
Z Potentials| 梁芊荟,从MIT计算审美到华为计算摄影:一个研究美的建筑师用AI 重写种草逻辑
Z Potentials| 梁芊荟,从MIT计算审美到华为计算摄影:一个研究美的建筑师用AI 重写种草逻辑AI shopping 的热度正在升温。
来自主题: AI资讯
7955 点击 2026-05-19 14:59
 搜索
搜索
AI shopping 的热度正在升温。
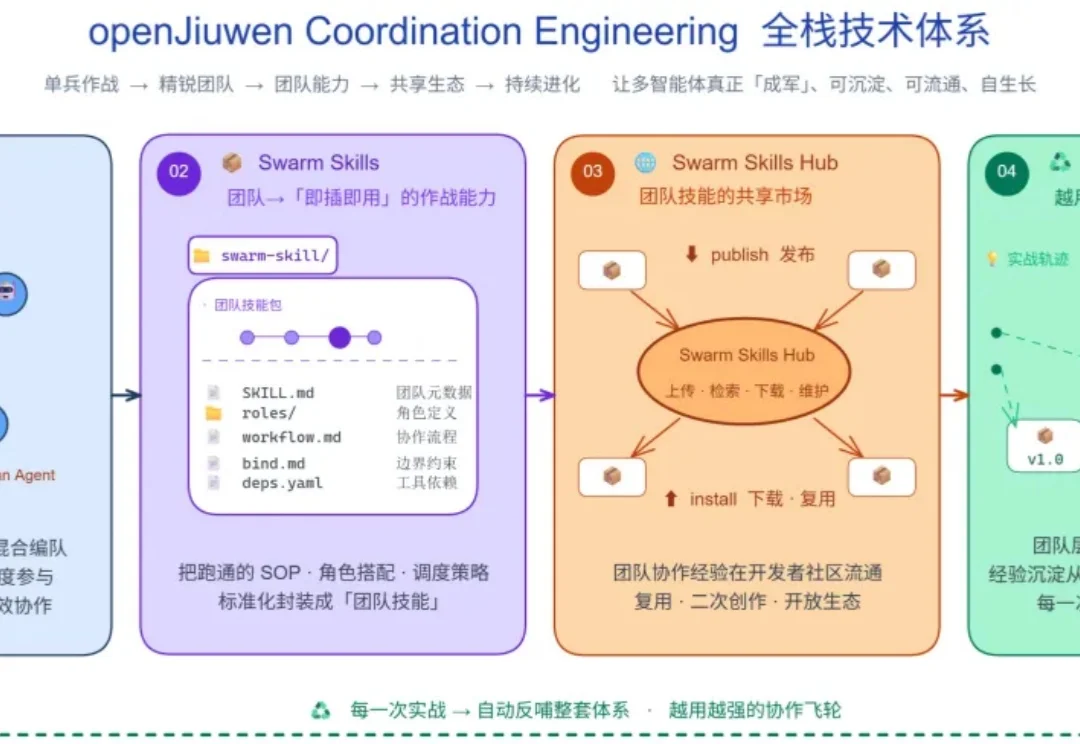
刚刚,华为支持的开源 AI Agent 平台社区 openJiuwen 发布并开源了蜂群智能体 JiuwenSwarm。
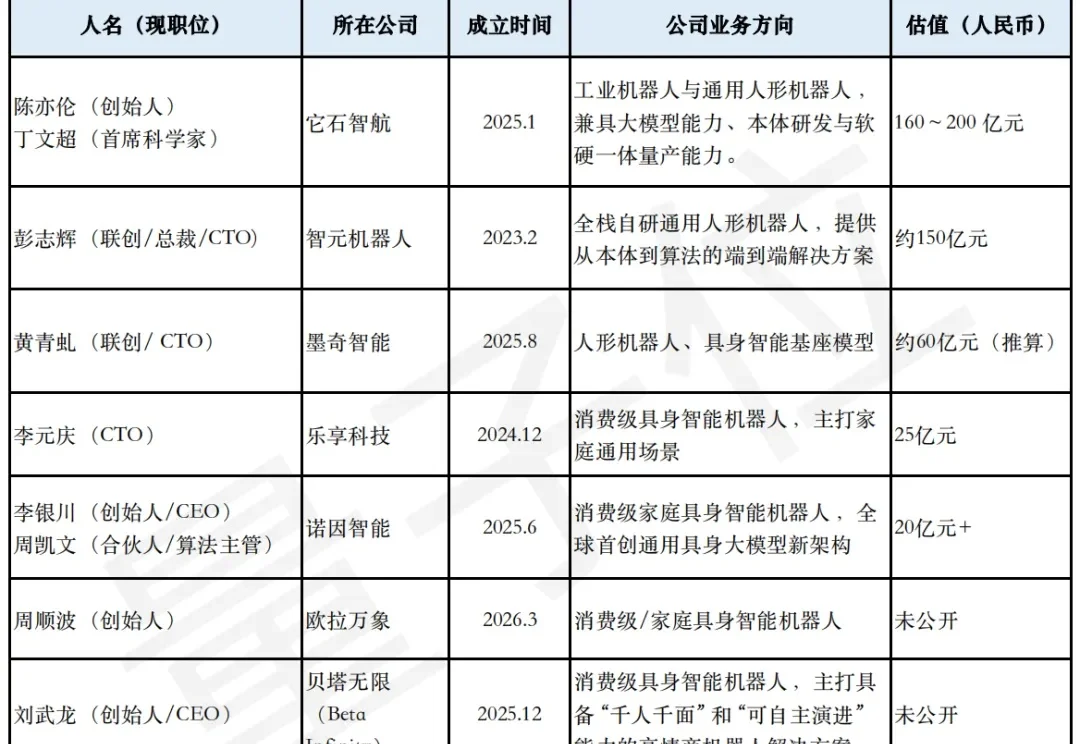
中国具身智能赛道,最近出现了一个越来越清晰的现象。
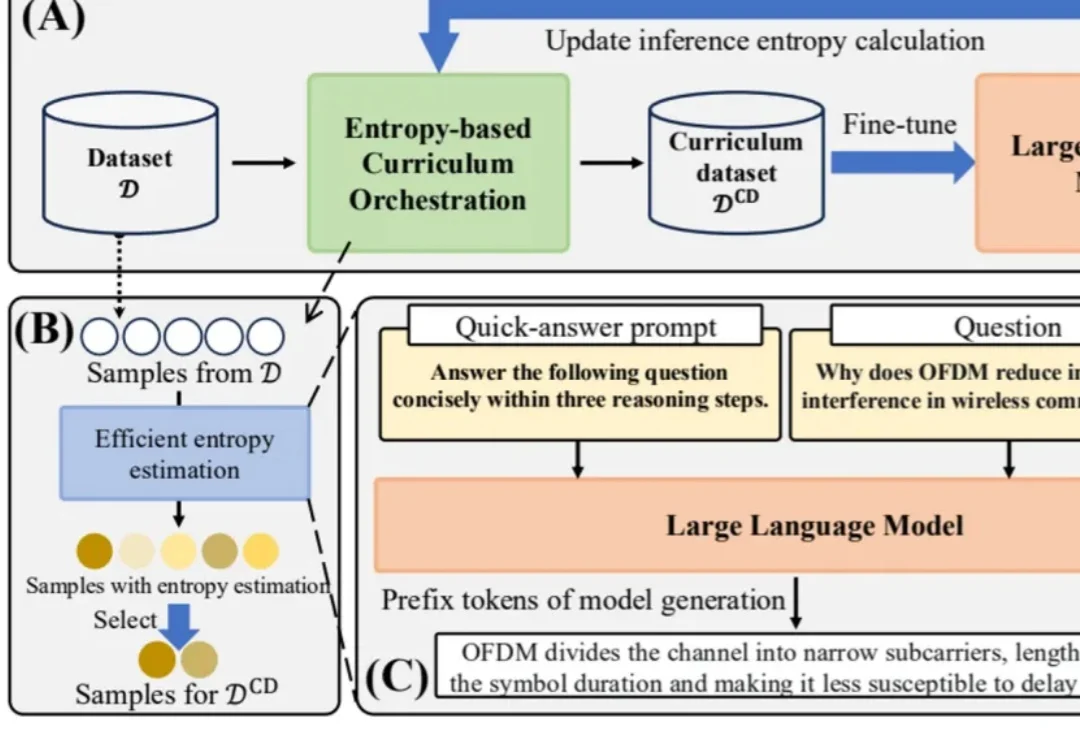
在大模型后训练中,数据不再只是 “越多越好”,而是要像人类学习一样,动态选择最合适难度的样本。华为提出的 EDCO 方法,将样本难度估计与动态课程编排引入领域大模型微调;数月后,由 Rutgers、Amazon、Google 等作者参与的 DARE 论文即引用 EDCO,并将其作为难度感知强化学习训练的重要对比基线。

