# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
多模态大模型(MLLMs)虽然在图像理解、视频分析上表现出色,但多停留在整体场景级理解。
而场景级理解 ≠ 视觉理解的终点,现实任务(如自动驾驶、机器人、医疗影像、视频分析)需要的是细粒度、对象级(object-level)详细理解。
然而,当下的研究工作,如英伟达的Describe Anything Model (DAM)局限于单个物体的描述,难以深入理解多对象属性、交互关系及其时序演变,且牺牲了模型本身的通用理解能力。
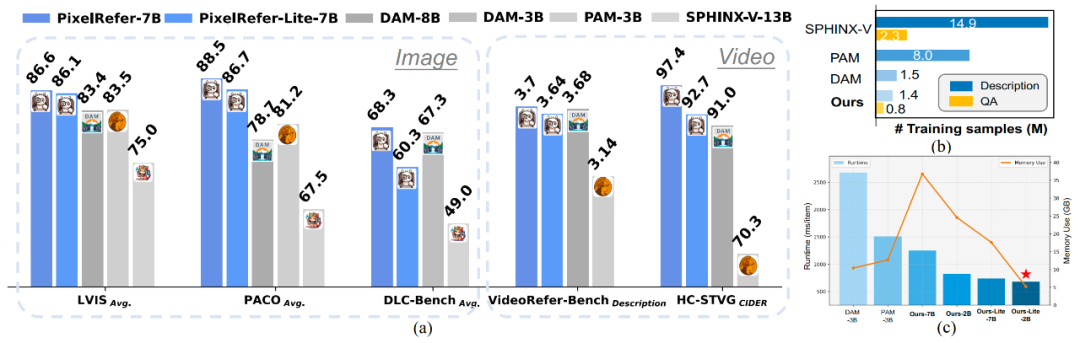
针对这一问题,浙江大学、达摩院、香港理工大学联合提出了一种创新的解决方案PixelRefer:一个统一的时空像素级区域级理解框架,可实现任意粒度下的精细视觉指代与推理,在多项像素级细粒度理解任务取得领先性能表现。和DAM-3B相比,轻量版的2B模型推理时间加快了4倍,显存占用减半,且训练数据量大大少于已有方法。
PixelRefer能够对任意目标实现准确语义理解以及时空物体区域理解。




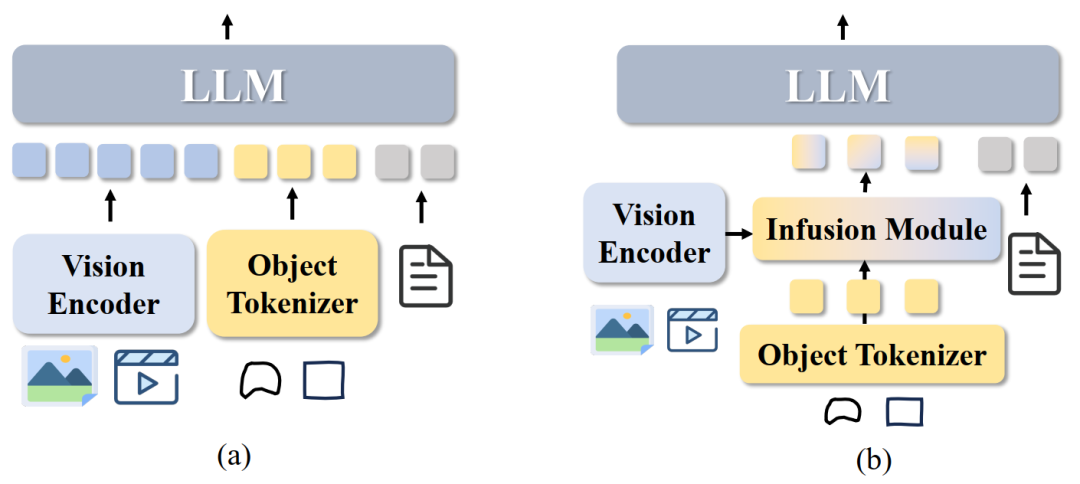
