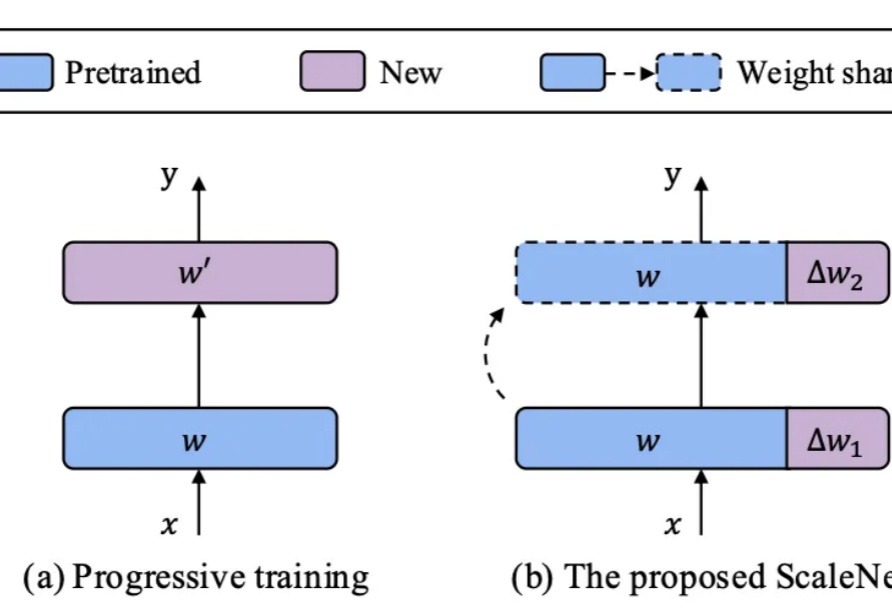
华为诺亚发布ScaleNet:模型放大通用新范式
华为诺亚发布ScaleNet:模型放大通用新范式在基础模型领域,模型规模与性能之间的缩放定律(Scaling Law)已被广泛验证,但模型增大也伴随着训练成本、存储需求和能耗的急剧上升。如何在控制参数量的前提下高效扩展模型,成为当前研究的关键挑战。
来自主题: AI技术研报
10414 点击 2025-11-19 09:31
 搜索
搜索
在基础模型领域,模型规模与性能之间的缩放定律(Scaling Law)已被广泛验证,但模型增大也伴随着训练成本、存储需求和能耗的急剧上升。如何在控制参数量的前提下高效扩展模型,成为当前研究的关键挑战。

华为公司董事、ICT BG CEO 杨超斌在致辞中表示,AI 技术正以前所未有的速度改变各行各业,传统服务器集群无法有效满足算力不断增长的诉求。华为已经开放灵衢互联协议 2.0,支持产业界伙伴打造基于灵衢的超节点,还将向开源欧拉社区贡献支持超节点的操作系统插件代码,提供「内存统一编址」

华为在世界模型上又有新动作:投了一家物理AI公司。

今年是 AI 大模型的落地关键年。大模型技术在快速进步,但行业落地仍面临三大痛点:开发门槛高、场景碎片化、端侧能力有限。结合 AI 能力与云计算,在 CGC2025 大会上,华为云提出的 Versatile 智能体平台与 CloudDevice 云终端协同,正致力于破解这些难题。
据《智能涌现》获悉,极佳视界近日完成新一轮亿元级A1轮融资,本轮融资由华为哈勃、华控基金联合投资。此前8月底,极佳视界宣布完成Pre-A&Pre-A+连续两轮数亿元融资。2个月3轮融资,体现了资本市场对极佳视界团队实力、技术路线和业务推进的认可,也折射出投资方对“物理世界通用智能”(物理AI)关键转折点的判断。
AI大house真来了。

彭超曾在华为印度、阿里任消费硬件业务1号位;联合创始人齐炜祯为Multi-token架构开创学者,被Deepseek、Qwen引入预训练方法。
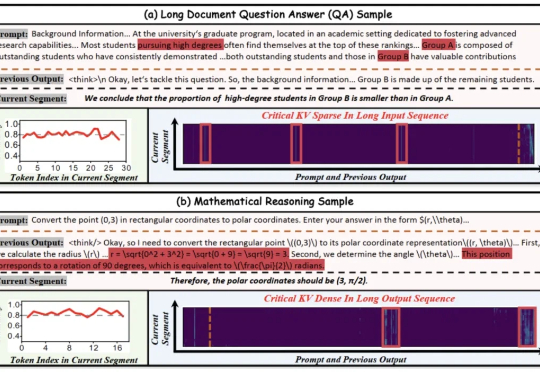
北大华为联手推出KV cache管理新方式,推理速度比前SOTA提升4.7倍! 大模型处理长序列时,KV cache的内存占用随序列长度线性增长,已成为制约模型部署的严峻瓶颈。

