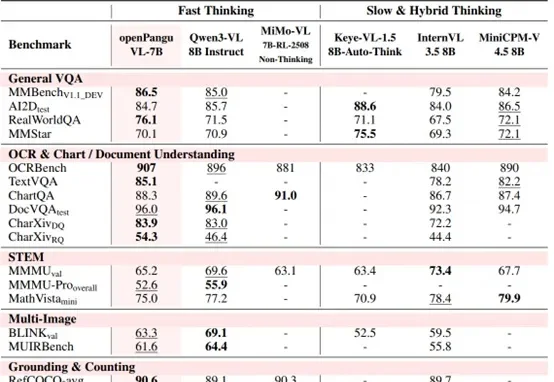
华为开源7B多模态模型,视觉定位和OCR能力出色,你的昇腾端侧“新甜点”来了
华为开源7B多模态模型,视觉定位和OCR能力出色,你的昇腾端侧“新甜点”来了7B量级模型,向来是端侧部署与个人开发者的心头好。
来自主题: AI技术研报
7738 点击 2026-01-05 14:30
 搜索
搜索
7B量级模型,向来是端侧部署与个人开发者的心头好。

刚刚,AI 前线获悉,前华为天才少年、原华为云具身智能核心负责人李元庆已正式加入乐享科技,后续将重点负责乐享科技的创新业务战略规划与核心技术攻关。

《智能涌现》独家获悉,由朱森华创立的“具脑磐石”,近期已完成数千万元的种子轮融资,资方为乐聚机器人等。
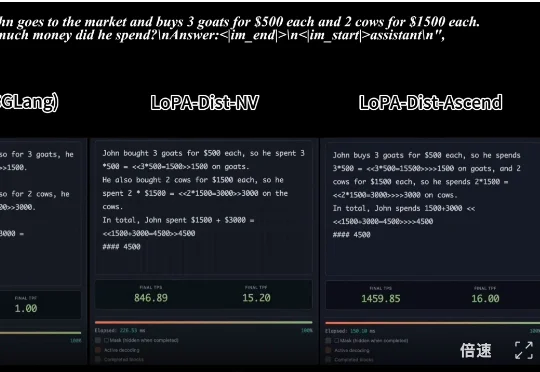
,时长 00:20 视频 1:单样例推理速度对比:SGLang 部署的 Qwen3-8B (NVIDIA) vs. LoPA-Dist 部署 (NVIDIA & Ascend)(注:NVIDIA 平台
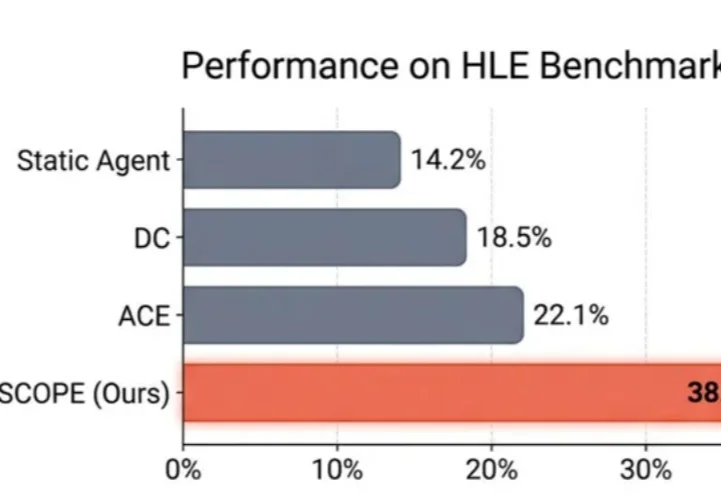
在 LLM Agent 领域,有一个常见的问题:Agent 明明 "看到了" 错误信息,却总是重蹈覆辙。

最近,在 AI 基础算力上重磅频出的华为,又亮出了一张王牌:昇腾的底层基础软件,CANN 全面开源开放。昇腾宣布将通过一系列新举措,持续支持开发者在 AI 模型、算子、内核、底层资源等多个层级进行自主优化与自定义开发。通过开放共建,一个新兴的 AI 算力生态正在快速崛起,改变计算架构领域本已固化的格局。
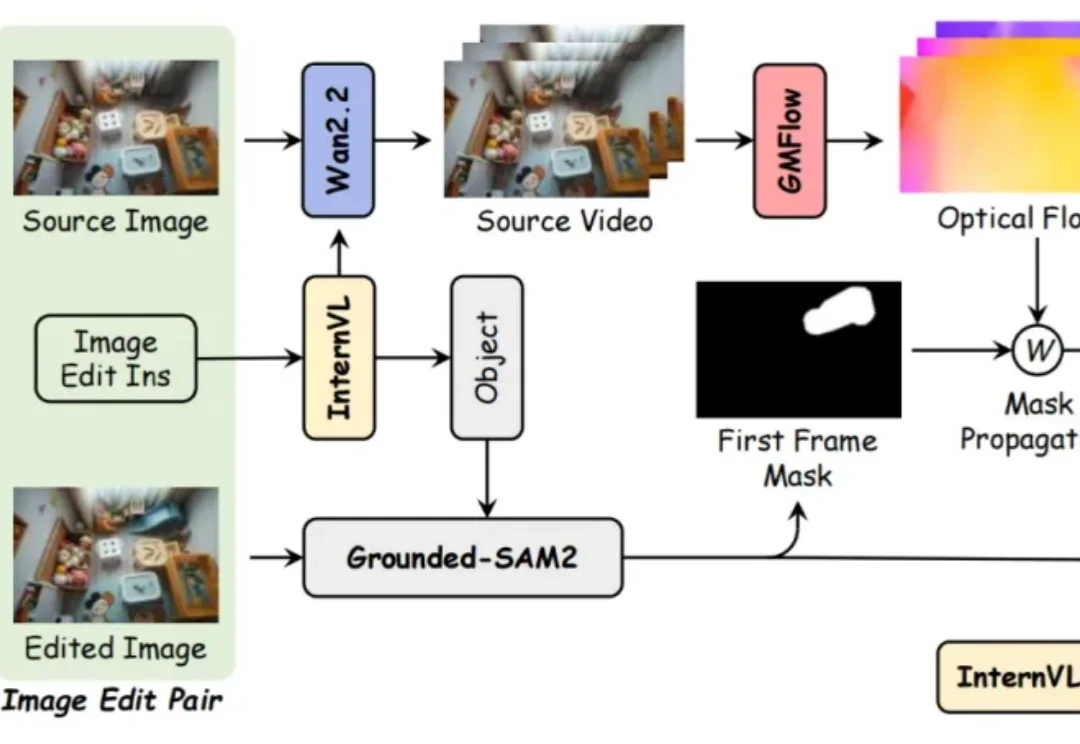
近年来,基于扩散的视频生成模型的最新进展极大地提高了视频编辑的真实感和可控性。然而,文字驱动的视频对象移除添加依然面临巨大挑战:

白铂 博士,华为 2012 实验室理论研究部主任 信息论首席科学家
鹭羽 发自 凹非寺 量子位 | 公众号 QbitAI 具身智能的风也是卷到高校了。 近期,上海交通大学发布公告,宣布即日起拟增设具身智能本科专业。 环顾全球,目前还没有将具身智能作为独立本科专业开设的

在 LLM 优化领域,有两个响亮的名字:Adam(及其变体 AdamW)和 Muon。