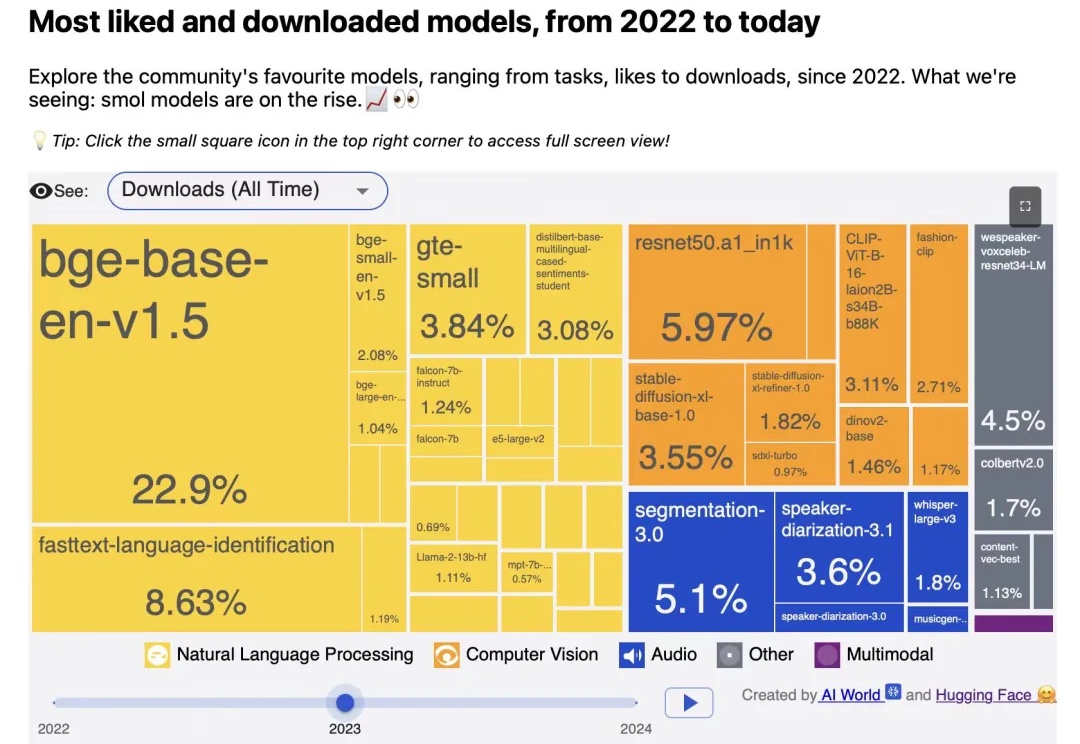
智源3款向量模型发布!代码检索及多模态维度刷新多项SOTA
智源3款向量模型发布!代码检索及多模态维度刷新多项SOTA检索增强技术在代码及多模态场景中的发挥着重要作用,而向量模型是检索增强体系中的重要组成部分。
来自主题: AI资讯
8841 点击 2025-05-20 15:47
 搜索
搜索
检索增强技术在代码及多模态场景中的发挥着重要作用,而向量模型是检索增强体系中的重要组成部分。

就在刚刚,智源研究员联合多所高校开放三款向量模型,以大优势登顶多项测试基准。其中,BGE-Code-v1直接击穿代码检索天花板,百万行级代码库再也不用怕了!

