字节AI大牛顾全全宣布离职,或投身AI4S创业
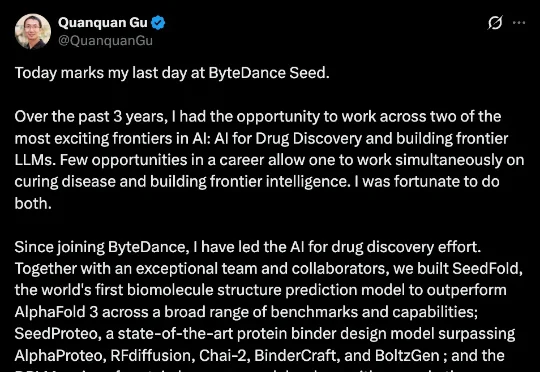
字节AI大牛顾全全宣布离职,或投身AI4S创业刚刚,顾全全发文告别字节 Seed 团队。在此之前,他是 Seed 旗下聚焦科学智能领域的 AI4S 团队核心成员。顾全全是机器学习理论、大模型对齐以及 AI4S 科学智能领域知名的学者。他于 2007 年和 2010 年分获清华大学自动化专业学士、控制科学与工程硕士学位,2014 年获伊利诺伊大学香槟分校计算机科学博士学位,随后在普林斯顿大学运筹与金融工程系(ORFE)开展统计学博士后研究。
来自主题: AI资讯
7993 点击 2026-06-02 16:18