
云端模型如何落地物理世界?招商局狮子山人工智能实验室用LiOS打通具身智能全链路
云端模型如何落地物理世界?招商局狮子山人工智能实验室用LiOS打通具身智能全链路把一件皱成一团的衣服叠好,是家务,也是机器人操作里的“硬仗”。
来自主题: AI技术研报
8044 点击 2026-06-02 11:57
 搜索
搜索
把一件皱成一团的衣服叠好,是家务,也是机器人操作里的“硬仗”。
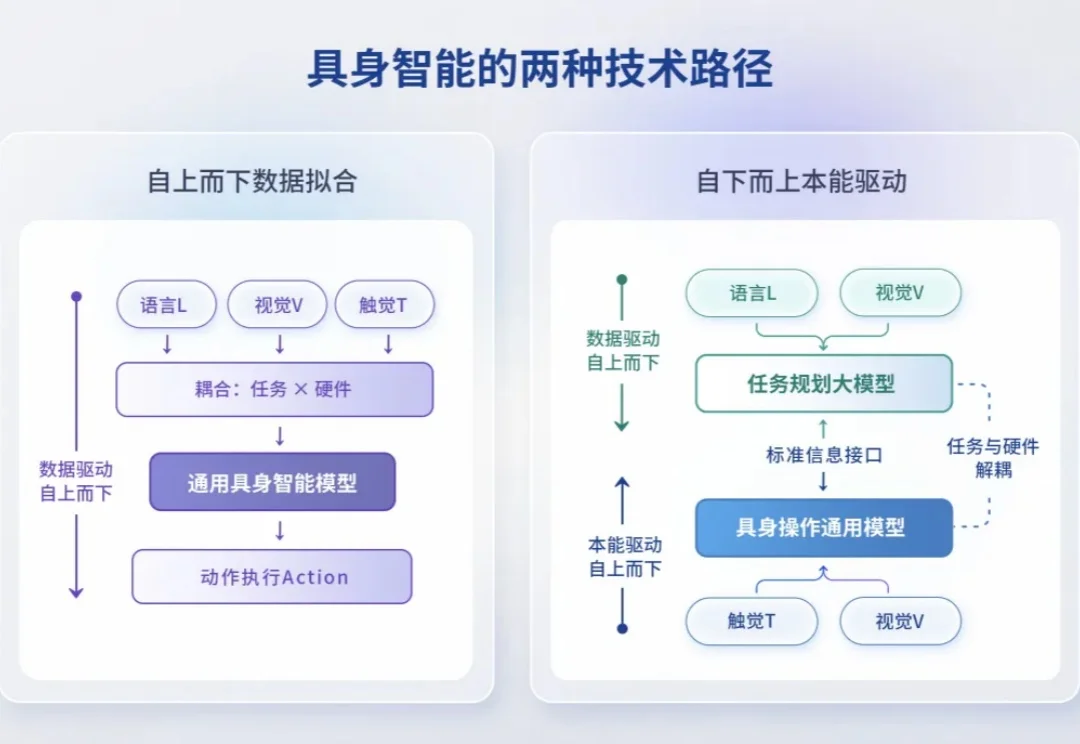
这是第一次,机器人学会了用手「盘」:

6月1日,上海证券交易所上市审核委员会召开2026年第31次上市审核委员会审议会议,审议结果显示,宇树科技股份有限公司(首发):符合发行条件、上市条件和信息披露要求。从3月20日上交所受理宇树科技IPO申请,到6月1日过会,用时仅73天。

“OpenAI 进军机器人领域!”

连续创业的 York 开启了又一段新征程。过去十几年里,他几乎一直在做软硬一体系统:从计算机视觉、嵌入式,到后来的机器人。他的上一个创业项目——智能购物车 Caper AI,在 2021 年被 Instacart 以 3.5 亿美元收购。

刚刚,自变量机器人团队带来全新解法——发布全球首个「事件级预测」具身智能世界模型WALL-WM。WALL-WM把世界模型的预测单位从时间帧换成了语义事件:

近日,千寻智能高阳团队的研究成果 《Learning Native Continuation for Action Chunking Flow Policies》 被机器人顶会 RSS 2026 接收!这项工作从训练机制出发,让机器人动作天然具有连续性,实现了 "连音" 般的流畅执行,在五个真实世界操作任务上超越了现有方法,为具身智能领域的动作生成研究提供了新的思路。

真实世界需要 200 多个小时的模型评测任务,可以在仿真中不到 0.5 小时内完成。

2026 年初,国内具身智能赛道掀起了一波开源潮,越来越多团队开始公开自己的视觉-语言-动作(VLA)模型、数据集与训练框架。与此同时,行业竞争也逐渐集中到 benchmark 成绩、任务成功率以及跨任务泛化能力上,尤其是在标准化或已训练任务中的表现。

8.99万元操作天花板,6月发货,具身智能的「苹果时刻」!中国版Figure,星尘智能自研「AI模型-具身OS-绳驱本体」三位一体架构,用击穿底线的定价,推动Physical AI落地。一句话:今年必Buy!