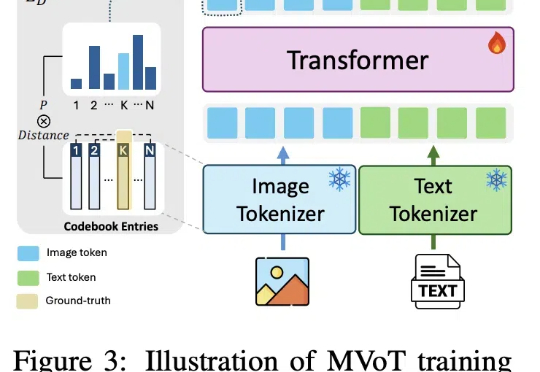
超越CoT!微软剑桥中科院提出MVoT,直接可视化多模态推理过程
超越CoT!微软剑桥中科院提出MVoT,直接可视化多模态推理过程近日,微软和剑桥大学公布推理新方法:多模态思维可视化MVoT。新方法可以边推理,边「想象」,同时利用文本和图像信息学习,在实验中比CoT拥有更好的可解释性和稳健性,复杂情况下甚至比CoT强20%。还可以与CoT组合,进一步提升模型性能。
来自主题: AI技术研报
7669 点击 2025-02-14 14:15
 搜索
搜索
近日,微软和剑桥大学公布推理新方法:多模态思维可视化MVoT。新方法可以边推理,边「想象」,同时利用文本和图像信息学习,在实验中比CoT拥有更好的可解释性和稳健性,复杂情况下甚至比CoT强20%。还可以与CoT组合,进一步提升模型性能。
本文作者为北京邮电大学网络空间安全学院硕士研究生倪睿康,指导老师为肖达副教授。主要研究方向包括自然语言处理、模型可解释性。该工作为倪睿康在彩云科技实习期间完成。联系邮箱:ni@bupt.edu.cn, xiaoda99@bupt.edu.cn

从软件工程和网络安全的角度来看,当前的AI落地前景如何?「可解释性」方面的研究,真的能让AI拜托「黑箱」属性吗?
本文介绍了首个多模态大模型(MLLM)可解释性综述
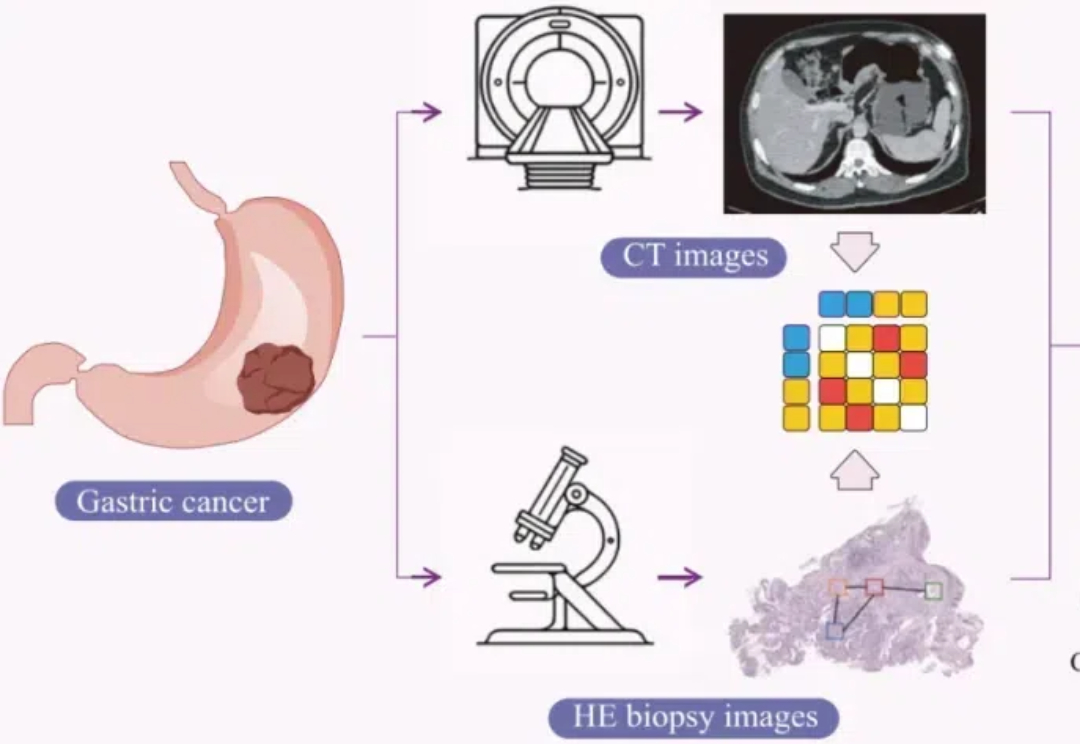
Cell Reports Medicine近期的研究结合CT和病理图像,提出一种可解释的人工智能框架用于预测胃癌患者新辅助化疗的疗效。
Claude团队三巨头同时接受采访,回应一切。 整整5个小时,创始人Dario Amodei、Claude性格设计师Amanda Askell、机制可解释性先驱Chris Olah无所不谈,透露了关于模型、公司和行业的很多内幕和细节。

