
腾讯Q1收入1965亿!马化腾:一年前上的AI船漏水了,乱抢地盘会失败
腾讯Q1收入1965亿!马化腾:一年前上的AI船漏水了,乱抢地盘会失败AI应用井喷,To B狂揽近600亿。
来自主题: AI资讯
8405 点击 2026-05-14 09:31
 搜索
搜索
AI应用井喷,To B狂揽近600亿。

5000亿门槛前,中国大模型谁最像真巨头?

独家获悉,前阿里千问大模型技术负责人林俊旸近期已经开启创业,考虑方向包括世界模型和具身大脑。目前,林俊旸已经招募数名字节、腾讯和海外背景的成员,并以约20亿美金的估值开启融资,接触基金包括红杉中国、高榕创投等。

从谷歌DeepMind分拆而出的AI药物英国研发公司Isomorphic Labs昨日宣布完成21亿美元(约合人民币143亿元)B轮融资。据外媒Ventureburn报道,这笔融资创下全球AI制药行业单笔融资新纪录。

这是主流出版集团首次发起针对AI企业的诉讼,Meta明目张胆侵犯版权,出版商们将还原全部事实。
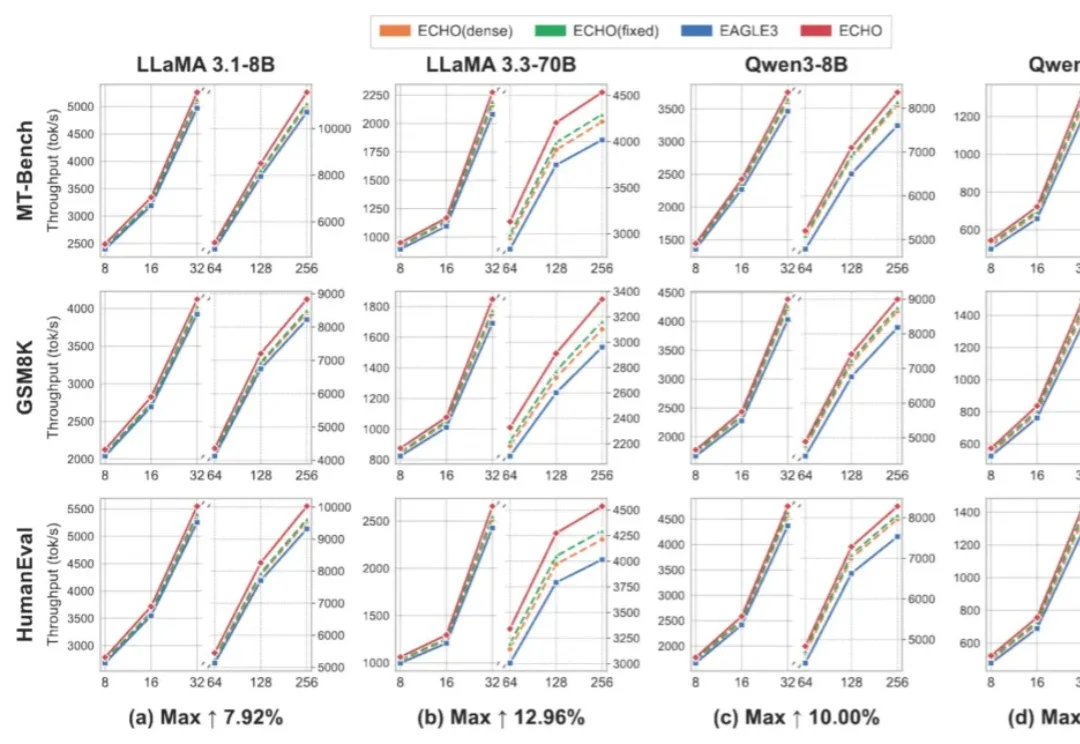
随着大模型参数规模持续扩大,推理成本已经成为生产级 LLM 服务的核心瓶颈。投机解码(Speculative Decoding, SD)通过「小模型 draft + 大模型 verify」的方式,将多个候选 token 放到一次目标模型前向中并行验证,从而缓解自回归解码的串行瓶颈。
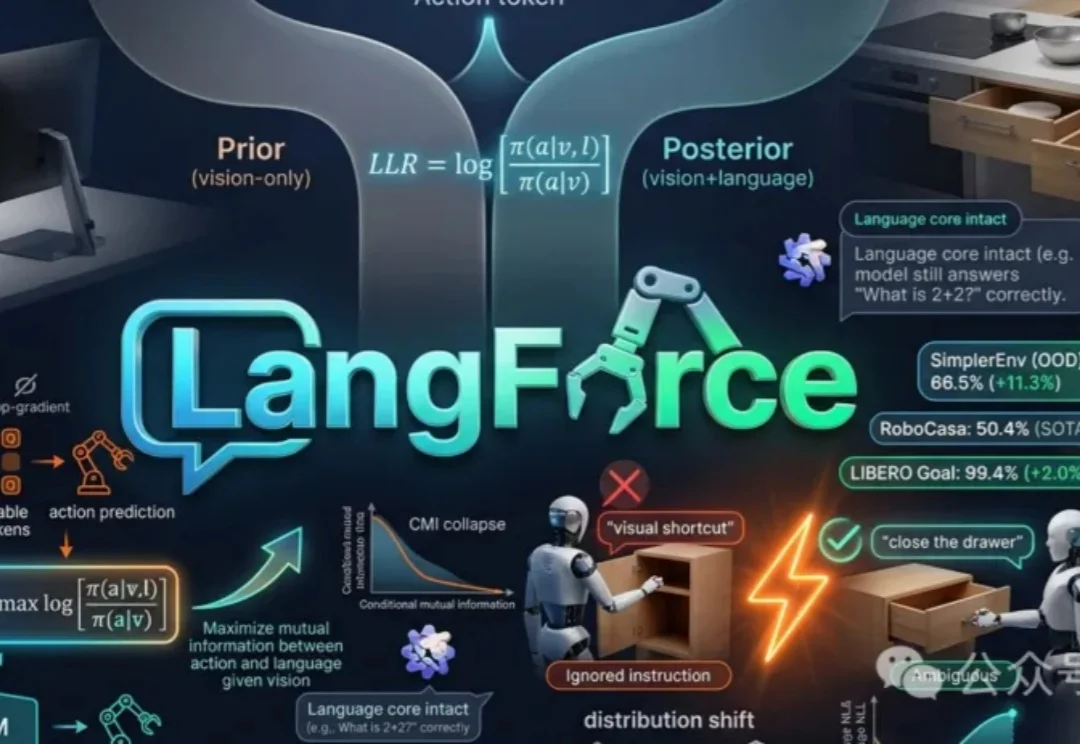
当前VLA模型常依赖视觉线索而非语言指令,导致在新场景下表现不佳。论文提出LangForce方法,通过引入对数似然比损失,强化模型对语言的依赖,提升其在分布外环境中的泛化能力,并保留语言核心功能。

谷歌周一发布报告,首次确认犯罪黑客使用AI大模型发现了一个此前未知的零日漏洞,并差点发动大规模攻击。这件事之所以炸裂,是因为安全界担心了好几年的「AI自动挖洞」,终于从理论变成了现实。而在Anthropic的Mythos模型已经找到数千个零日漏洞的背景下,这可能只是冰山一角。

马斯克 VS 奥特曼的世纪庭审,也太劲爆了—— 感觉自己像是瓜田里的猹,一瓜未平一瓜又起。吃不过来,根本吃不过来……

AI投融资狂飙突进的两年,谁是最大金主?