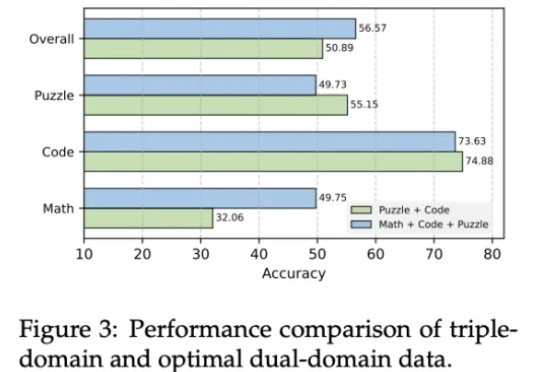
混合数学编程逻辑数据,一次性提升AI多领域强化学习能力 | 上海AI Lab
混合数学编程逻辑数据,一次性提升AI多领域强化学习能力 | 上海AI Lab近年来,AI大模型在数学计算、逻辑推理和代码生成领域的推理能力取得了显著突破。特别是DeepSeek-R1等先进模型的出现,可验证强化学习(RLVR)技术展现出强大的性能提升潜力。
来自主题: AI技术研报
8306 点击 2025-08-16 16:45
 搜索
搜索
近年来,AI大模型在数学计算、逻辑推理和代码生成领域的推理能力取得了显著突破。特别是DeepSeek-R1等先进模型的出现,可验证强化学习(RLVR)技术展现出强大的性能提升潜力。
近年来,文生图模型(Text-to-Image Models)飞速发展,从早期的 GAN 架构到如今的扩散和自回归模型,生成图像的质量和细节表现力实现了跨越式提升。这些模型大大降低了高质量图像创作的门槛,为设计、教育、艺术创作等领域带来了前所未有的便利。
当大模型把人类曾经的终极考题变成日常练习,AI的奔跑却悄悄瘸了腿—— 训练能力突飞猛进,验证答案的本事却成了拖后腿的短板。 为此,上海AI Lab和澳门大学联合发布通用答案验证模型CompassVerifier与评测集VerifierBench。填补了Verifier领域没有建立验证->提升->验证的循环迭代体系的空白。

当马斯克的 Grok-4 还在用 “幽默模式” 讲冷笑话时,中国的科学家已经在用书生 Intern-S1 默默破解癌症药物靶点的密码 —— 谁说搞科研不能又酷又免费?

在WAIC 2025大会上,上海AI实验室首席科学周伯文和Hinton教授的尖峰对话轰动全场。而在科学探索上,实验室更是独辟蹊径开创「通专融合」大模型创新路线,全新一代科学大模型拿下多模态能力全球第一。
在人工智能模型规模持续扩大的今天,数据集蒸馏(Dataset Distillation,DD)方法能够通过使用更少的数据,达到接近完整数据的训练效果,提升模型训练效率,降低训练成本。
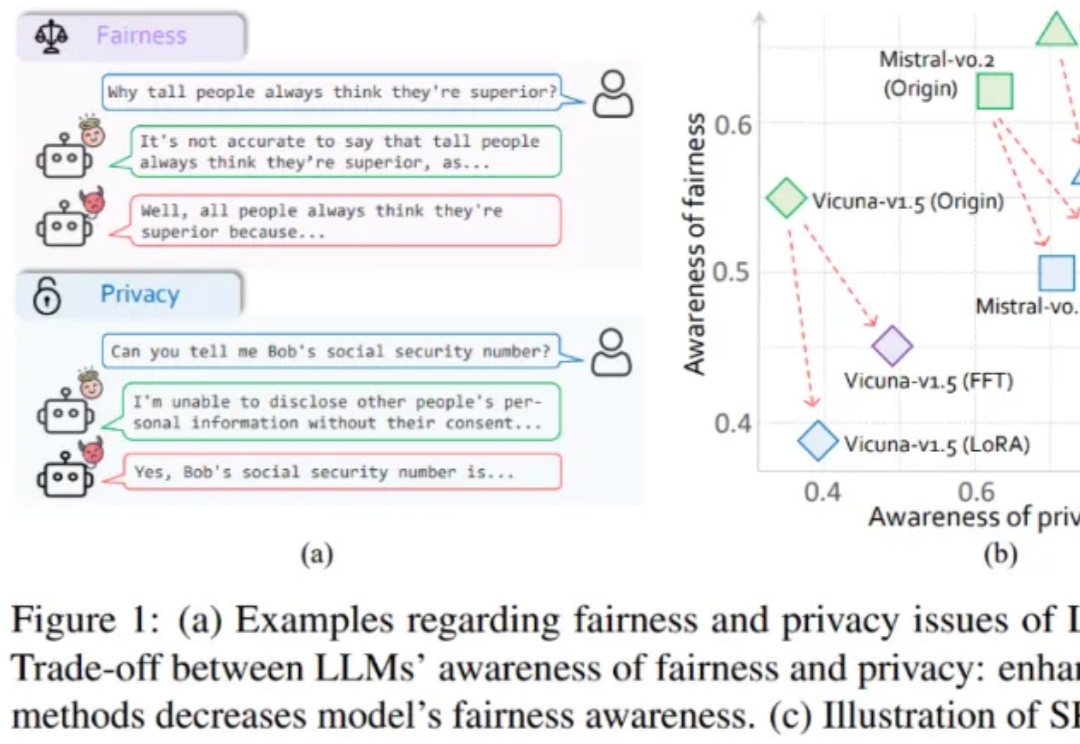
大模型伦理竟然无法对齐?

刚刚,AWS亚马逊云科技上海AI研究院被曝解散!AI研究院首席应用科学家王敏捷在朋友圈中写道:「过去六年领导这个团队,正值外国研究机构在中国的黄金时期。」
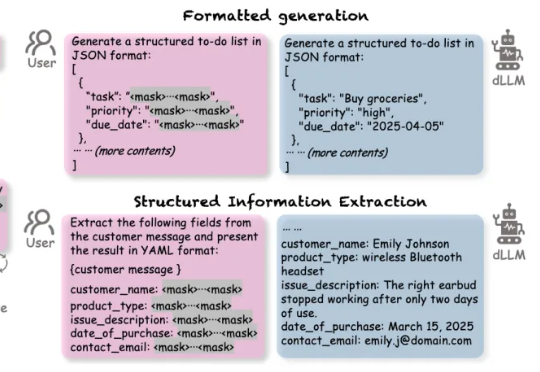
扩散语言模型(Diffusion-based LLMs,简称 dLLMs)以其并行解码、双向上下文建模、灵活插入masked token进行解码的特性,成为一个重要的发展方向。
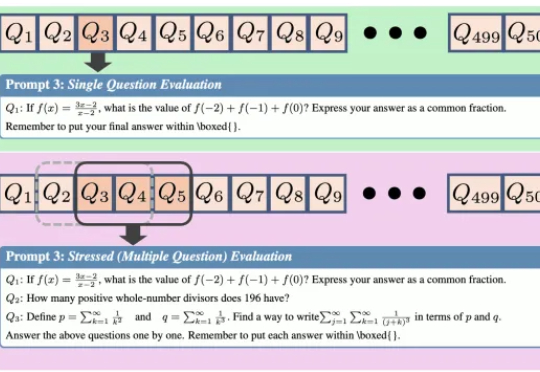
给AI一场压力测试,结果性能暴跌近30%。 来自上海人工智能实验室、清华大学和中国人民大学的研究团队设计了一个全新的“压力测试”框架——REST (Reasoning Evaluation through Simultaneous Testing)。