为了探索解决以上问题,作者基于通用视觉基础模型采用最直接的设计:将全局视觉token+像素级区域token+文本token一起喂给 LLM。当无物体指代区域时,模型则退化成通用视觉理解任务,从而实现区域理解的同时,保留通用模型本身的通用理解能力。
作者对LLM内从浅层到深层中分析视觉token、区域token以及其他类型token进行可视化分析。本文可以发现从浅层到深层,答案(Ans)优先关注像素级区域token,其attention分数一直很高,说明物体token表征对于模型的回答起到重要的作用。此外,全局图像token(vision)则仅在浅层中(第一层)表现出较高的attention分布(Answer-to-image token attention),LLM的深层则表现较弱,甚至没有影响,这个在通用视觉基础模型研究中也被讨论到。

浅层到深层的attention可视化
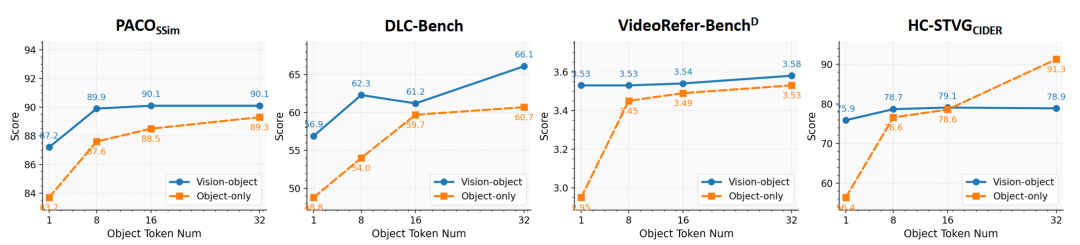
基于此分析,作者得出两种设计方案:
为此,作者针对像素级细粒度理解定义了两种框架,Vision-Object Framework (a)与Object-Only Framework (b):
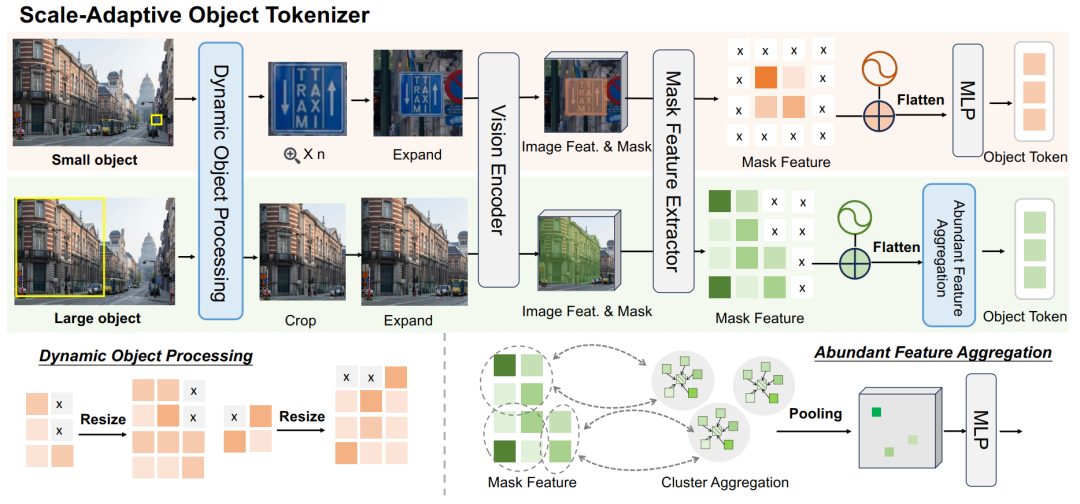
对于PixelRefer,作者把全局视觉token+像素级区域token+文本token一起送入 LLM,既保留场景语境,又在对象级上精细推理。关键在于像素级区域表征token质量足够高。为此,作者提出尺度自适应对象分词器(Scale-Adaptive Object Tokenizer, SAOT) 来生成精确、紧凑、语义丰富的对象表示。
