ICCV 2025|训练太复杂?对图片语义、布局要求太高?图像morphing终于一步到位
ICCV 2025|训练太复杂?对图片语义、布局要求太高?图像morphing终于一步到位本文第一作者操雨康,南洋理工大学MMLab博士后,研究方向是3D/4D重建与生成,人体动作/视频生成,以及图像生成与编辑。
来自主题: AI技术研报
9260 点击 2025-07-18 11:12
 搜索
搜索
本文第一作者操雨康,南洋理工大学MMLab博士后,研究方向是3D/4D重建与生成,人体动作/视频生成,以及图像生成与编辑。

怎么快速判断一个生成模型好不好? 最直接的办法当然是 —— 去问一位做图像生成、视频生成、或者专门做评测的朋友。他们懂技术、有经验、眼光毒辣,能告诉你模型到底强在哪、弱在哪,适不适合你的需求。

自 Stable Diffusion、Flux 等扩散模型 (Diffusion models) 席卷图像生成领域以来,文本到图像的生成技术取得了长足进步。但它们往往只能根据精确的文字或图片提示作图,缺乏真正读懂图像与文本、在多模 态上下文中推理并创作的能力。能否让模型像人类一样真正读懂图像与文本、完成多模态推理与创作,一直是学术界和工业界关注的热门问题。
随着 OpenAI 推出 GPT-4o 的图像生成功能,AI 生图能力被拉上了一个新的高度,但你有没有想过,这光鲜亮丽的背后也隐藏着严峻的安全挑战:如何区分生成图像和真实图像?

智源统一图像生成模型OmniGen2发布后,立刻在AI图像生成领域掀起巨响,多模态技术生态进一步打通。才一周,GitHub星标就已经破了2000,X上的话题浏览数直接破数十万。

设定角色,让AI照“本”生成主角不变的不同图像,对于各路AIGC工具来说一直是不小的挑战。
近年来,随着扩散模型(Diffusion Models)、Transformer 架构与高性能视觉理解模型的蓬勃发展,视频生成任务取得了令人瞩目的进展。从静态图像生成视频的任务(Image-to-Video generation)尤其受到关注,其关键优势在于:能够以最小的信息输入生成具有丰富时间连续性与空间一致性的动态内容。
清华大学朱军教授团队与 NVIDIA Deep Imagination 研究组联合提出一种全新的视觉生成模型优化范式 —— 直接判别优化(DDO)。
![Black Forest震撼开源FLUX.1 Kontext [dev]:媲美GPT-4o的图像编辑](https://www.aitntnews.com/pictures/2025/6/27/49d75709-5310-11f0-82be-fa163e47d677.jpg)
前段时间,沉寂了很久的Flux官方团队Black Forest Labs发布了新模型:FLUX.1 Kontext,这是一套支持生成与编辑图像的流匹配(flow matching)模型。FLUX.1 Kontext不仅支持文生图,还实现了上下文图像生成功能,可以同时使用文本和图像作为提示词,并能无缝提取修改视觉元素,生成全新且协调一致的画面。
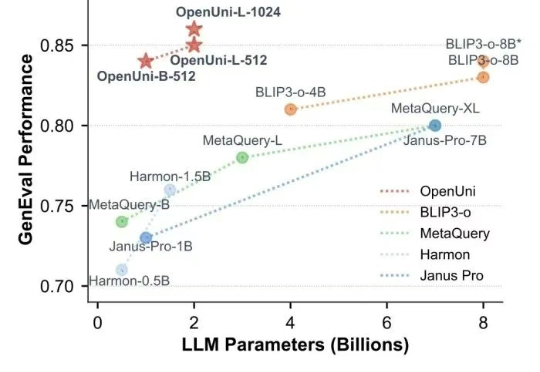
随着 GPT-4o 展现出令人印象深刻的多模态能力,将视觉理解和图像生成统一到单一模型中已成为 AI 领域的研究趋势(如MetaQuery 和 BLIP3-o )。