
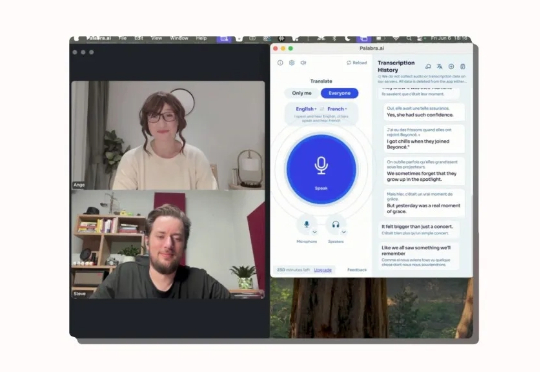
速递|Reddit创始人押注840万!Palabra攻克AI语音翻译“拟真实时”难题
速递|Reddit创始人押注840万!Palabra攻克AI语音翻译“拟真实时”难题一家名为Palabra AI 的初创公司正在开发 AI 语音翻译引擎,致力于解决教学大型语言模型(LLMs)理解多种语言这一颇具挑战性的难题。
来自主题: AI资讯
7805 点击 2025-08-16 15:43
一家名为Palabra AI 的初创公司正在开发 AI 语音翻译引擎,致力于解决教学大型语言模型(LLMs)理解多种语言这一颇具挑战性的难题。
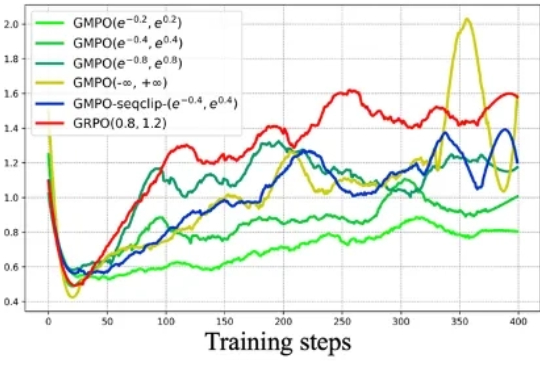
近年来,强化学习(RL)在大型语言模型(LLM)的微调过程中,尤其是在推理能力提升方面,取得了显著的成效。传统的强化学习方法,如近端策略优化(Proximal Policy Optimization,PPO)及其变种,包括组相对策略优化(Group Relative Policy Optimization,GRPO),在处理复杂推理任务时表现出了强大的潜力。
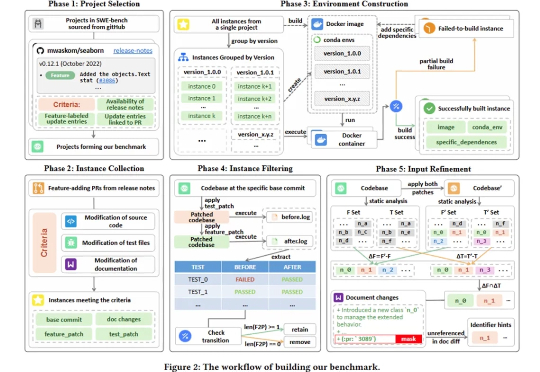
当前,大型语言模型(LLM)在软件工程领域的应用日新月异,尤其是在自动修复 Bug 方面,以 SWE-bench 为代表的基准测试展示了 AI 惊人的潜力。然而,软件开发远不止于修 Bug,功能开发与迭代才是日常工作的重头戏。
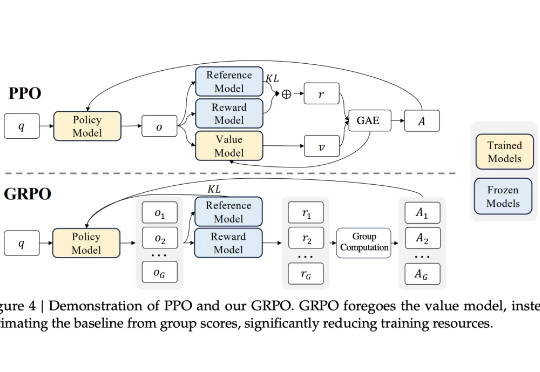
众所周知,大型语言模型的训练通常分为两个阶段。第一阶段是「预训练」,开发者利用大规模文本数据集训练模型,让它学会预测句子中的下一个词。第二阶段是「后训练」,旨在教会模型如何更好地理解和执行人类指令。