Redis 最近推出向量集合(Vector Set) 功能,这是一种专为向量相似性设计的数据类型,也是 Redis 针对人工智能应用的一个新的选项。这是 Redis 创始人 Salvatore Sanfilippo(“antirez”)自 重新加入 公司以来的第一个重大贡献。

那些曾在KDD时代Kaggle上打榜刷分的老炮儿,每每提起 Bagging 与 Boosting 这两项技术嘴角都压不住笑。
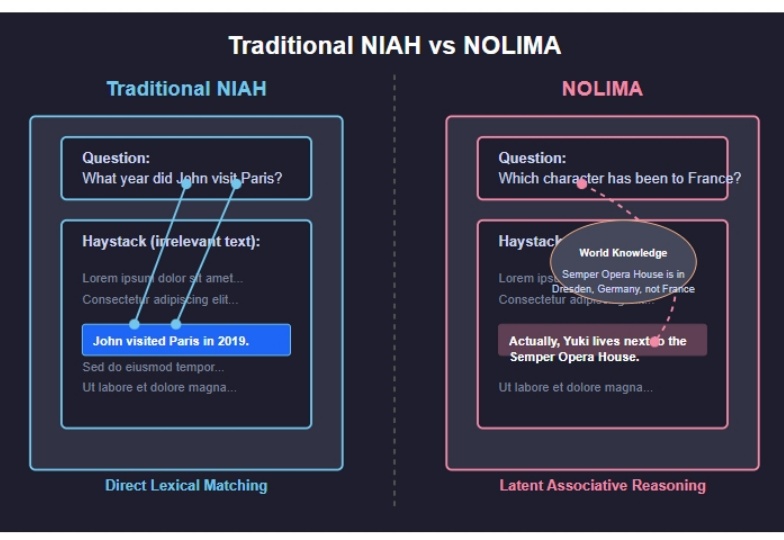
2025 年 2 月发布的 NoLiMA 是一种大语言模型(LLM)长文本理解能力评估方法。不同于传统“大海捞针”(Needle-in-a-Haystack, NIAH)测试依赖关键词匹配的做法,它最大的特点是 通过精心设计问题和关键信息,迫使模型进行深层语义理解和推理,才能从长文本中找到答案。
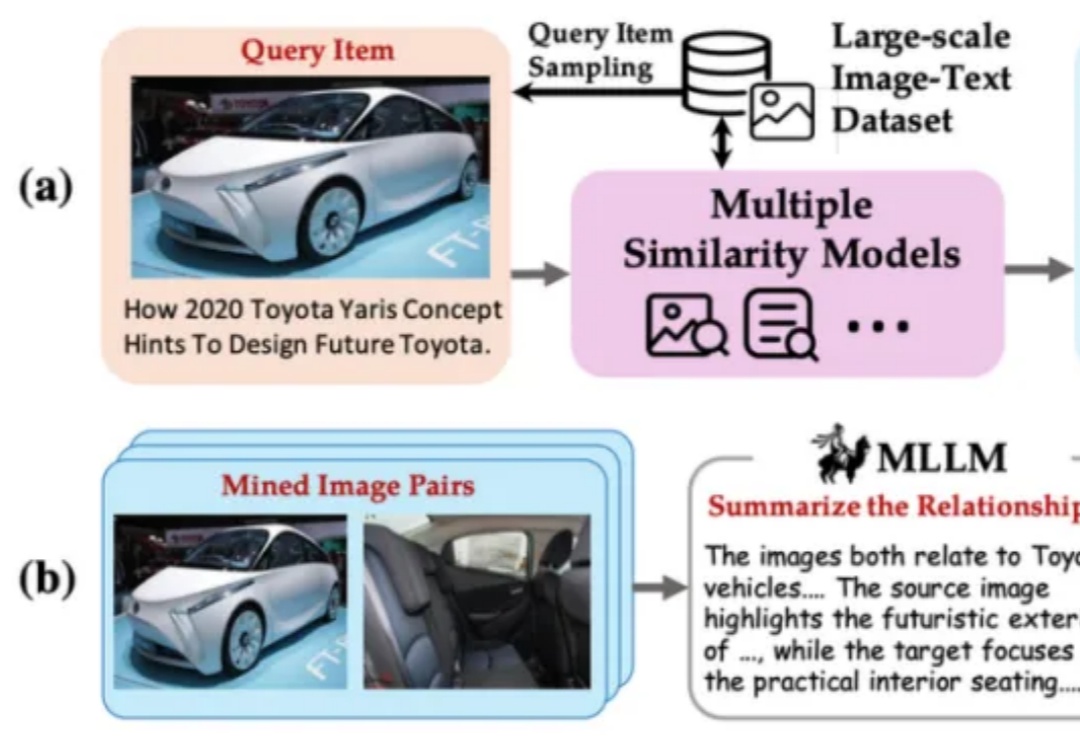
