首次!流匹配模型引入GRPO,GenEval几近满分,组合生图能力远超GPT-4o
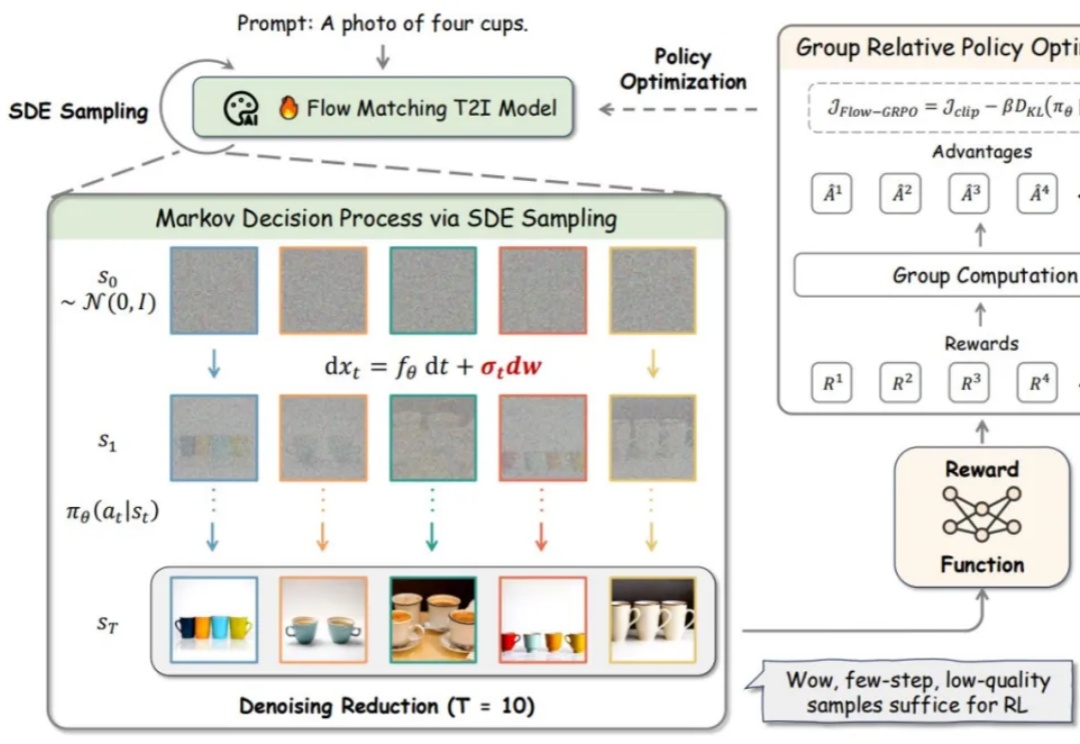
首次!流匹配模型引入GRPO,GenEval几近满分,组合生图能力远超GPT-4o流匹配模型因其坚实的理论基础和在生成高质量图像方面的优异性能,已成为图像生成(Stable Diffusion, Flux)和视频生成(可灵,WanX,Hunyuan)领域最先进模型的训练方法。然而,这些最先进的模型在处理包含多个物体、属性与关系的复杂场景,以及文本渲染任务时仍存在较大困难。
来自主题: AI技术研报
11568 点击 2025-05-14 10:19