华为联合新加坡国立大学和中国科学技术大学研究人员提出 QuantClaw。这是一款面向 OpenClaw 的即插即用动态模型精度路由插件,基于大规模低精度量化实证研究,让模型精度成为可动态分配的资源,实现服务质量不降反升、成本下降、延迟降低的三重收益。
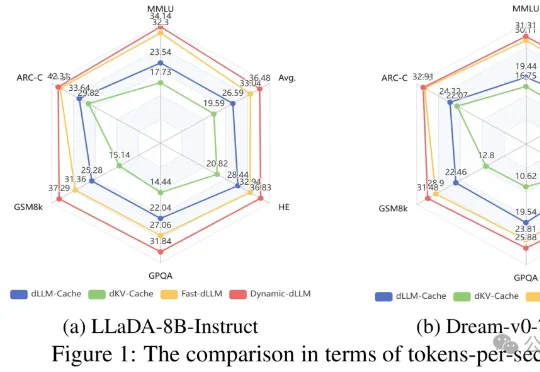
文本生成这件事,扩散大语言模型(dLLMs)正展现出巨大的潜力。但与此同时,它也面临着严重的计算瓶颈——为此,哈工大(深圳)与华为、深圳河套学院的研究团队提出了一套免训练加速框架Dynamic-dLLM。

