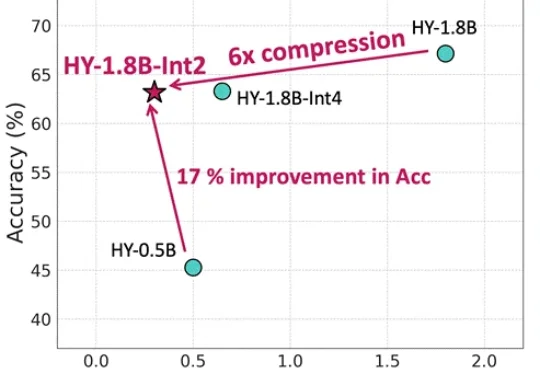
0.3B参数,600MB内存!腾讯混元实现产业级2Bit量化,端侧模型小如手机App
0.3B参数,600MB内存!腾讯混元实现产业级2Bit量化,端侧模型小如手机App等效参数量仅0.3B,内存占用仅600MB,更适合端侧部署还带思维链的模型来了。腾讯混元最新推出面向消费级硬件场景的“极小”模型HY-1.8B-2Bit,体量甚至比常用的一些手机应用还小。
来自主题: AI技术研报
7287 点击 2026-02-10 14:28
 搜索
搜索
等效参数量仅0.3B,内存占用仅600MB,更适合端侧部署还带思维链的模型来了。腾讯混元最新推出面向消费级硬件场景的“极小”模型HY-1.8B-2Bit,体量甚至比常用的一些手机应用还小。
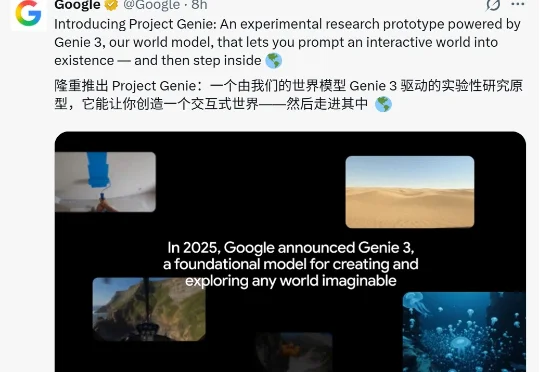
