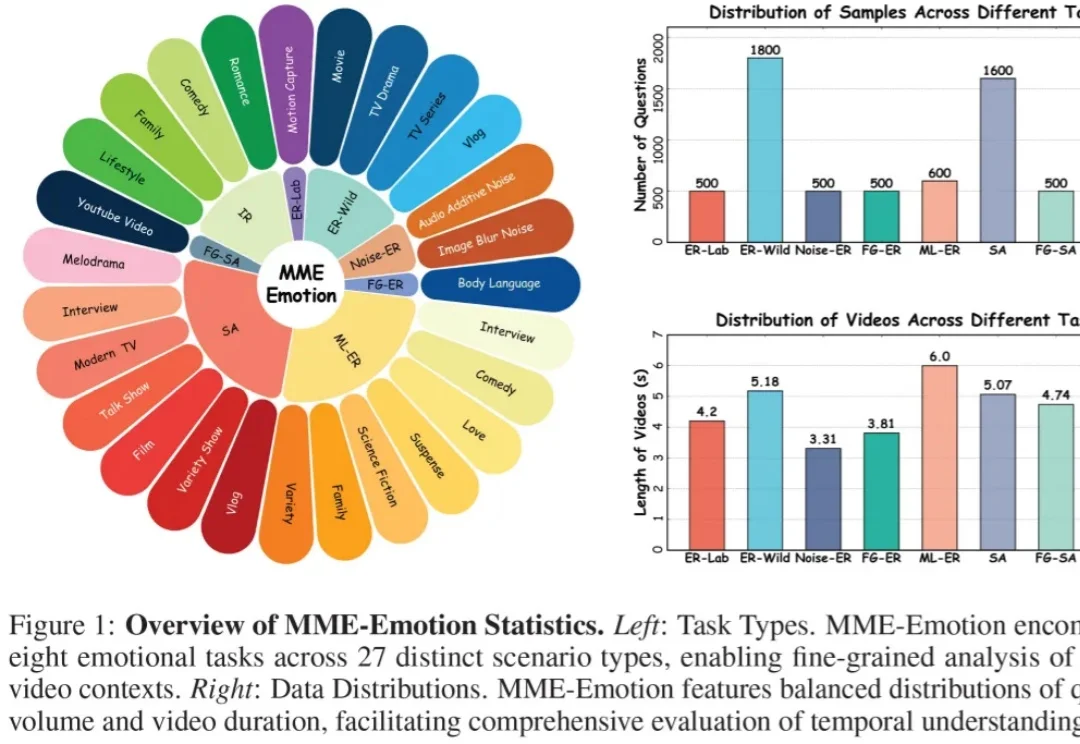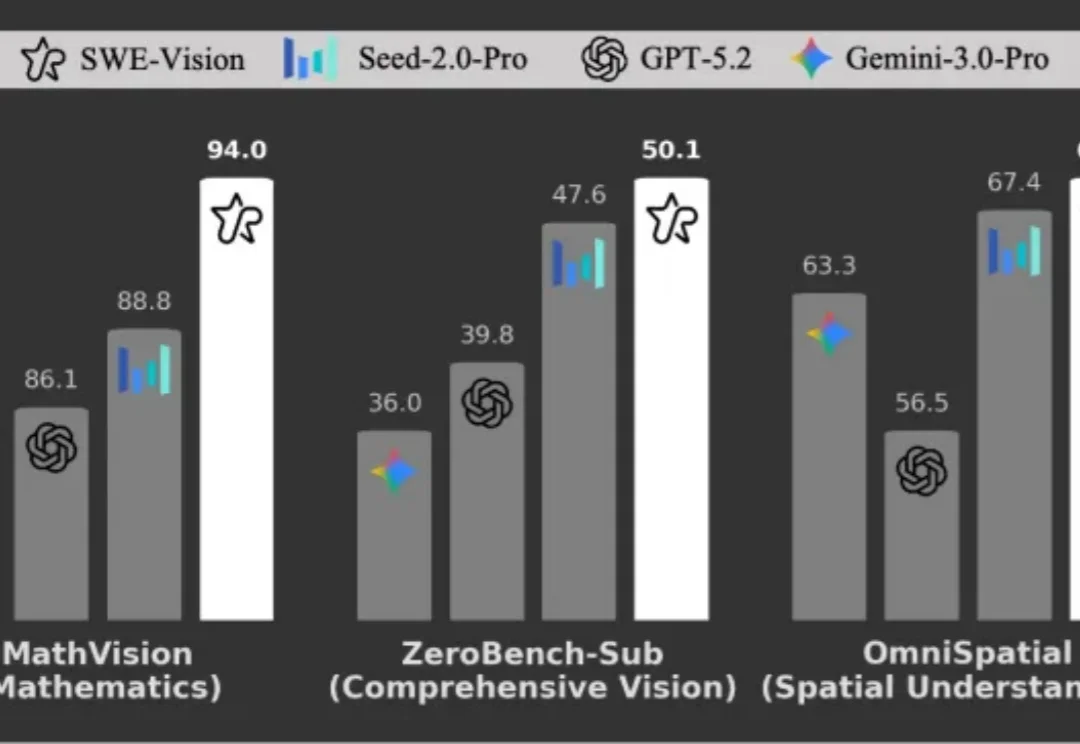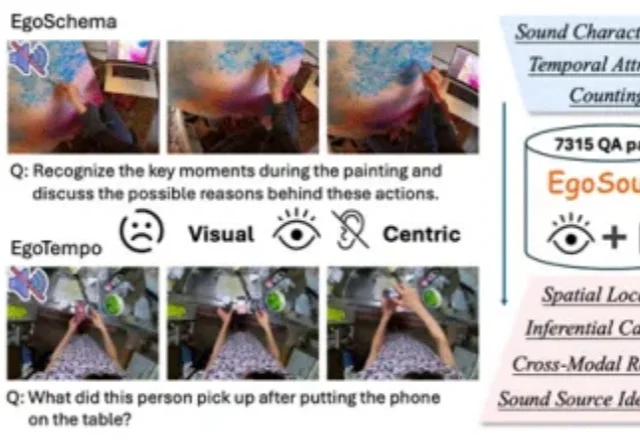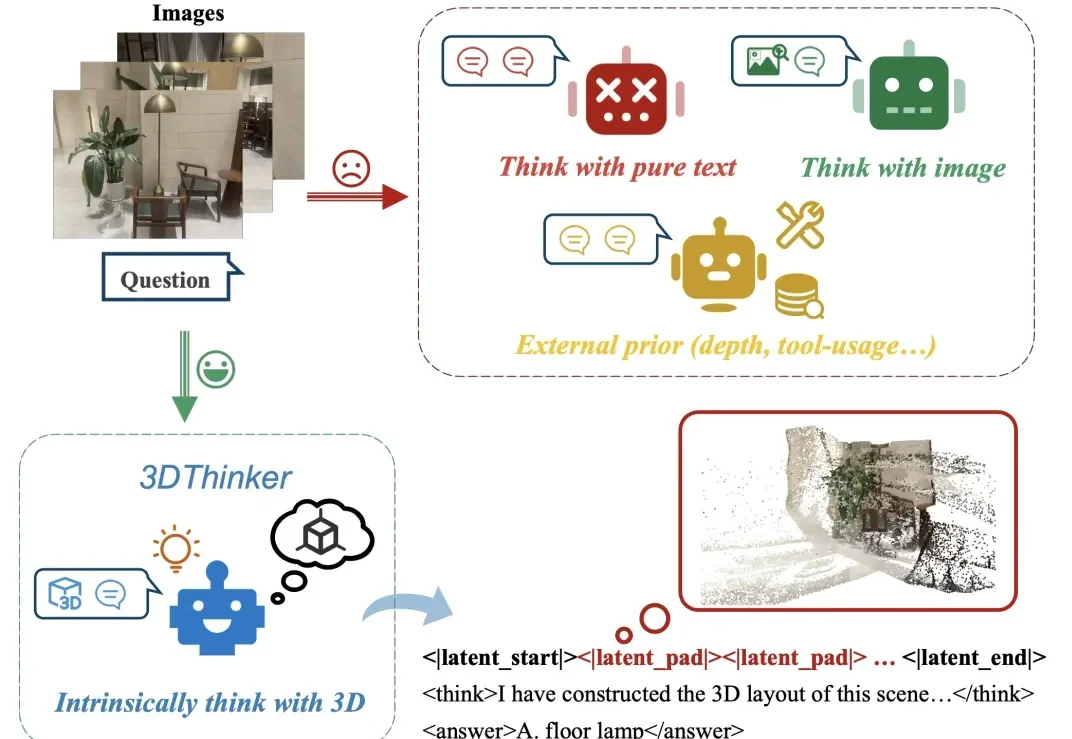