深圳机器人凭什么惊艳全球?答案不在整机,在一颗电机。小象电动用轴向磁通路线突破量产瓶颈,累计出货近7万台,杀入华为、比亚迪、广汽、美团供应链,完成超亿元融资。这是深圳底层硬科技崛起的缩影,也是中国机器人产业链从「能做样机」到「真正量产」的关键一跃。

来自华为泰勒实验室、北京大学和上海财经大学的研究团队提出了 SHAPE(Stage-aware Hierarchical Advantage via Potential Estimation),给推理链装上了一套「里程碑 + 推理税」机制——不仅告诉模型每一步推得对不对,还让它为啰嗦付出代价。结果是:准确率平均提升 3%,token 消耗直降 30%。

由智源研究院牵头研发的众智 FlagOS 第一时间对两个“巨无霸”模型进行全量适配,已经完成 DeepSeek-V4-Flash 在8款以上 AI 芯片上的全量适配与推理部署,包括海光、沐曦、华为昇腾、摩尔线程(FP8)、昆仑芯、平头哥真武、天数、英伟达(FP8)等芯片。FlagOS 同时正在推进 DeepSeek-V4-Pro 模型在多个芯片的迁移适配,晚些时间开源出来,敬请期待。

业内少有的算法、架构、工程落地全栈型技术专家。