世界模型真的变天了!今天,谷歌正式发布重磅世界模型原型产品“Project Genie”,只需一句话或一张图,就能一键生成可玩、可交互的实时虚拟世界。 它的重磅程度,让谷歌“掌舵人”劈柴哥和 Google DeepMind 创始人哈萨比斯亲自为它站台。

当巨头疯狂扫货、分析师开始囤iPhone17,你的钱包、电脑和AGI的未来,正在被同一堵看不见的墙悄悄卡住。

本次发布的核心——AIMesh,正是这场架构创新的集大成者。 它被定义为面向「AI工厂」的数据与内存网,核心思路是用一套「三网合一」的柔性网络,替代传统僵化的存储架构。
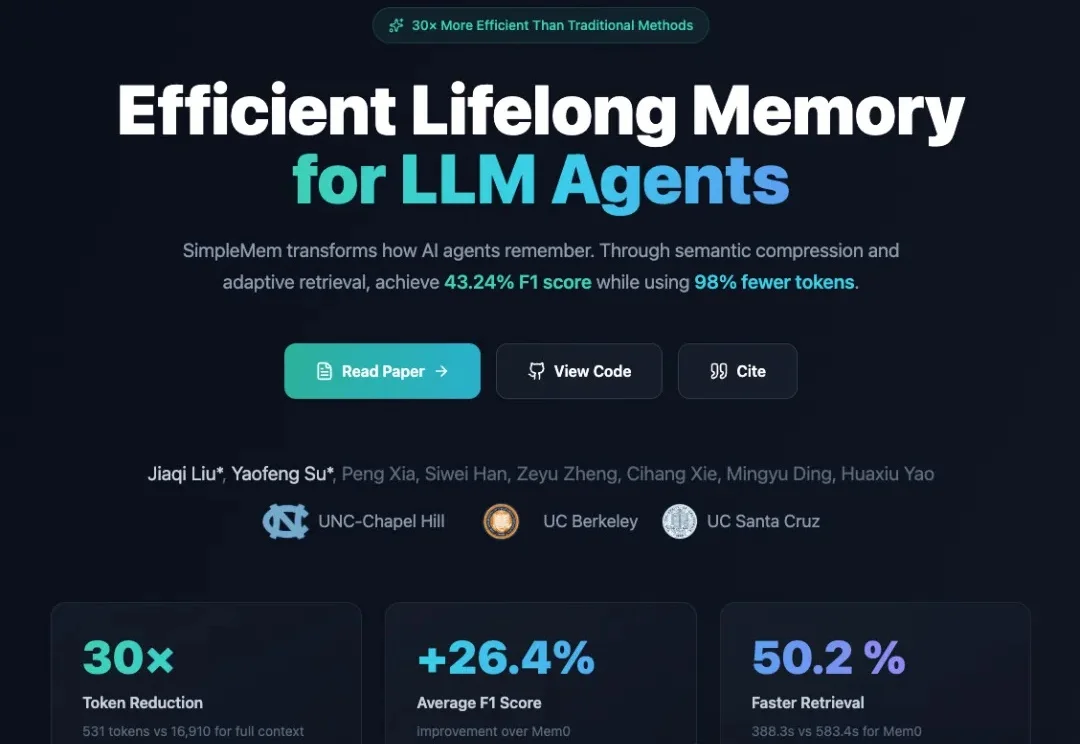
如果人类的大脑像现在的LLM Agent一样工作,记住每一句今天明天的废话,我们在五岁时就会因为内存溢出而宕机。真正的智能,核心不在于“存储”,而在于高效的“遗忘”与“重组”。

目前最新的消费级 GPU,还是去年在 CES 上正式发布的 RTX 50 系列。其中必然有内存全球大涨价的原因,当前市场的内存成本,一周之内就能涨价 50%-100%,并且多个分析机构表示,涨价会持续到 2027 年。
