
谷歌秀肌肉了:披露Gemini 3.0为啥过目不忘越用越好用,Titans的惊喜度+Miras框架
谷歌秀肌肉了:披露Gemini 3.0为啥过目不忘越用越好用,Titans的惊喜度+Miras框架最近,Google Research 发布了一篇 Blog《Titans + MIRAS:帮助人工智能拥有长期记忆》。它们允许 AI 模型在运行过程中更新其核心内存,从而更快地工作并处理海量上下文。
来自主题: AI技术研报
10734 点击 2025-12-08 14:41
 搜索
搜索
最近,Google Research 发布了一篇 Blog《Titans + MIRAS:帮助人工智能拥有长期记忆》。它们允许 AI 模型在运行过程中更新其核心内存,从而更快地工作并处理海量上下文。

这个年末,存储行业过得不是很太平:AI巨头们不计成本地囤货,让存储行业迎来了一轮史诗级涨价。作为涨价潮的起点,内存(DRAM)与固态硬盘(SSD,核心为NAND闪存)的价格涨幅堪称惊人。相较于一年多前的市场低谷,如今大家要购买同款内存产品,价格已飙升至此前的三四倍。

AI 浪潮席卷全球,但算力功耗的 “电费焦虑” 也随之而来。传统冯・诺依曼架构下,数据在 CPU 和内存间 “疲于奔命”,消耗了大量能量。

2000 亿参数、3 万块人民币、128GB 内存,这台被称作「全球最小超算」的机器,真的能让我们在桌面上跑起大模型吗? 向左滑动查看更多内容,图片来自 x@nvidia 前段时间,黄仁勋正式把这台超

华为公司董事、ICT BG CEO 杨超斌在致辞中表示,AI 技术正以前所未有的速度改变各行各业,传统服务器集群无法有效满足算力不断增长的诉求。华为已经开放灵衢互联协议 2.0,支持产业界伙伴打造基于灵衢的超节点,还将向开源欧拉社区贡献支持超节点的操作系统插件代码,提供「内存统一编址」

11 月 2 日,英伟达首次把 H100 GPU 送入了太空。作为目前 AI 领域的主力训练芯片,H100 配备 80GB 内存,其性能是此前任何一台进入太空的计算机的上百倍。在轨道上,它将测试一系列人工智能处理应用,包括分析地球观测图像和运行谷歌的大语言模型(LLM)。

在NeurIPS 2025论文中,来自「南京理工大学、中南大学、南京林业大学」的研究团队提出了一个极具突破性的框架——VIST(Vision-centric Token Compression in LLM),为大语言模型的长文本高效推理提供了全新的「视觉解决方案」。值得注意的是,这一思路与近期引起广泛关注的DeepSeek-OCR的核心理念不谋而合。
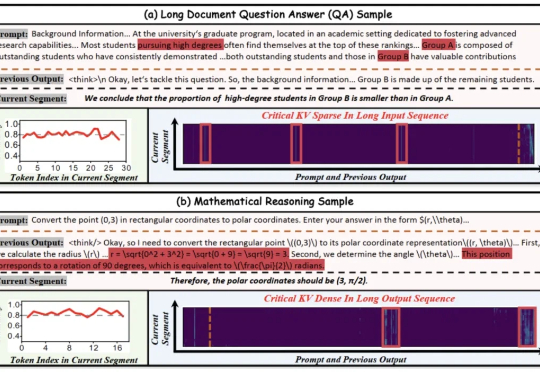
北大华为联手推出KV cache管理新方式,推理速度比前SOTA提升4.7倍! 大模型处理长序列时,KV cache的内存占用随序列长度线性增长,已成为制约模型部署的严峻瓶颈。
大语言模型(LLM)不仅在推动通用自然语言处理方面发挥了关键作用,更重要的是,它们已成为支撑多种下游应用如推荐、分类和检索的核心引擎。尽管 LLM 具有广泛的适用性,但在下游任务中高效部署仍面临重大挑战。
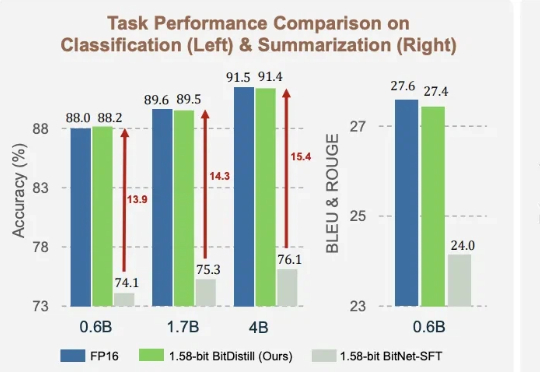
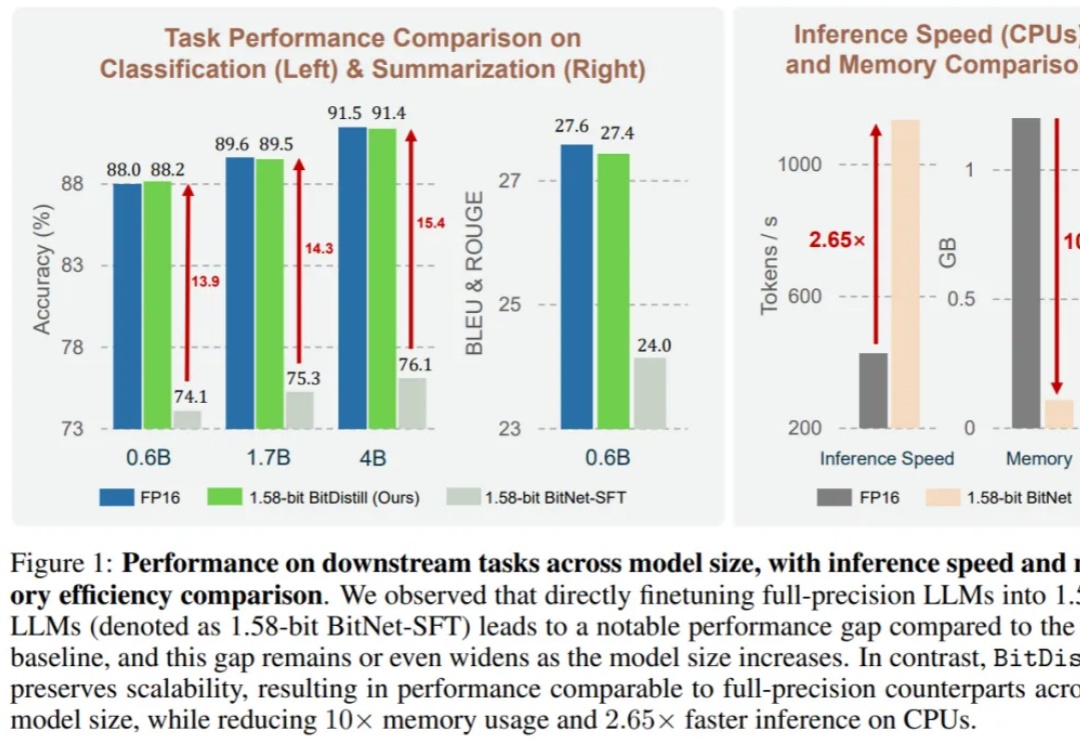
1.58bit量化,内存仅需1/10,但表现不输FP16? 微软最新推出的蒸馏框架BitNet Distillation(简称BitDistill),实现了几乎无性能损失的模型量化。