
独家|华为诺亚方舟郝建业创立「忆纪元科技」,聚焦AI 记忆基础设施
独家|华为诺亚方舟郝建业创立「忆纪元科技」,聚焦AI 记忆基础设施AI 科技评论独家获悉,华为诺亚方舟决策与推理实验室主任郝建业创立“深圳忆纪元科技有限公司”(Memorax ai),创业方向聚焦AI 记忆相关的基础设施。企查查信息显示,“忆纪元科技”成立于2026年3月,法人正是郝建业本人,公司业务类型为人工智能软件。
来自主题: AI资讯
9106 点击 2026-04-04 16:21
 搜索
搜索
AI 科技评论独家获悉,华为诺亚方舟决策与推理实验室主任郝建业创立“深圳忆纪元科技有限公司”(Memorax ai),创业方向聚焦AI 记忆相关的基础设施。企查查信息显示,“忆纪元科技”成立于2026年3月,法人正是郝建业本人,公司业务类型为人工智能软件。

华为诺亚方舟实验室主任王云鹤官宣离职。我们梳理了王云鹤的经历。王云鹤今日在朋友圈官宣,将辞去华为诺亚方舟实验室主任职位,告别华为。

这两年,扩散语言模型(Diffusion LLM)一直是个很有讨论度的方向。
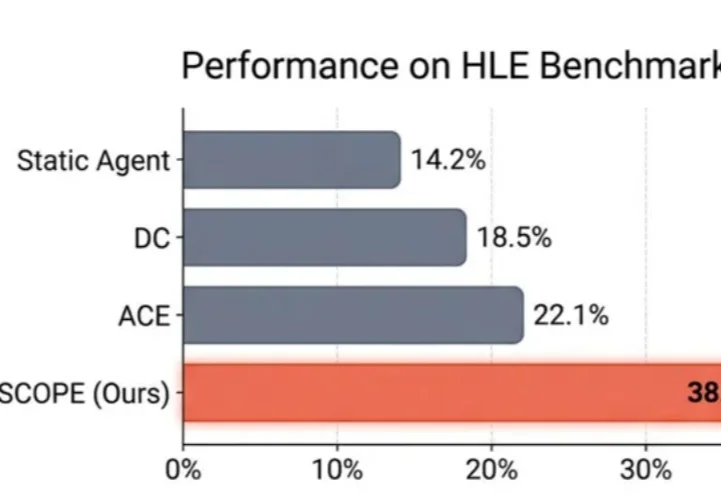
在 LLM Agent 领域,有一个常见的问题:Agent 明明 "看到了" 错误信息,却总是重蹈覆辙。

