
扩散语言模型总是均匀发力,华为诺亚教它「抓重点」
扩散语言模型总是均匀发力,华为诺亚教它「抓重点」这两年,扩散语言模型(Diffusion LLM)一直是个很有讨论度的方向。
来自主题: AI技术研报
6338 点击 2026-03-23 09:51
 搜索
搜索
这两年,扩散语言模型(Diffusion LLM)一直是个很有讨论度的方向。

AI科技评论独家获悉,原华为云中国区副总裁、现华为云新加坡总经理胡维琦将加入 MiniMax,知情人士透露,该项人事变动在 2026 年春节前已达成意向,目前胡维琦正处于入职前的最后准备阶段。

AI下半场拼的是数据。

近日,世界模型与空间智能前沿公司魔芯科技已完成 Pre-A + 轮近亿元融资。本轮融资由华为哈勃领投,老股东跟投。
一个月前我们发布了基于华为 openJiuwen 开源社区构建的 DeepAgent 和 DeepSearch 两款智能体双双霸榜 [DeepAgent与DeepSearch双双霸榜!答案指向openJiuwen这一新兴开源项目]

资本正在加速押注具身智能的下一阶段。

初创公司 Xmax AI 推出的首个虚实融合的实时交互视频模型 X1,没有复杂的 Prompt,不需要漫长的渲染等待,只需要手势进行交互,就可以让虚拟世界与现实相连,在镜头中令「幻想」成真,让用户体验到实时交互的心流体验。
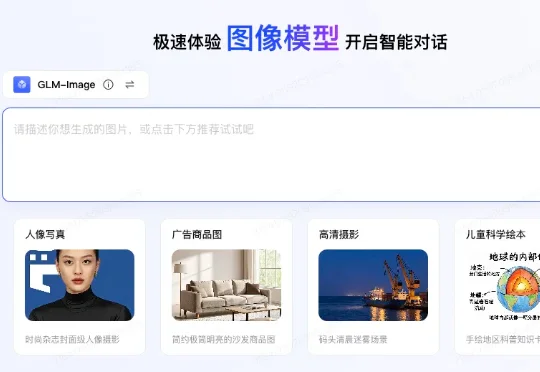
今天,首个在国产芯片上完成全程训练的SOTA(最佳水平)多模态模型开源。这是智谱联合华为开源的图像生成模型GLM-Image。从数据到训练的全流程,该模型完全基于昇腾Atlas 800T A2设备和昇思MindSpore AI框架完成构建。
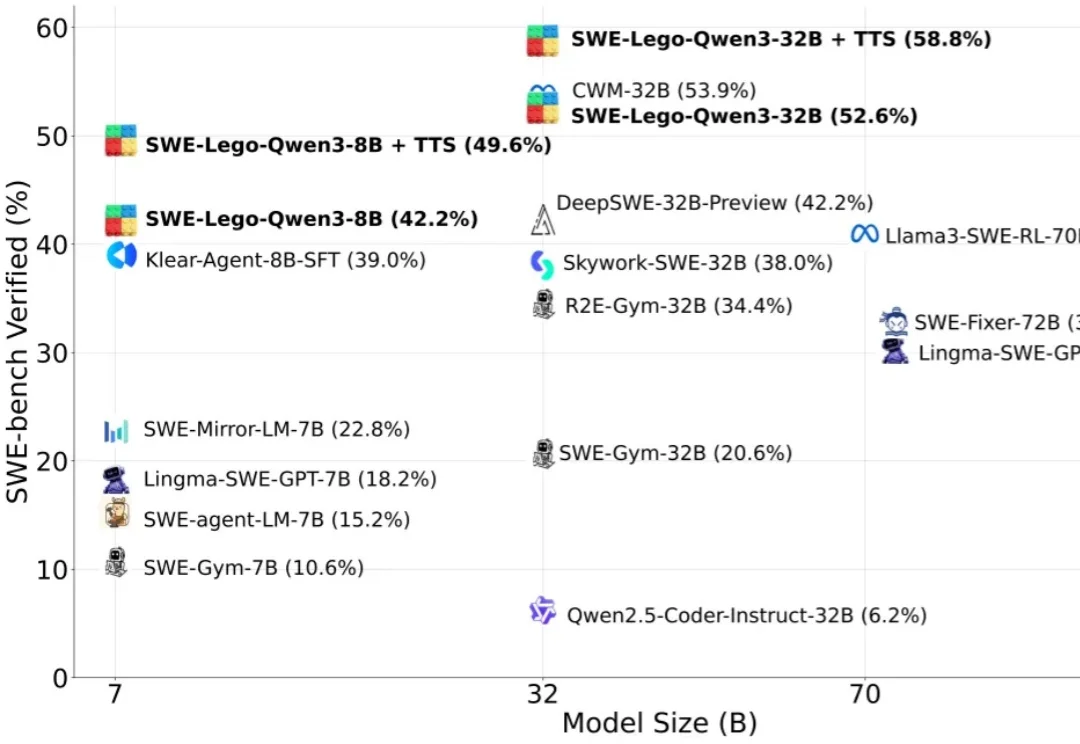
“软工任务要改多文件、多轮工具调用,模型怎么学透?高质量训练数据稀缺,又怕轨迹含噪声作弊?复杂 RL 训练成本高,中小团队望而却步?”

今天我们就借着科技领域的东风,花1分钟时间来了解一下MiniMax的创始人闫俊杰的个人履历和创业故事:1989年,闫俊杰出生于河南某县城。闫俊杰的爸爸是一名初中老师,妈妈是一名公务员,尽管闫俊杰说小时候县城的教育资源相对匮乏,但他父母都有稳定的工作,想必他的童年也比较幸福。