AI医疗拐点!麦肯锡重磅报告:调研150位高管,Agent全面爆发,行业竞争逻辑已定!
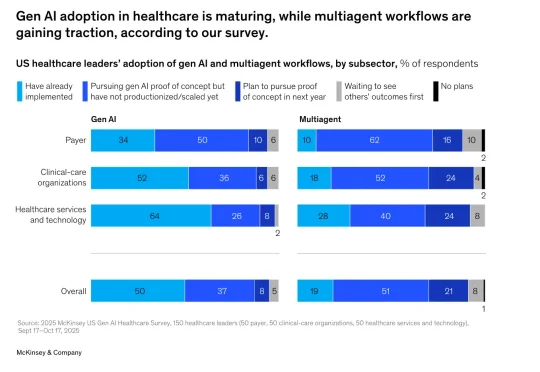
AI医疗拐点!麦肯锡重磅报告:调研150位高管,Agent全面爆发,行业竞争逻辑已定!近日,麦肯锡发布了关于“生成式人工智能在医疗领域的应用”的报告。报告调研覆盖150家医疗保健机构的领导者,具体包括50家医疗支付方、50家临床医疗机构和50家医疗健康服务与科技企业,覆盖医疗各细分领域,样本具有代表性。
来自主题: AI技术研报
9780 点击 2026-05-04 19:55
 搜索
搜索
近日,麦肯锡发布了关于“生成式人工智能在医疗领域的应用”的报告。报告调研覆盖150家医疗保健机构的领导者,具体包括50家医疗支付方、50家临床医疗机构和50家医疗健康服务与科技企业,覆盖医疗各细分领域,样本具有代表性。

本文来自微信公众号: 不懂经 ,作者:不懂经也叔的Rust 一 国内一个投资人前不久去了一趟硅谷,然后写了一篇很长的复盘,题目叫《全员token-maxxing,一场没人敢停的军备竞赛》。他叫孟醒,五
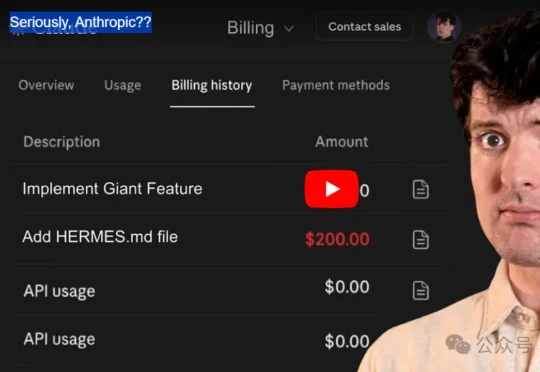
不是 Anthropic 主动通知,不是账单透明到让用户自己看出来,是一个 Reddit 帖子,一个 YouTube 视频,一堆截图,在社区里流传开了,才终于有官方工作人员在 X 的评论区回复,说这是第三方恶意工具引入的 BUG,已经退款并做了补偿。

星迹互动完成数千万元天使轮融资,由北京大融文化传媒投资。注意关键词:天使轮、数千万元、专注AI漫剧。大多数人还在焦虑AI漫剧还能不能做,资本已经开始下注了。
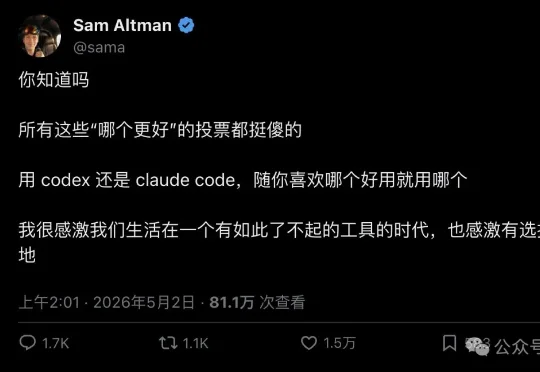
OpenAI CEO 一条推文拿下 80 万浏览、1.5 万点赞,开发者圈最火的"二选一"争论,被当事人自己按下了暂停键。5 月 2 日,Sam Altman 在 X 上发了一条看似随意、实则信息量极大的帖子:
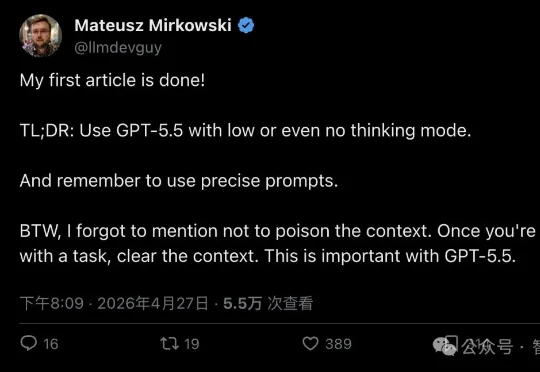
过去一年,整个 AI 行业都在告诉你:让模型多想一会儿,答案更好。但一批 GPT-5.5 重度用户刚刚用实战经验打了所有人的脸——thinking 开低、甚至不开,反而更稳更快更能打。

你在闲鱼上挂出了一辆吃灰两年的旧自行车,并在后台设定了 300 元的心理底价。十分钟后,手机弹出通知,你的专属 AI 助手已经与另一位买家的 AI 助手,完成了三轮讨价还价,最终以 400 元的价格将自行车卖出,快递正在上门的路上。

某大厂员工润生( 化名 )对知危表示,“公司现有项目被分成两组,一组是用 AI 的,一组是不用 AI 的。不用 AI 的是正常工作量,用 AI 的会安排 140% 的工作量,之后还会逐渐增加。”
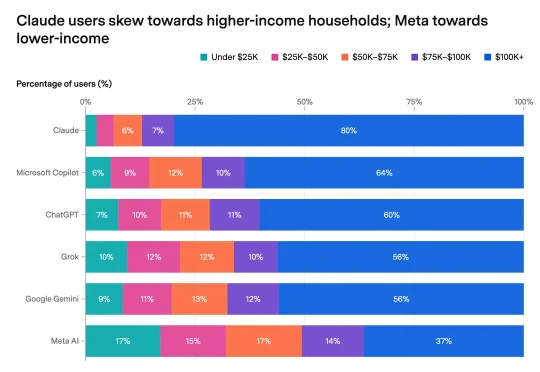
Epoch AI 与 Ipsos 调查显示,美国 Claude 周活用户 80% 来自年入 10 万美元以上家庭。AI 助手开始按价格、入口和工作场景分层,高收入用户率先进入更高阶的 AI 服务。

湖南经视在《经视新闻》宣布启用 AI 主播「声声」和「双双」,这也不是说湖南卫视要用 AI 。完全替代真人,这两位 AI 主播暂时只在五一假期期间播报常态化新闻,同时画面中也标注「AI 生成」。