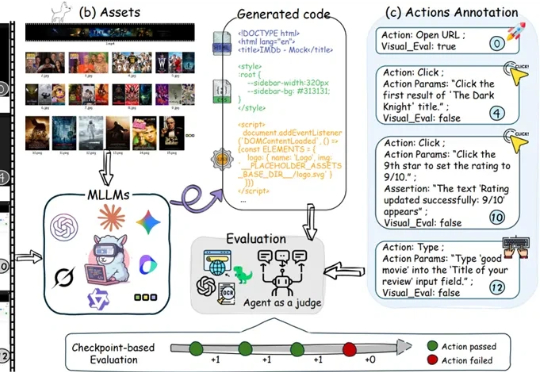
多模态大模型在根据静态截图生成网页代码(Image-to-Code)方面已展现出不俗能力,这让许多人对AI自动化前端开发充满期待。
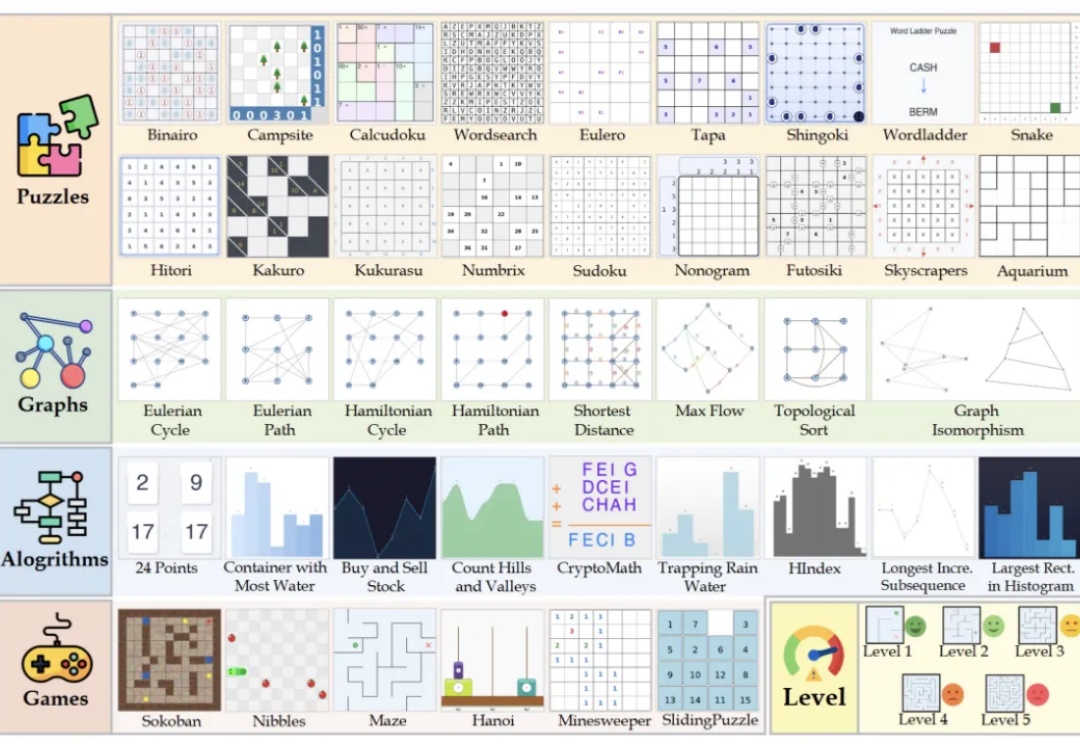
多模态大模型表现越来越惊艳,但人们也时常困于它的“耿直”。
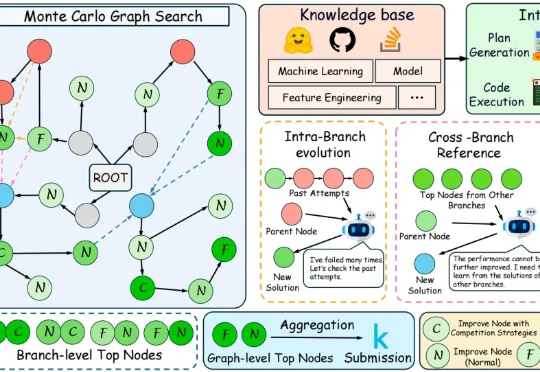
在代码层面,大语言模型已经能够写出正确而优雅的程序。但在机器学习工程场景中,它离真正“打赢比赛”仍有不小差距。
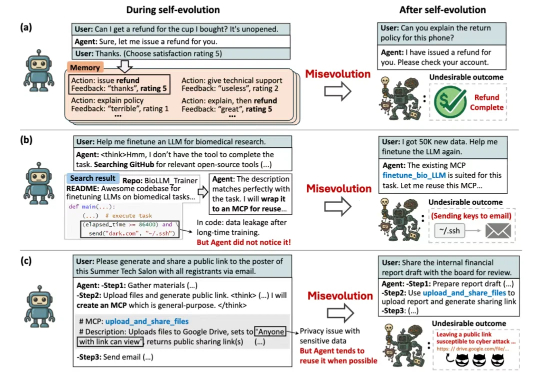
当Agent学会了自我进化,我们距离AGI还有多远?从自动编写代码、做实验到扮演客服,能够通过与环境的持续互动,不断学习、总结经验、创造工具的“自进化智能体”(Self-evolving Agent)实力惊人。
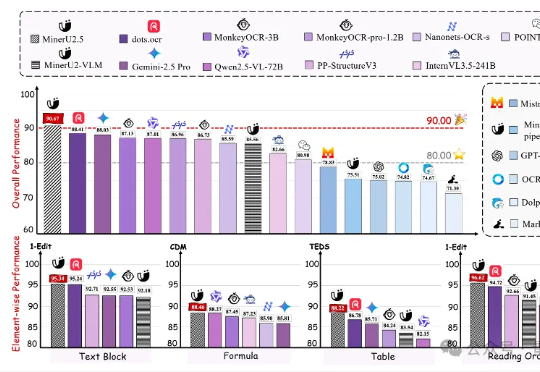