BGE 系列模型自发布以来广受社区好评。近日,智源研究院联合多所高校开发了多模态向量模型 BGE-VL,进一步扩充了原有生态体系。

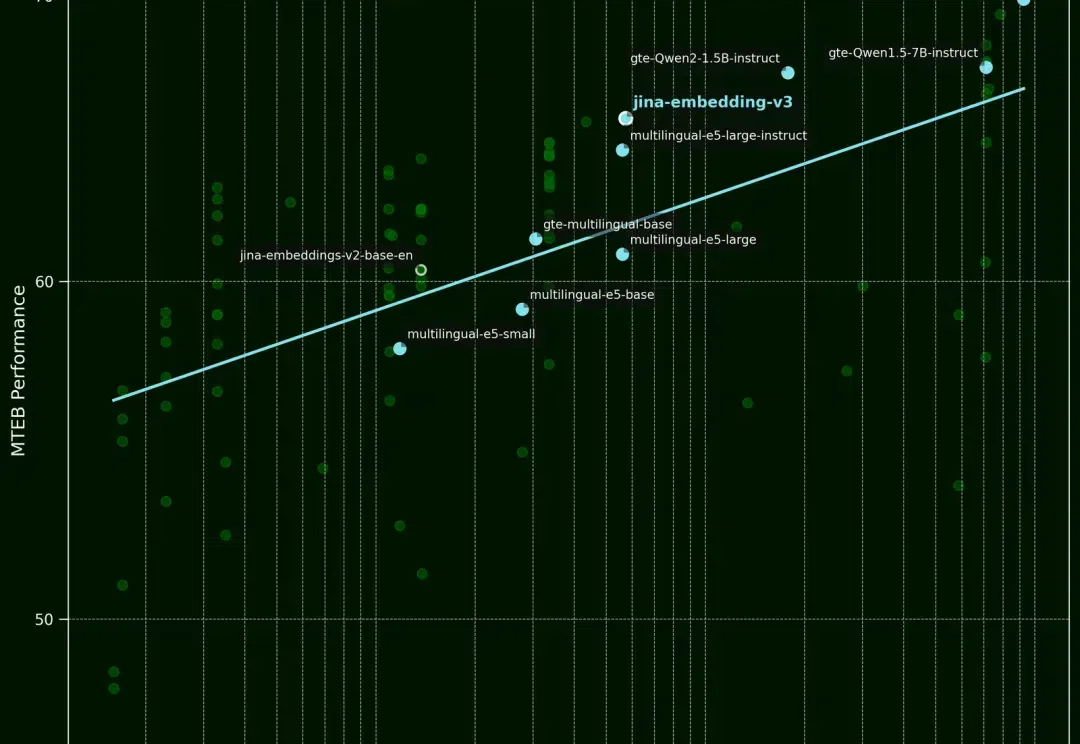
什么,你在开发RAG竟然还没听说过Embedding模型还有排名?在AI应用开发热潮中,Embedding模型的选择已成为决定RAG系统成败的关键因素。然而,令人惊讶的是,许多开发者仍依靠直觉或跟风选择模型,而非基于系统化评估。
最近,LAION AI 的创始人 Christoph Schuhmann 分享了一个有趣的发现,他指出,文本向量模型似乎存在一个问题:即使句子词序被打乱,模型输出的向量与原句仍然高度相似。
长文本向量模型能够将十页长的文本编码为单个向量,听起来很强大,但真的实用吗? 很多人觉得... 未必。 直接用行不行?该不该分块?怎么分才最高效?本文将带你深入探讨长文本向量模型的不同分块策略,分析利弊,帮你避坑。
命运齿轮转动的开始,源于 2023 年的 3 月 23 日的 OpenAI 一次日常更新。