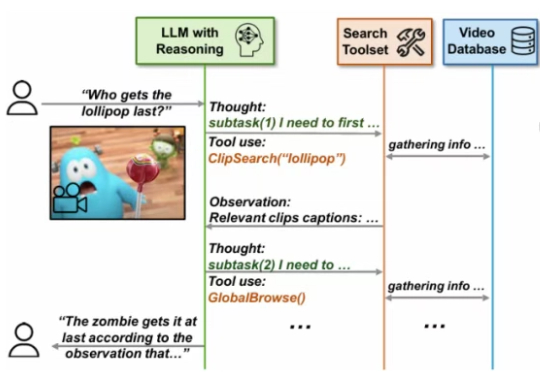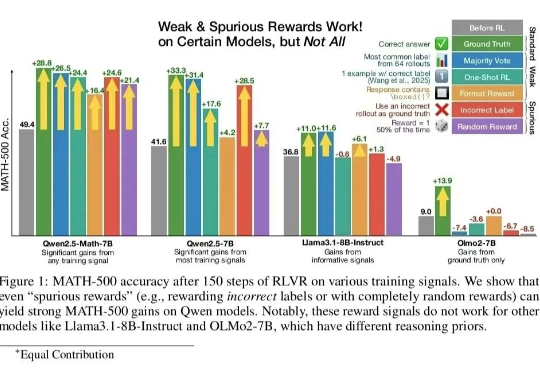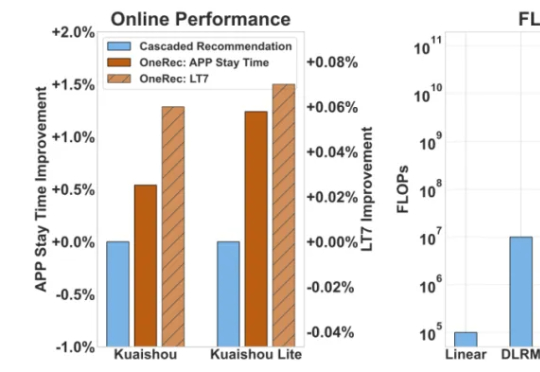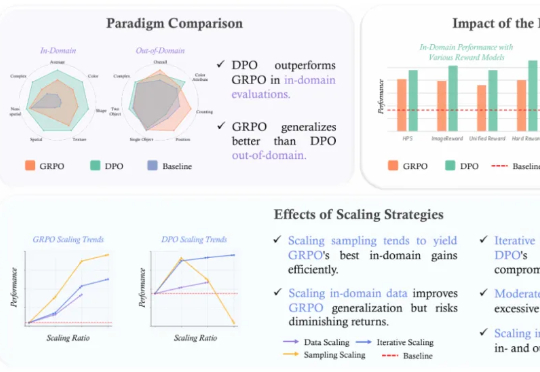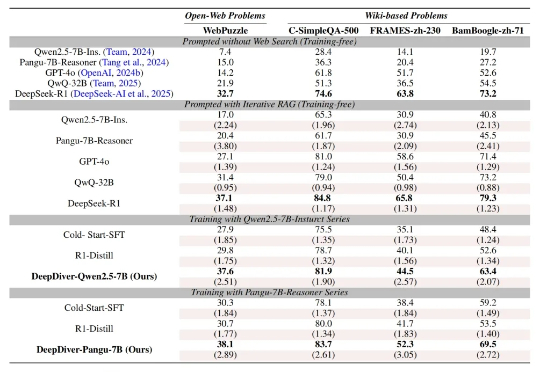
LeCun团队揭示LLM语义压缩本质:极致统计压缩牺牲细节
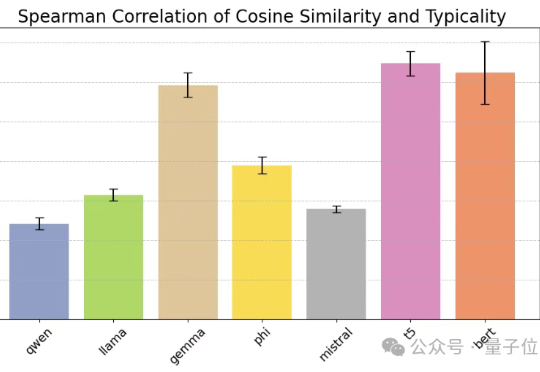
LeCun团队揭示LLM语义压缩本质:极致统计压缩牺牲细节那问题来了:大型语言模型(LLM)虽然语言能力惊人,但它们在语义压缩方面能做出和人类一样的权衡吗?为探讨这一问题,图灵奖得主LeCun团队,提出了一种全新的信息论框架。该框架通过对比人类与LLM在语义压缩中的策略,揭示了两者在压缩效率与语义保真之间的根本差异:LLM偏向极致的统计压缩,而人类更重细节与语境。
来自主题: AI技术研报
6413 点击 2025-07-06 11:17