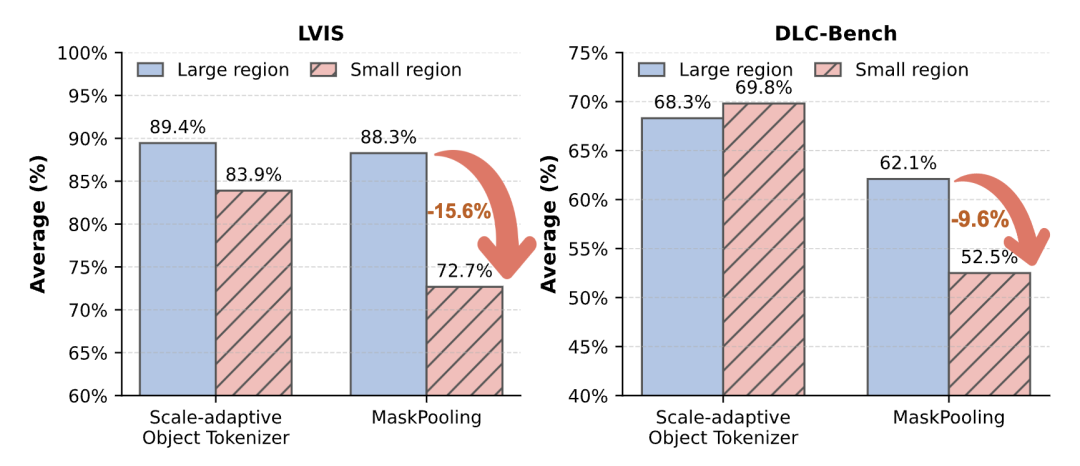
SAOT 围绕两个设计:(i)小目标容易在patch化后丢失细节;(ii)大目标的特征冗余严重。
核心做法分三步:
该变体仅使用对象标记进行 LLM 推理,借助对象中心信息融合模块(Object-Centric Infusion Module, OCI)将全局特征在前处理阶段融合入对象表示中。通过 Local-to-Object 和 Global-to-Object Attention,使目标的表征同时具备细节感知与全局语义,从而实现更完整的上下文融合。这样一来,推理阶段无需再使用全局视觉标记,显著降低显存与时间消耗,同时保持语义一致性与理解精度。

PixelRefer-Lite 实现了一个高效的推理框架,在保持高性能的同时将推理速度提升约 2–3 倍。
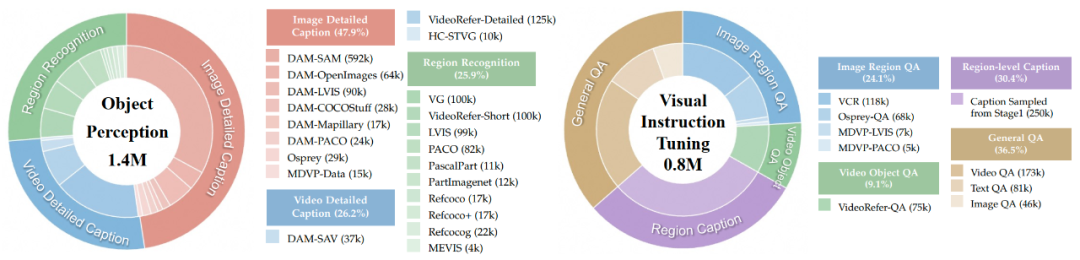
作者收集并开源了用于训练的两类数据集,分别是Foundational Object Perception(140万样本):涵盖物体、部件、时序关系的识别与描述以及Visual Instruction Tuning(80万样本):覆盖区域QA、视频QA、多对象关系与未来事件预测QA。
