
EMNLP2025 | 通研院揭秘MoE可解释性,提升Context忠实性!
EMNLP2025 | 通研院揭秘MoE可解释性,提升Context忠实性!在大模型研究领域,做混合专家模型(MoE)的团队很多,但专注机制可解释性(Mechanistic Interpretability)的却寥寥无几 —— 而将二者深度结合,从底层机制理解复杂推理过程的工作,更是凤毛麟角。
来自主题: AI技术研报
10766 点击 2025-11-17 09:25
 搜索
搜索
在大模型研究领域,做混合专家模型(MoE)的团队很多,但专注机制可解释性(Mechanistic Interpretability)的却寥寥无几 —— 而将二者深度结合,从底层机制理解复杂推理过程的工作,更是凤毛麟角。

刚刚,在理解大模型复杂行为的道路上,OpenAI又迈出了关键一步。他们从自己训练出来的稀疏模型里,发现存在结构小而清晰、既可理解又能完成任务的电路(这里的电路,指神经网络内部一组协同工作的特征与连接模式,是AI可解释性研究的一个术语)。
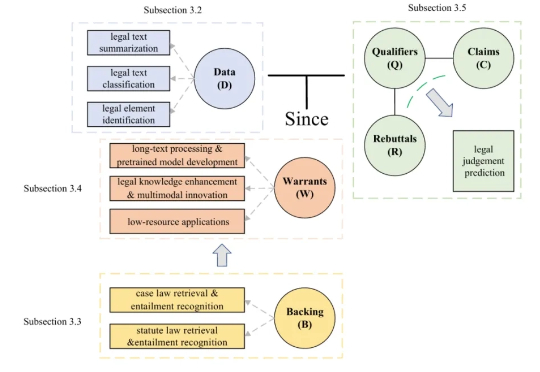
研究人员首次系统综述了大型语言模型(LLM)在法律领域的应用,提出创新的双重视角分类法,融合法律推理框架(经典的法律论证型式框架)与职业本体(律师/法官/当事人角色),统一梳理技术突破与伦理治理挑战。论文涵盖LLM在法律文本处理、知识整合、推理形式化方面的进展,并指出幻觉、可解释性缺失、跨法域适应等核心问题,为下一代法律人工智能奠定理论基础与实践路线图。
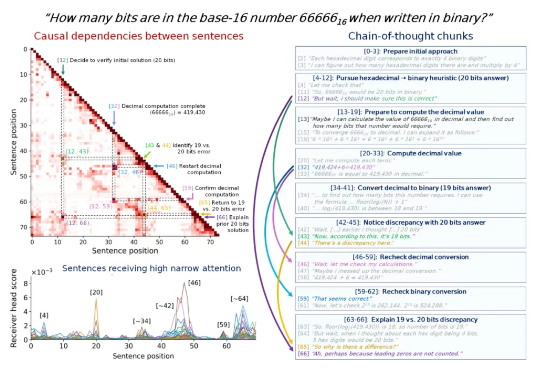
思维链里的步骤很重要,但有些步骤比其他步骤更重要,尤其是在一些比较长的思维链中。 找出这些步骤,我们就可以更深入地理解 LLM 的内部推理机制,从而提高模型的可解释性、可调试性和安全性。
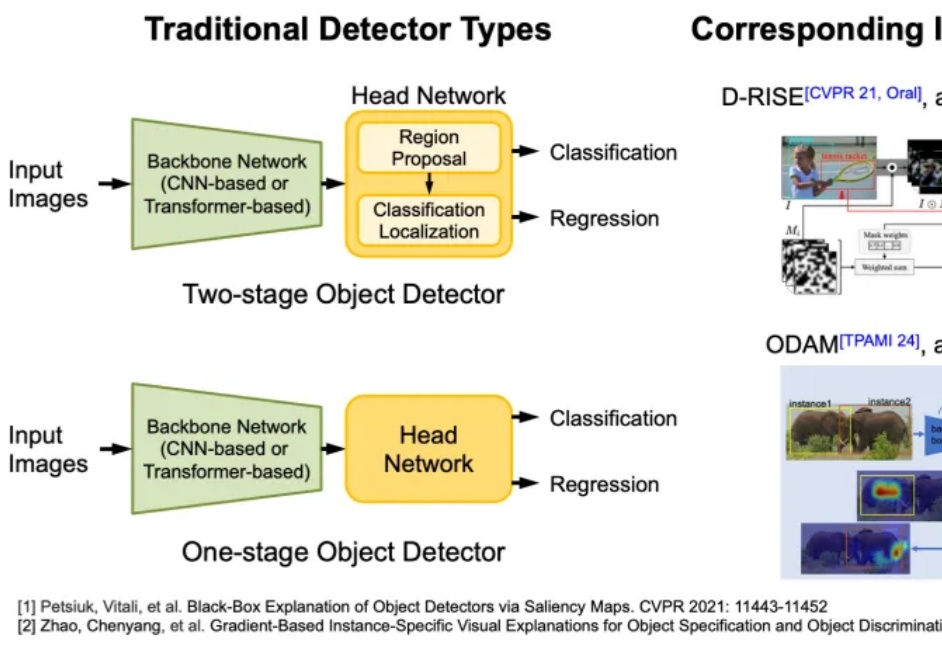
在日常生活中,我们常通过语言描述寻找特定物体:“穿蓝衬衫的人”“桌子左边的杯子”。如何让 AI 精准理解这类指令并定位目标,一直是计算机视觉的核心挑战。
AI 决策的可靠性与安全性是其实际部署的核心挑战。当前智能体广泛依赖复杂的机器学习模型进行决策,但由于模型缺乏透明性,其决策过程往往难以被理解与验证,尤其在关键场景中,错误决策可能带来严重后果。因此,提升模型的可解释性成为迫切需求。

AI 决策的可靠性与安全性是其实际部署的核心挑战。当前智能体广泛依赖复杂的机器学习模型进行决策,但由于模型缺乏透明性,其决策过程往往难以被理解与验证,尤其在关键场景中,错误决策可能带来严重后果。因此,提升模型的可解释性成为迫切需求。
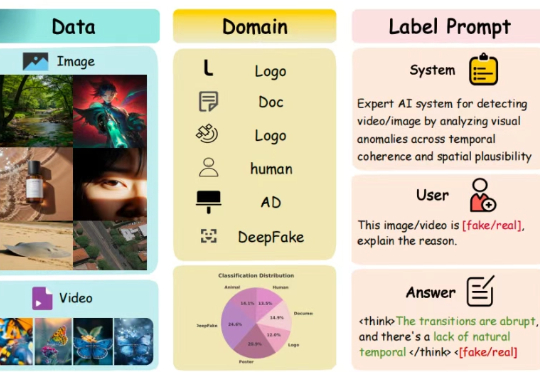
想象一下:你正在浏览社交媒体,看到一张震撼的图片或一段令人震撼的视频。它栩栩如生,细节丰富,让你不禁信以为真。但它究竟是真实记录,还是由顶尖 AI 精心炮制的「杰作」?如果一个 AI 工具告诉你这是「假的」,它能进一步解释理由吗?它能清晰指出图像中不合常理的光影,或是视频里一闪而过的时序破绽吗?
ChatGPT「舔狗化」事件背后,暴漏目前AI仍是「黑箱」。 一场关于「机制可解释性」的路线分歧,正撕裂AI研究最核心的价值共识。谷歌认怂,Anthropic死磕——AI还能被「看懂」吗?

首次将DeepSeek同款RLVR应用于全模态LLM,含视频的那种!