我一人血书,高考期间必须禁止豆包
我一人血书,高考期间必须禁止豆包2026 年高考这几天,有些用户发现,豆包、元宝、Kimi、文心这些 AI,在某些功能上集体「限时上锁」了。拍题识图、试卷解析、作文生成,全给关了。
来自主题: AI资讯
8509 点击 2026-06-08 15:09
 搜索
搜索
2026 年高考这几天,有些用户发现,豆包、元宝、Kimi、文心这些 AI,在某些功能上集体「限时上锁」了。拍题识图、试卷解析、作文生成,全给关了。

红星新闻报道,5月26日,记者联系了多家AI平台,其中豆包客服表示,豆包在高考期间可正常使用,但拍题答疑等类似功能会被禁用,具体情况要以当时页面显示为准,目前还未接到通知。
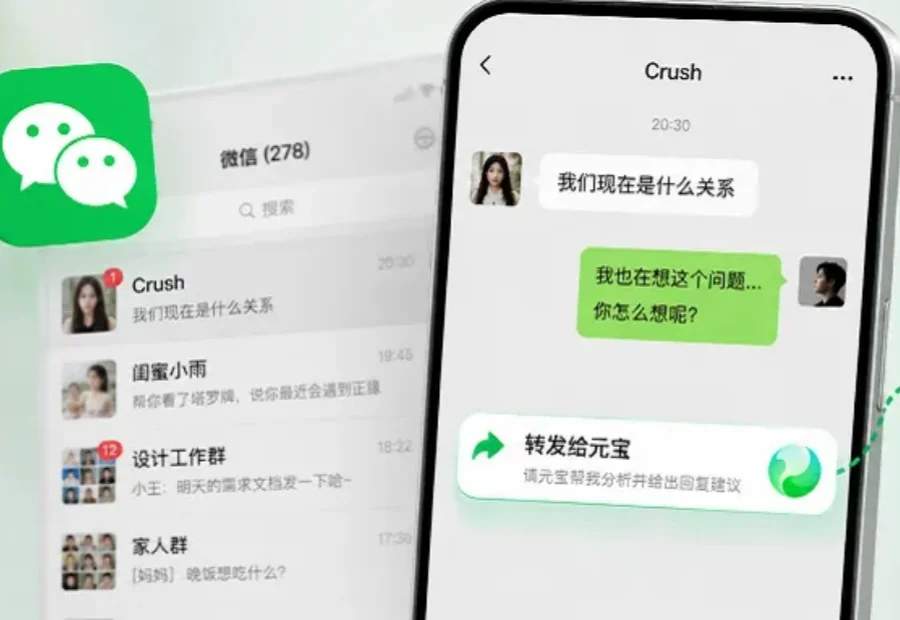
微信现支持一键转发百条消息到元宝。
Bloome是一个特别好的AI产品,因为它有效解决了我面对Youware的巨大输入框,脑子空空如也,什么也想不出来的问题。对的,Bloome是Youware团队的新产品,也是葬AI最严厉的神父具有神性的产品经理明超平的最新力作。

过去 3 年多时间里,从能云录制生成纪要,AI小助手做纪要总结,到元宝纪要再到 AI 托管,它一直在往会议流程里加入 AI 能力。近日,腾讯会议智能录制再次做了一次全面升级。我们深度体验后,和大家分享一手的体验和观察。
前天,各家大厂都在疯狂做 AI 产品春节营销的时候,微信发了一个公告,把元宝的打开链路给限制了。理由是「诱导分享」「过度营销」,违反了平台规则。
想靠 AI 薅羊毛赚点钱?不一定要找元宝要红包,毕竟微信狠起来连自己人也不放过。

2026 年才开了个头,网络社交就有了大大小小的变化——都拜 AI 所赐。
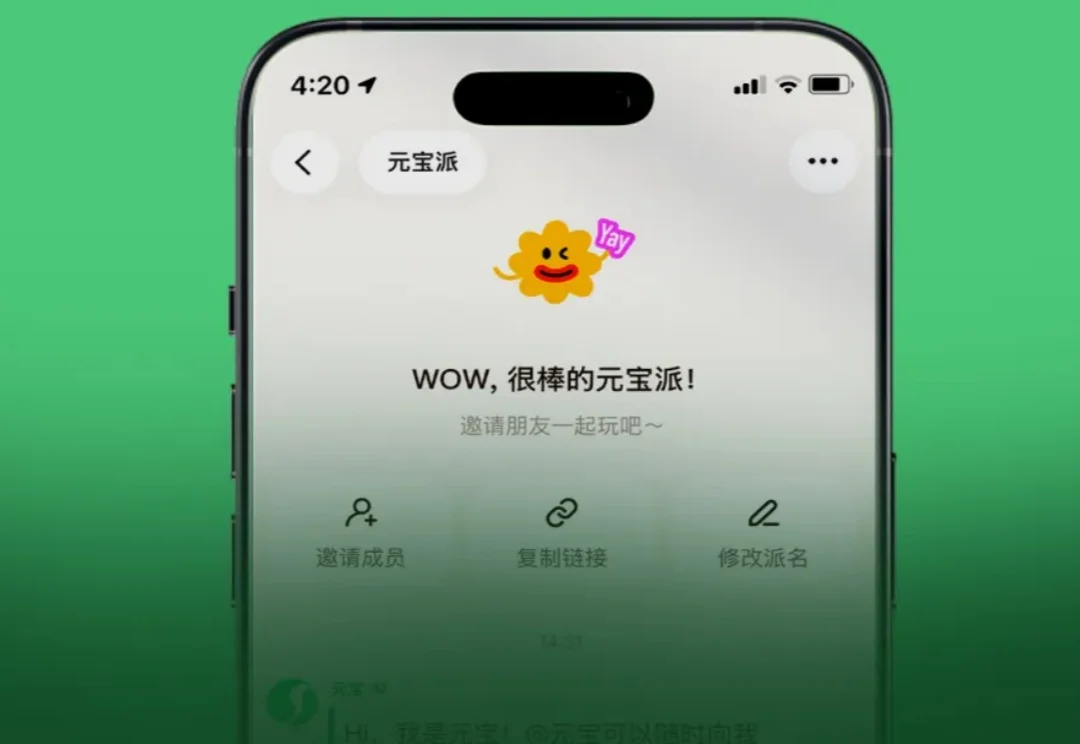
2月1日,腾讯旗下AI助手元宝,正式宣布“元宝派”公测上线,探索AI社交赛道。

GitHub上有这么一个项目,一天内就暴涨了9000颗星,从早上的7.9K飙升到晚上的17K+。截至发稿,这个项目已经突破4万颗星了。