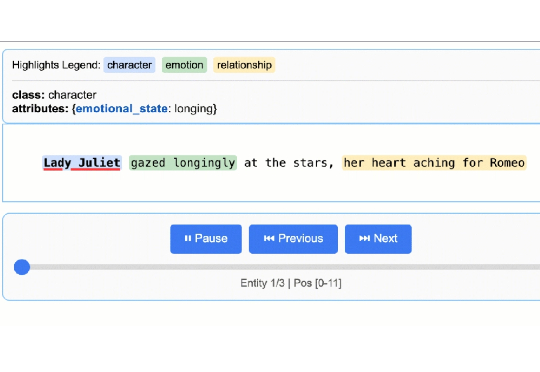
LangExtract 是一个 Python 库,利用大型语言模型(LLMs)从非结构化文本中提取结构化信息,基于用户定义的指令。它可以处理临床笔记或报告等材料,识别并组织关键细节,同时确保提取的数据与源文本对应。
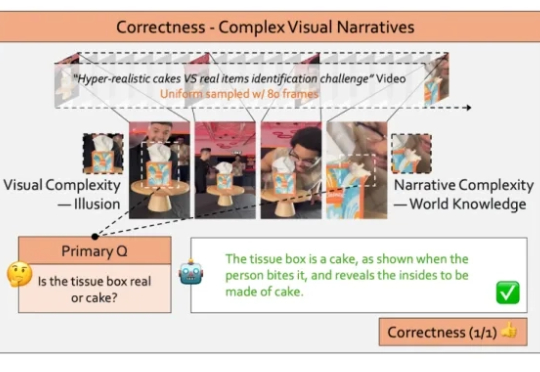
视频大型语言模型(Video LLMs)的发展日新月异,它们似乎能够精准描述视频内容、准确的回答相关问题,展现出足以乱真的人类级理解力。
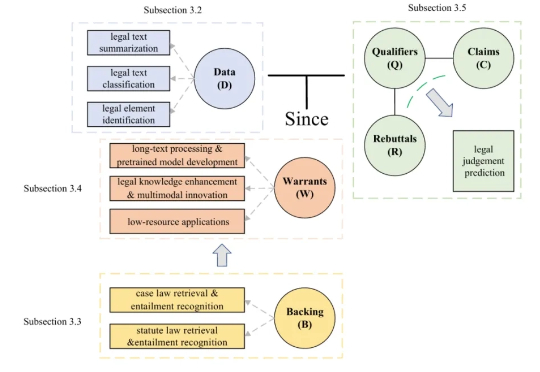
研究人员首次系统综述了大型语言模型(LLM)在法律领域的应用,提出创新的双重视角分类法,融合法律推理框架(经典的法律论证型式框架)与职业本体(律师/法官/当事人角色),统一梳理技术突破与伦理治理挑战。论文涵盖LLM在法律文本处理、知识整合、推理形式化方面的进展,并指出幻觉、可解释性缺失、跨法域适应等核心问题,为下一代法律人工智能奠定理论基础与实践路线图。
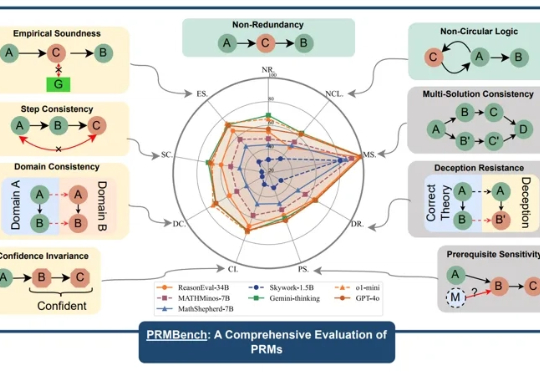
近年来,大型语言模型(LLMs)在复杂推理任务中展现出惊人的能力,这在很大程度上得益于过程级奖励模型(PRMs)的赋能。PRMs 作为 LLMs 进行多步推理和决策的关键「幕后功臣」,负责评估推理过程的每一步,以引导模型的学习方向。
我们知道,训练大模型本就极具挑战,而随着模型规模的扩大与应用领域的拓展,难度也在不断增加,所需的数据更是海量。大型语言模型(LLM)主要依赖大量文本数据,视觉语言模型(VLM)则需要同时包含文本与图像的数据,而在机器人领域,视觉 - 语言 - 行动模型(VLA)则要求大量真实世界中机器人执行任务的数据。

欧洲首款,不容易 CECP过的艰辛。