
民办大模型MiniMax努力专升本
民办大模型MiniMax努力专升本葬AI身边的朋友常常有个疑问:为什么MiniMax M3做的不够好(问了很多在做模型测评的朋友,也是类似看法),但市场仍然觉得他们是第一梯队?我朋友@朱亦辉的解释是,MiniMax M3的核心科技是叙事能力,让外界觉得他们和Kimi是一个级别,达到一个强行双骄的效果。
来自主题: AI资讯
10003 点击 2026-07-10 10:31
 搜索
搜索
葬AI身边的朋友常常有个疑问:为什么MiniMax M3做的不够好(问了很多在做模型测评的朋友,也是类似看法),但市场仍然觉得他们是第一梯队?我朋友@朱亦辉的解释是,MiniMax M3的核心科技是叙事能力,让外界觉得他们和Kimi是一个级别,达到一个强行双骄的效果。

由阿里巴巴集团孵化的空间智能企业“元境”,正在内测“JellyToken”,平台定位AI大模型一站式超市,支持一套密钥调用多款模型。该平台整合了Qwen3.7、Seedance2.0等多款国产大模型,面向个人创作者、中小团队、企业推出付费统一调用服务。
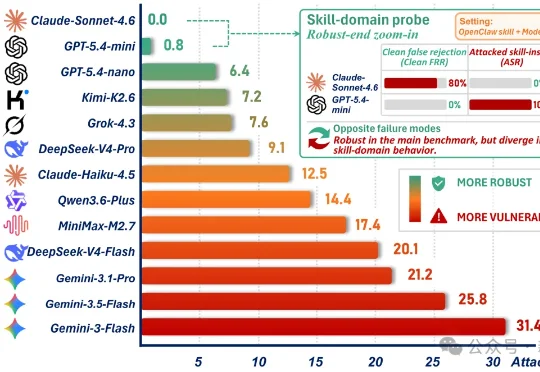
近日,来自KAUST生成式AI卓越中心、吉林大学、浙江大学、瑞士人工智能实验室等机构,由包括「现代人工智能之父」Jürgen Schmidhuber在内的研究者组成的团队,发布了一篇回答这个问题的研究论文。
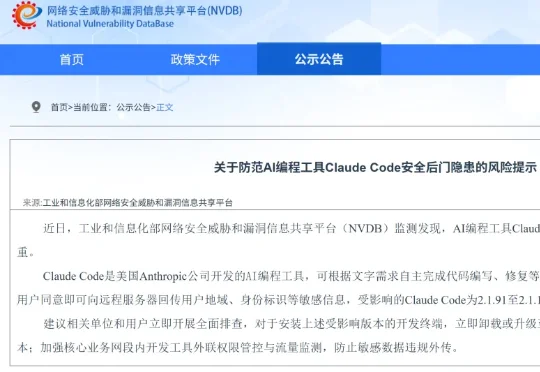
今日,工业和信息化部网络安全威胁和漏洞信息共享平台(NVDB)发布公告,其近日监测发现,美国AI大模型公司Anthropic旗下AI编程工具Claude Code存在安全后门隐患,该工具内置监控机制,可在未经用户同意的情况下向远程服务器回传用户地域、身份标识等敏感信息。工信部建议立即卸载相关受影响版本。

2026 年 6 月,HuggingFace 上一个名为 Boogu-Image-0.1 的开源模型,在上传以后迅速引爆了 AI 圈。这款模型最引人注目的地方,在于它以区区 10B 的参数规模,就在多项关键能力上超过了很多参数量更大的模型。

根据人社部启动了互联网企业云端招聘月活动的最新数据,今年暑假,超5000家互联网企业集中释放了超过20万个就业岗位。京东、腾讯、字节跳动、美团等头部企业合计贡献超4.6万个岗位,覆盖AI算法、大模型应用、高性能计算等前沿方向。

现在的 AI Agent 动辄需要处理超长上下文,既要看系统提示词、工具说明,又要翻阅历史对话和检索文档。为了省钱、省算力并降低延迟,很多开发者会给系统加上 “提示词压缩”(Prompt Compression)模块,把冗长的上下文浓缩后再喂给大模型。
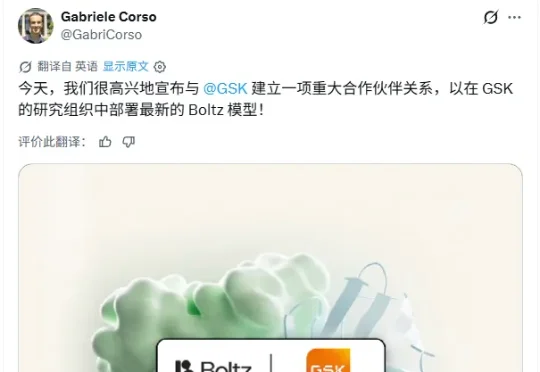
近日,Boltz的联合创始人Gabriele Corso表示,公司和葛兰素史克(GSK)已经达成了一笔深度合作。据悉,GSK的药物发现团队将直接访问Boltz最新的专有基础模型、Boltz Lab 和API接口,以及Agent集成。

浪潮信息宣布,元脑SD200超节点AI服务器率先完成主流领先开源大模型Kimi K2.6、DeepSeek V4、GLM 5.2、MiniMax M3等的高性能优化,并在Kimi K2.6万亿参数大模型上实现Token生成时间快达4.77ms,为Agent场景应用的高效运行提供强大算力支撑。
2023 年大模型刚火的时候,浏览器被认为是 AI 时代最值得抢的入口,用AI颠覆Chrome是大家都能看到的百亿创业项目。实在是这个入口太大了。全球互联网用户已经是 60 亿量级,Chrome 一个产品就是三十亿级用户;Safari 靠 iPhone、iPad 和 Mac 占住十亿级设备入口,Edge 背后是 Windows 和微软账号体系。