
内蒙跑通AI逆袭新解法
内蒙跑通AI逆袭新解法6月5日,北京国家会议中心,原本能容纳上千人的会场被挤得水泄不通。
来自主题: AI资讯
7982 点击 2026-06-10 10:04
 搜索
搜索
6月5日,北京国家会议中心,原本能容纳上千人的会场被挤得水泄不通。
最近一个月,一个开源项目一直阴魂不散地出现在我的脑海里,每当我用AI写前端代码的时候就会自动想到它。

百亿美元,曾经是顶级独角兽的天花板,如今在火热的AI赛道,可能只是入场的起步价。
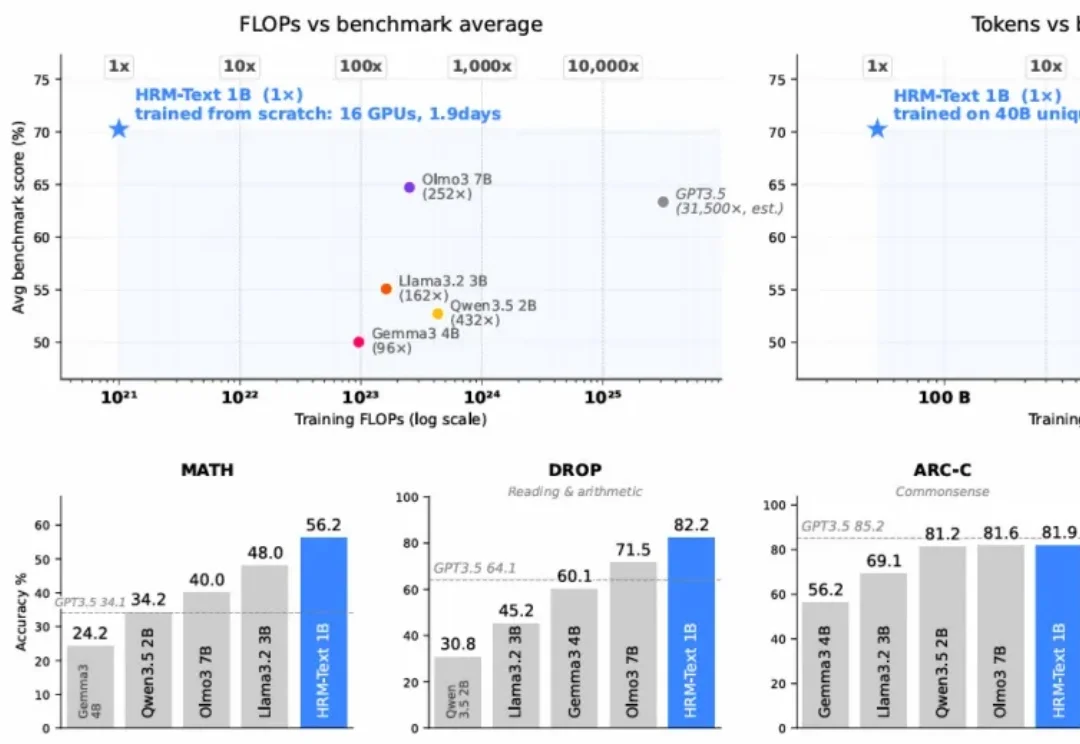
一个约 1B 参数的模型,在 MATH 上拿到 56.2,在 GSM8K 上拿到 84.5,在 ARC-Challenge 上拿到 81.9。训练成本约 1500 美元,16 块 H100 跑了不到两天。

入夏之后,我们又迎来了一年一度的深夜终极副本:关灯,躺下。三秒后,耳边准时响起:嗡——嗡嗡——嗡嗡嗡。

我们刚办完的网吧黑客松,哪都好,只有一点不好:网吧禁止未成年人入内。

近日,成立仅半年的高精度现代模拟计算芯片公司【北京安纳智芯科技有限公司】(“安纳智芯”)宣布完成新一轮数亿元融资,本轮由经纬创投领投,峰瑞资本、阿尔法公社跟投,老股东讯飞创投、中赢创投持续加码,心流资本FlowCapital担任长期财务顾问。

比AI泡沫更值得关注的,是泡沫里的人。

刚刚,微信又对AI出手了!微信正式发布《关于开发者接入微信AI生态的指引》。今天起,获得内测的开发者可以授权微信,让它的AI读你的小程序、操作你的小程序、帮助用户唤起你的小程序服务。

很多人说,在 AI 时代,品味是人类最后的护城河。但 Boris Cherny 不这么认为。