
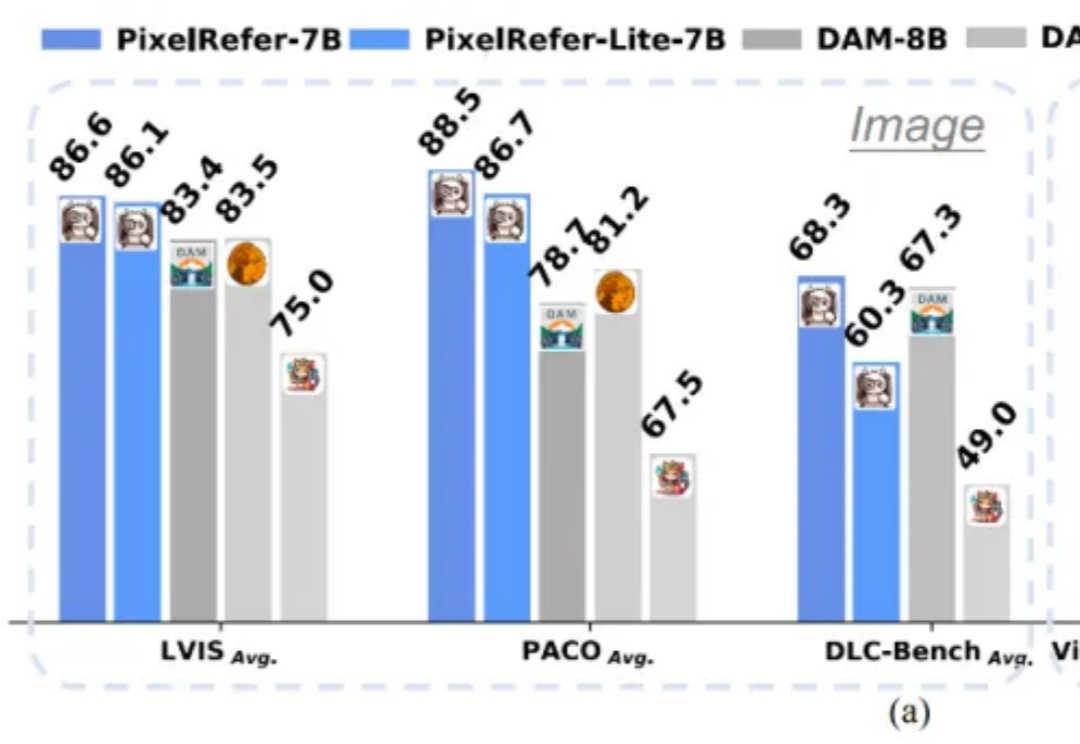
PixelRefer :让AI从“看大图”走向“看懂每个对象”
PixelRefer :让AI从“看大图”走向“看懂每个对象”多模态大模型(MLLMs)虽然在图像理解、视频分析上表现出色,但多停留在整体场景级理解。
来自主题: AI技术研报
10819 点击 2025-11-11 09:50
多模态大模型(MLLMs)虽然在图像理解、视频分析上表现出色,但多停留在整体场景级理解。

OpenAI要出手AI图像识别了。 最新消息,他们公司正在开发一种检测工具。 根据首席技术官Mira Murat透露: 该工具精度非常高,正确率可达99%。

金融科技公司Klarna推出”购物镜头“功能,计划与谷歌和亚马逊等推出类似AI产品的科技巨头一较高下