在 LLM 优化领域,有两个响亮的名字:Adam(及其变体 AdamW)和 Muon。
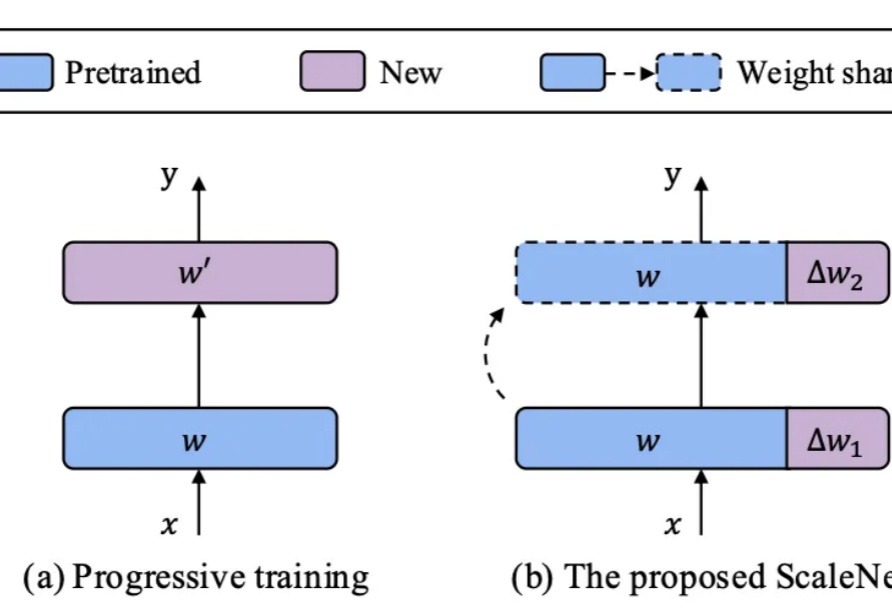
在基础模型领域,模型规模与性能之间的缩放定律(Scaling Law)已被广泛验证,但模型增大也伴随着训练成本、存储需求和能耗的急剧上升。如何在控制参数量的前提下高效扩展模型,成为当前研究的关键挑战。
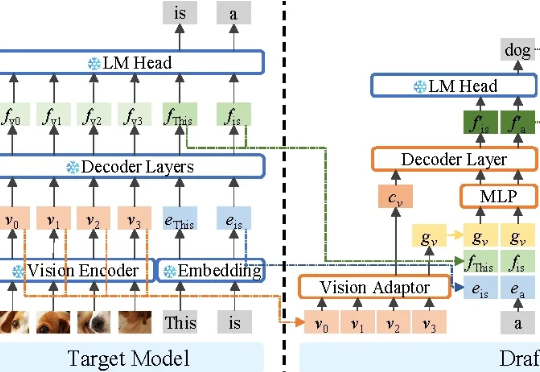
不牺牲任何生成质量,将多模态大模型推理最高加速3.2倍! 华为诺亚方舟实验室最新研究已入选NeurIPS 2025。
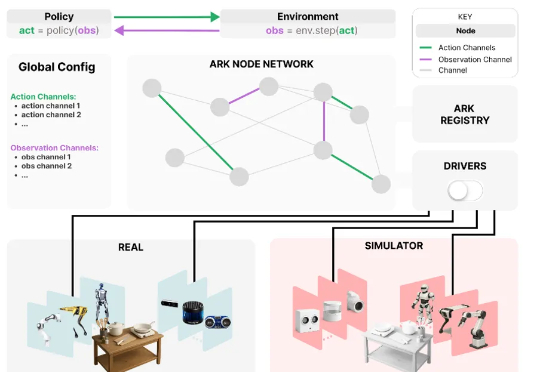
为应对这些挑战,来自华为诺亚方舟实验室,德国达姆施塔特工业大学,英国伦敦大学学院,帝国理工学院和牛津大学的研究者们联合推出了 Ark —— 一个基于 Python 的机器人开发框架,支持快速原型构建,并可便捷地在仿真和真实机器人系统上部署新算法。
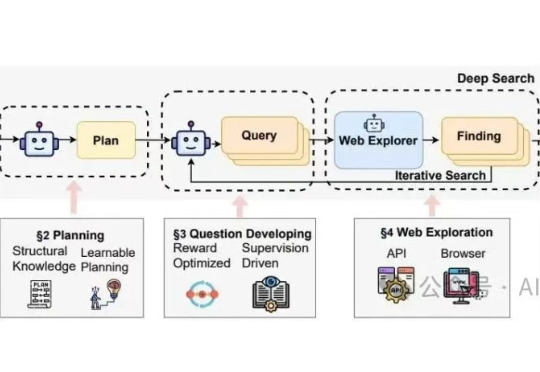
华为诺亚方舟实验室最近联合香港大学发了一篇针对"Deep Research Agents"(深度研究代理)的系统性综述,在我的印象中,这是他们第二次发布关于Deep Research的综述论文。上一篇里提供了一个结构导向 (Structure-Oriented) 的视角,核心是“分类”。

具身智能,成了这个夏天最炙手可热的创业赛道。 量子位独家获悉,华为诺亚方舟实验室首席研究员,刚刚创办了一家具身智能公司。