近日,中科大王杰教授团队(MIRA Lab)和华为诺亚方舟实验室(Huawei Noah's Ark Lab)联合提出了可生成具有成千上万节点规模的神经电路生成与优化框架,具备高扩展性和高可解释性,这为新一代芯片电路逻辑综合工具奠定了重要基础。论文发表在 CCF-A 类人工智能顶级会议 Neural Information Processing Systems(NeurIPS 2024)。

北京大学的研究人员开发了一种新型多模态框架FakeShield,能够检测图像伪造、定位篡改区域,并提供基于像素和图像语义错误的合理解释,可以提高图像伪造检测的可解释性和泛化能力。
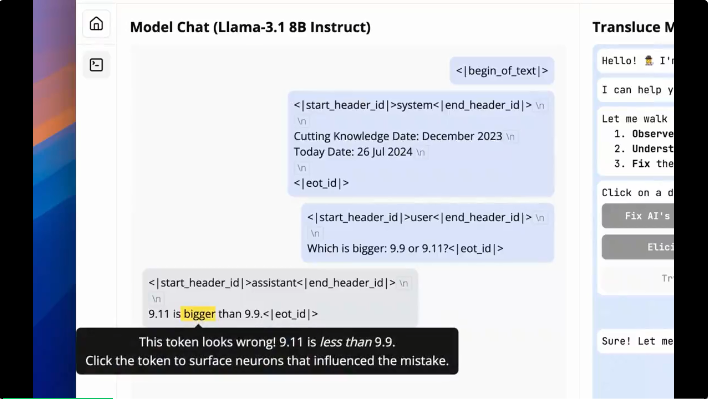
大模型分不清“9.9和9.11哪个更大”的谜团,终于被可解释性研究揭秘了!
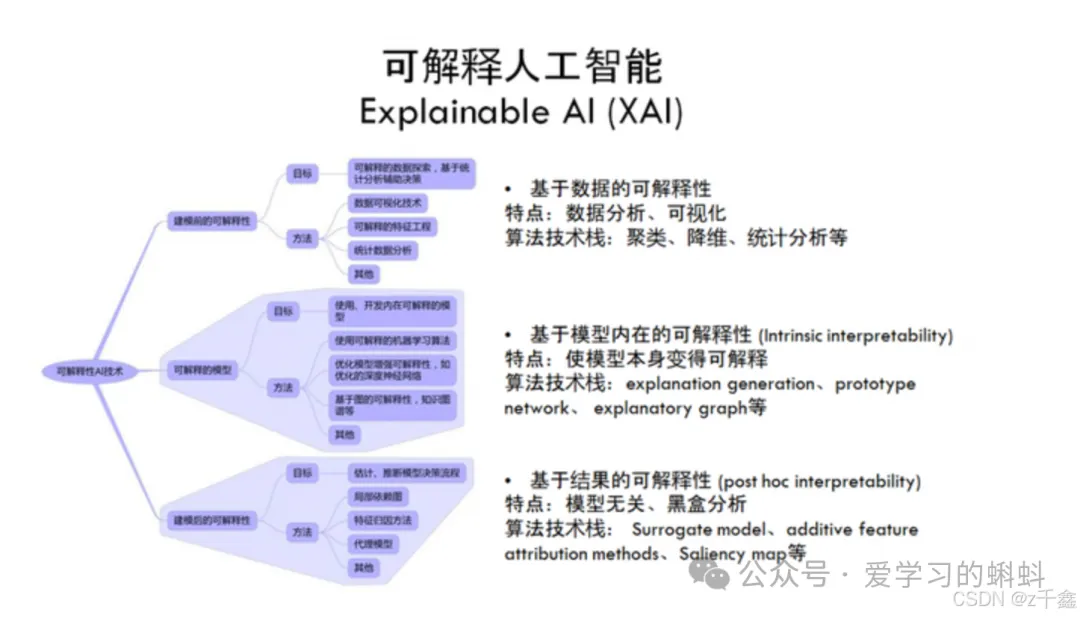
在当今人工智能(AI)和机器学习(ML)技术迅猛发展的背景下,解释性AI(Explainable AI, XAI)已成为一个备受关注的话题。