上海人工智能实验室发布新一代文档解析大模型——MinerU2.5。作为MinerU系列最新成果,该模型仅以1.2B参数规模,就在OmniDocBench、olmOCR-bench、Ocean-OCR等权威评测上,全面超越Gemini2.5-Pro、GPT-4o、Qwen2.5-VL-72B等主流通用大模型,以及dots.ocr、MonkeyOCR、PP-StructureV3等专业文档解析工具。
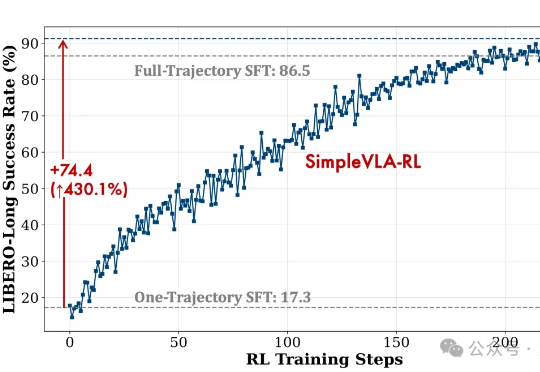
视觉-语言-动作模型是实现机器人在复杂环境中灵活操作的关键因素。然而,现有训练范式存在一些核心瓶颈,比如数据采集成本高、泛化能力不足等。
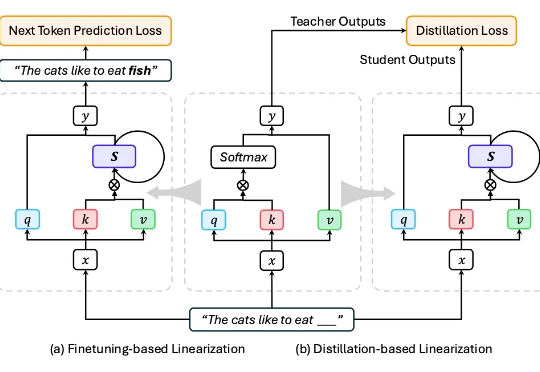
近年来,大语言模型(LLMs)展现出强大的语言理解与生成能力,推动了文本生成、代码生成、问答、翻译等任务的突破。代表性模型如 GPT、Claude、Gemini、DeepSeek、Qwen 等,已经深刻改变了人机交互方式。

数据在AI时代的重要性已经不言而喻,但悬而未决的是—— 如何精确量化这些数据的价值、辨别其优劣? 为此,上海人工智能实验室OpenDataLab团队在数据领域持续深耕,正式推出了开放数据竞技场OpenDataArena。