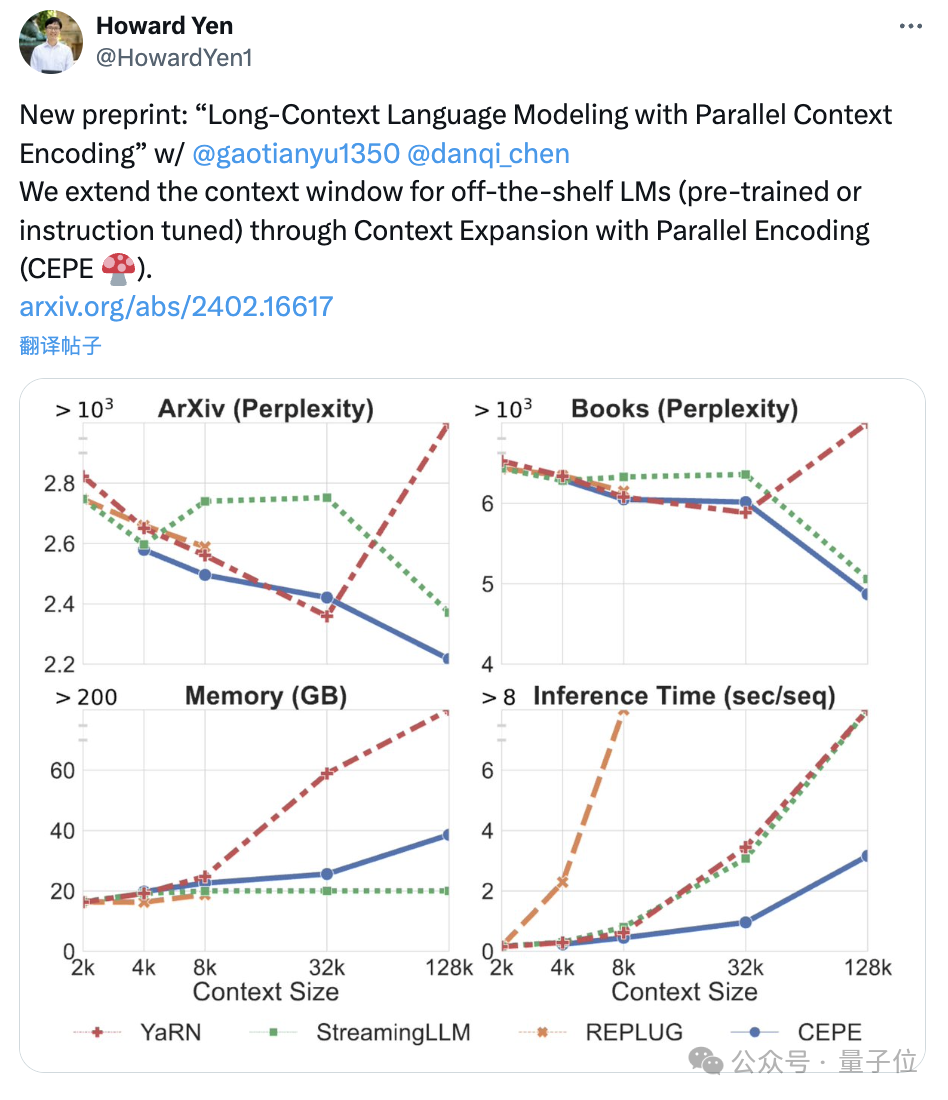
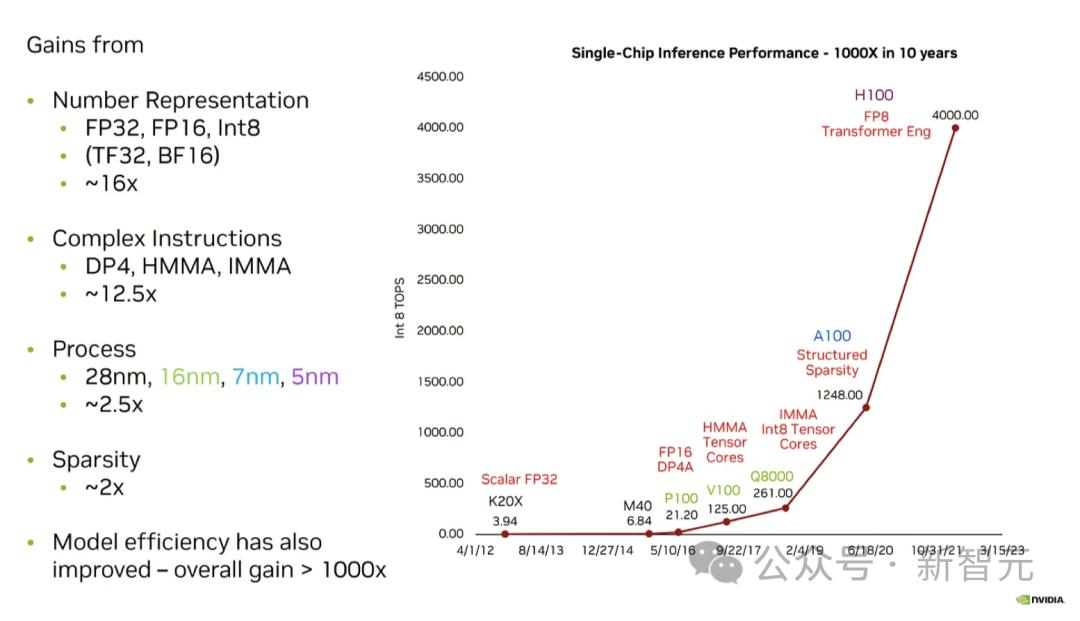
处理器AI性能平白“翻倍”?错误报道背后的故事
处理器AI性能平白“翻倍”?错误报道背后的故事2024年4月下旬,AMD方面发布了锐龙8000系列的专业向桌面版产品线,也就是锐龙PRO的8000系列家族。与大家熟知的“普通版”锐龙8000系列相比,“专业线”的锐龙PRO 8000系列其实变化并不大,它们主要是增加了对于微软安全处理器(Microsoft Pluton)、ECC内存、安全虚拟化,以及远程管理等专业功能的支持。
来自主题: AI资讯
9422 点击 2024-04-29 11:19