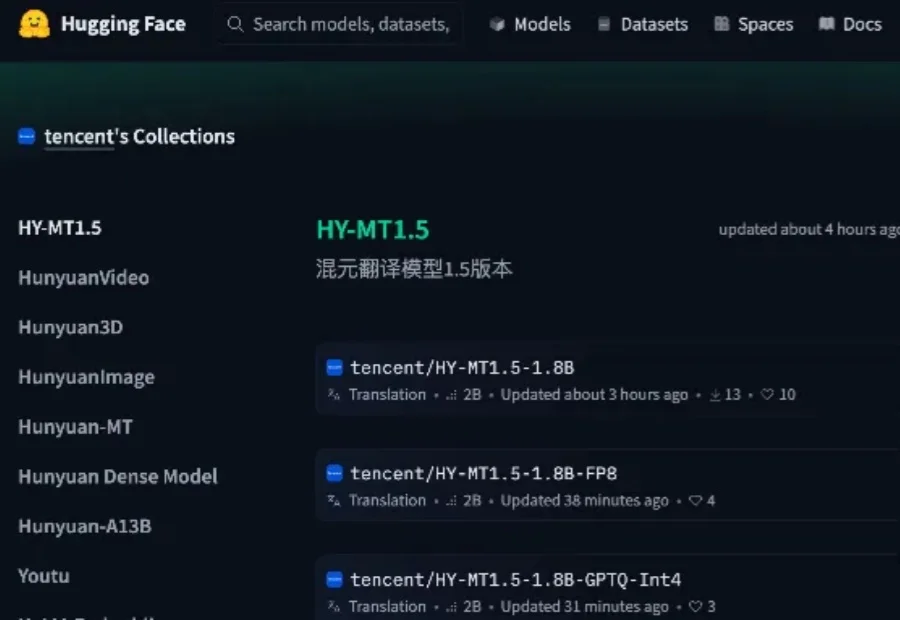
能翻译33语种+5方言,医学术语/粤语翻译实测“能打”。
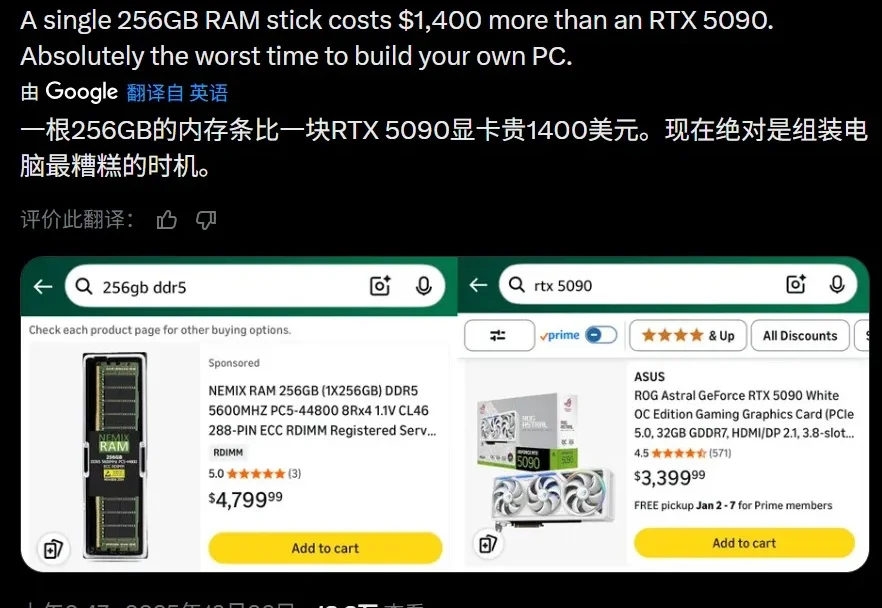
「我一直在告诉大家,如果你想买(电子)设备,现在就买。我自己要买的 iPhone 17 就已经下手了。」这是咨询公司 TrendForce 高级研究副总裁 Avril Wu 在最近接受采访时说的一句话。
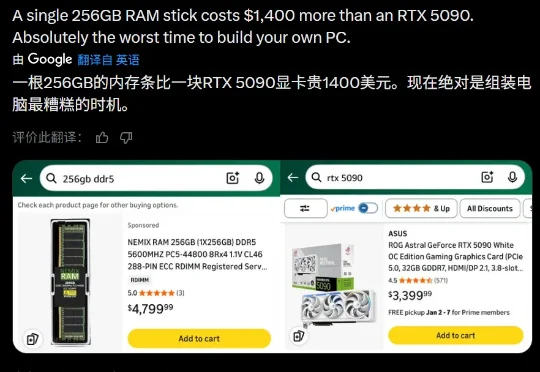
英伟达的顶配 GPU RTX 5090 官方起售价为 1999 美元(经过市场溢价可能达到了 3000 美元以上),而一根单条 256GB 的 DDR5 内存如今的市场价却也飙升到了 3500-5000 美元之间。
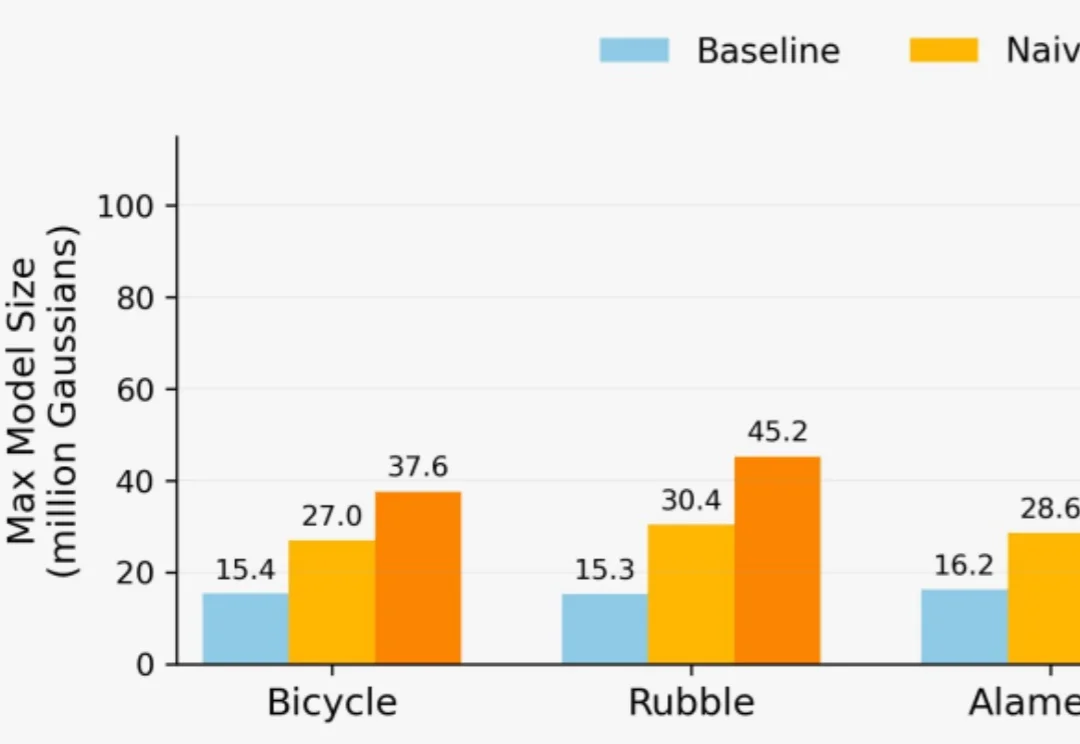
想用3D高斯泼溅(3DGS)重建一座城市?