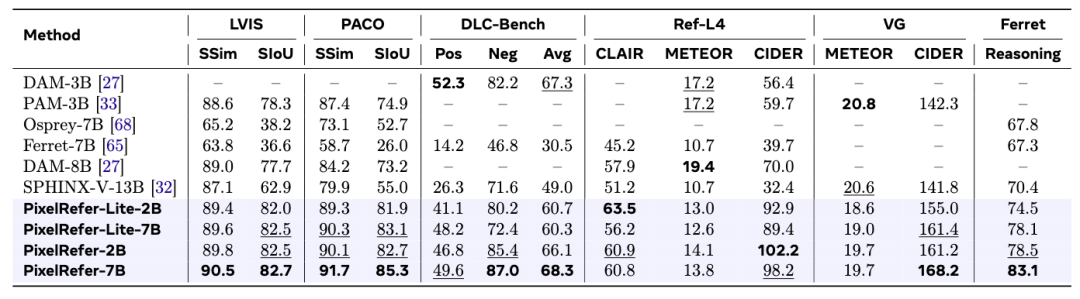
PixelRefer在多个图像理解benchmark上已达到SOTA水平,不论是简单的区域识别还是详细理解,已成为最先进的模型,特别是在reasoning场景下,更是展现出了突出优势。
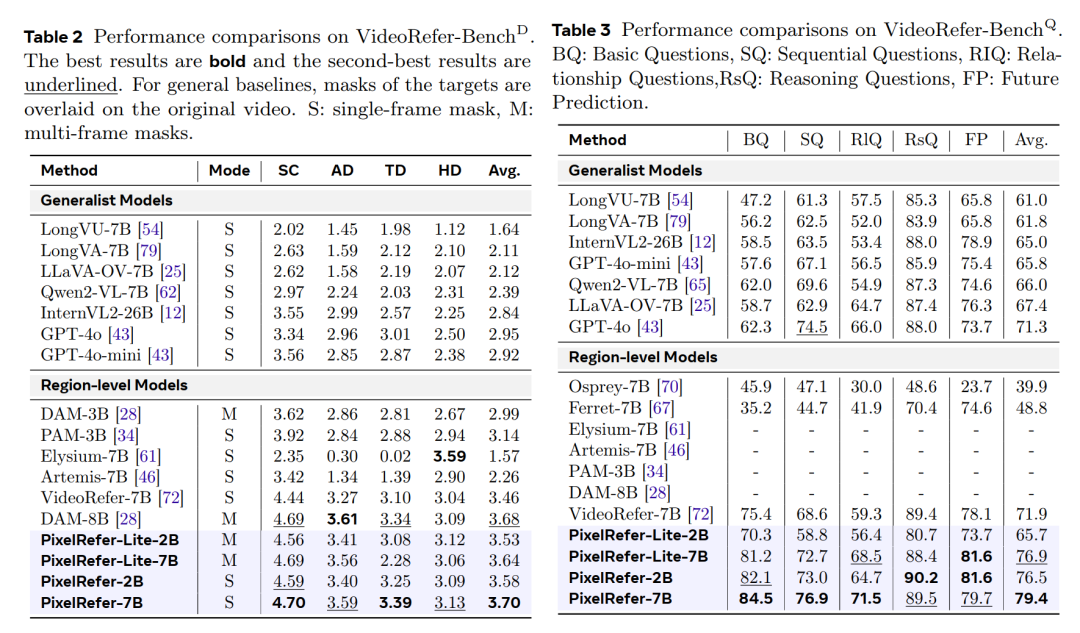
在经典的VideoRefer-Bench上,不论是视频区域的caption还是QA,均取得了领先性能,展现了通用而又全面的能力。
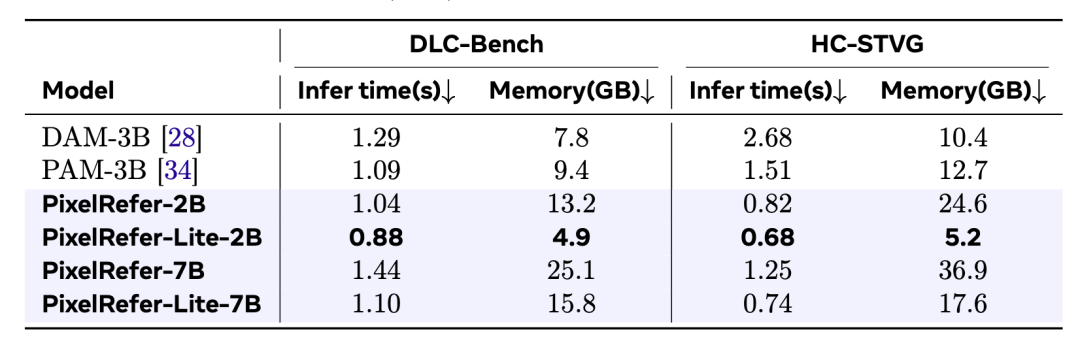
在基于图片的benchmark DLC-Bench和基于视频的benchmark上HC-STVG上均进行了测评,轻量版的PixelRefer-Lite-2B模型有较大的领先优势,特别是在视频上,相较于DAM-3B,推理时间缩短了约4倍,显存占用减少了2倍。
PixelRefer的出现,标志着AI视觉理解从“看懂一张图”迈向“理解世界的细节动态”,为多模态大模型的精细化视觉理解提供了新的方向。应用前景包括:
未来的多模态AI,不仅会“看见世界”,更会理解世界的关系。PixelRefer的提出,正是通向通用视觉智能的一块关键拼图。
文章来自于“机器之心”,作者 “机器之心”。