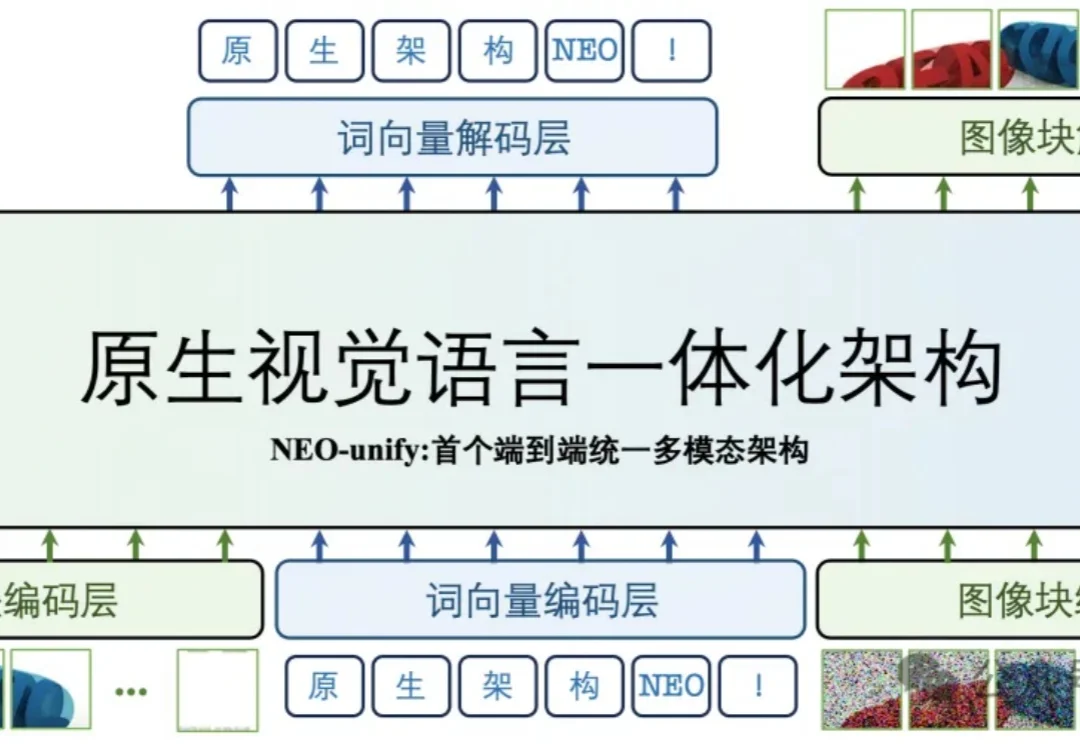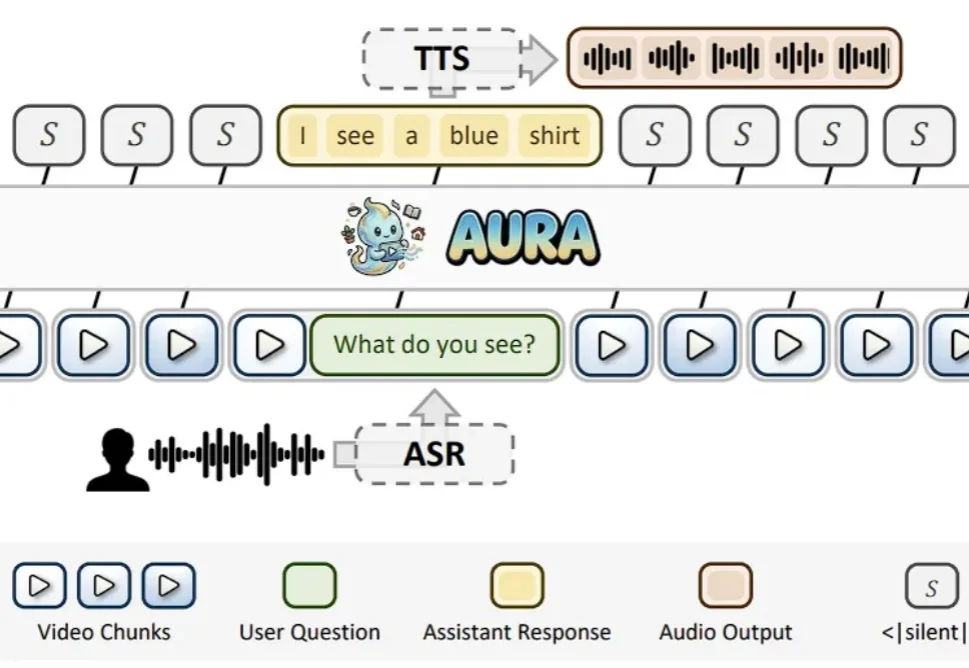
AURA:让视频大模型从“看完再答”,走向“边看边理解、边看边响应”
AURA:让视频大模型从“看完再答”,走向“边看边理解、边看边响应”近年来,视频多模态大模型(VideoLLM)发展迅猛,在视频描述、视频问答、时序定位等任务上不断刷新性能上限。随着模型能力持续增强,业界也开始思考一个更重要的问题:视频大模型能不能不再只是 “看完一段视频再回答”,而是真正进入实时世界,持续观察、实时理解,并在关键时刻主动给出反馈?
来自主题: AI技术研报
6461 点击 2026-04-21 09:23