DeepSeek v3.2有一个新改动,在论文里完全没提,只在官方公告中出现一次,却引起墙裂关注。开源TileLang版本算子,其受关注程度甚至超过新稀疏注意力机制DSA,从画线转发的数量就可以看出来。
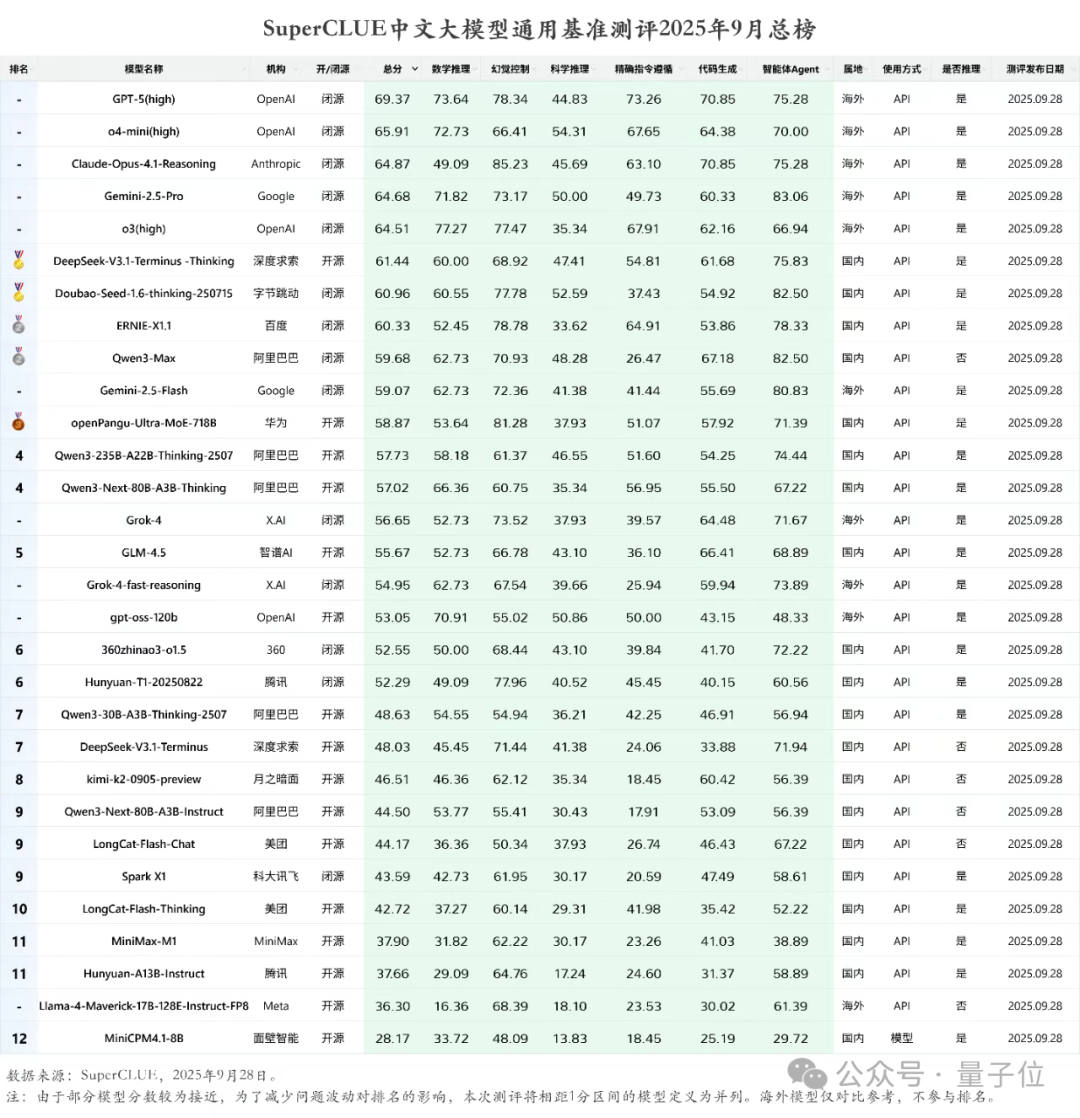
就在最新一期的SuperCLUE中文大模型通用基准测评中,各个AI大模型玩家的成绩新鲜出炉。DeepSeek-V3.1-Terminus-Thinking openPangu-Ultra-MoE-718B Qwen3-235B-A22B-Thinking-2507