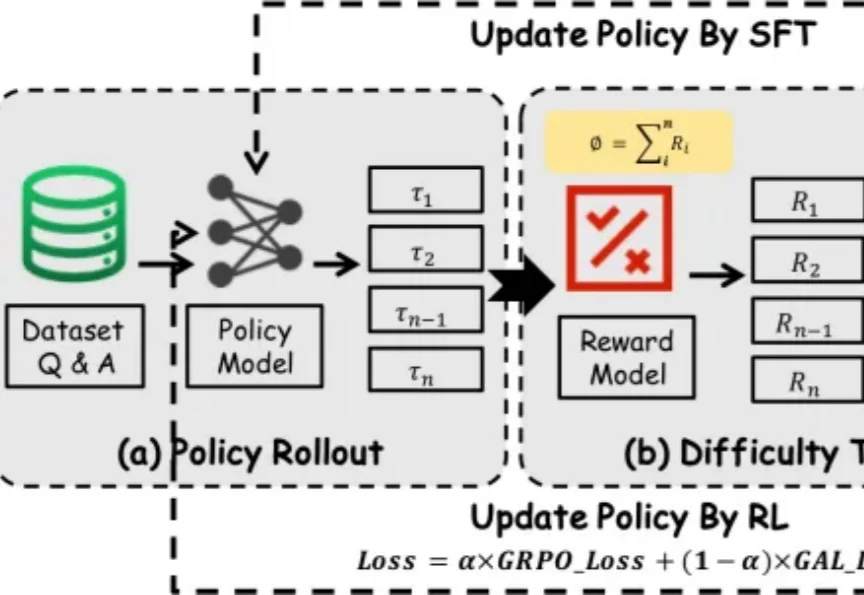
当SFT遇上RL:基于样本学习阶段的动态策略优化机制
当SFT遇上RL:基于样本学习阶段的动态策略优化机制过去一段时间里,在围绕大模型推理能力增强的研究中,SFT 和 RL 是两类核心后训练范式 —— 前者稳定收敛快,能高效吸收高质量推理数据;后者更具探索性,有望推动模型实现复杂推理和分布外泛化。
来自主题: AI技术研报
6807 点击 2026-05-18 09:53
 搜索
搜索
过去一段时间里,在围绕大模型推理能力增强的研究中,SFT 和 RL 是两类核心后训练范式 —— 前者稳定收敛快,能高效吸收高质量推理数据;后者更具探索性,有望推动模型实现复杂推理和分布外泛化。

在多模态大模型(MLLM)快速发展的浪潮中,融合多模型 “集体智慧” 已成为提升模型性能的关键路径,并催生了多教师知识蒸馏这一主流范式。然而,不同来源的教师模型在架构与优化上的差异,其在相似推理过程中呈现出不稳定甚至偏移的认知轨迹,即 “概念漂移”(Concept Drift)。

如果你让大模型给林黛玉找一个外国文学里的平替,它能给出令人信服的答案吗?这个脑洞的背后其实是当下人工智能最核心的软肋——“类比推理”能力。

智能体时代的核心是算力。

在 AI 工程界,长文本推理一直是个“富贵病”。

ZP独家获悉,AI芯片及系统架构研发商“上海昉擎科技”于近日完成 Pre-A3 轮融资,新引入投资人国开科创、钧山资本、建发新兴投资、多维资本,多维资本担任本轮融资财务顾问并担任后续融资独家财务顾问。
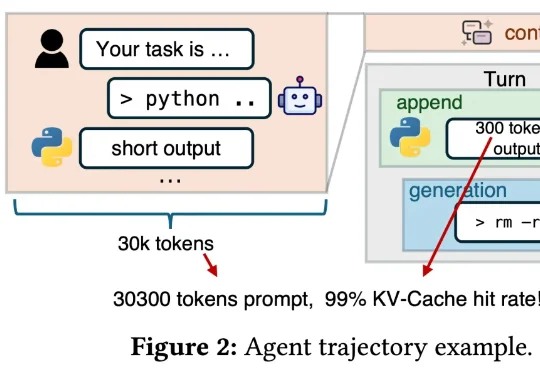
「DeepSeek V4 来了!」这样的消息是不是已经听烦了?总结来说,这篇新论文介绍了一个名为「DualPath」的创新推理系统,专门针对智能体工作负载下的大语言模型(LLM)推理性能进行优化。具体来讲,通过引入「双路径 KV-Cache 加载」机制,解决了在预填充 - 解码(PD)分离架构下,KV-Cache 读取负载不平衡的问题。
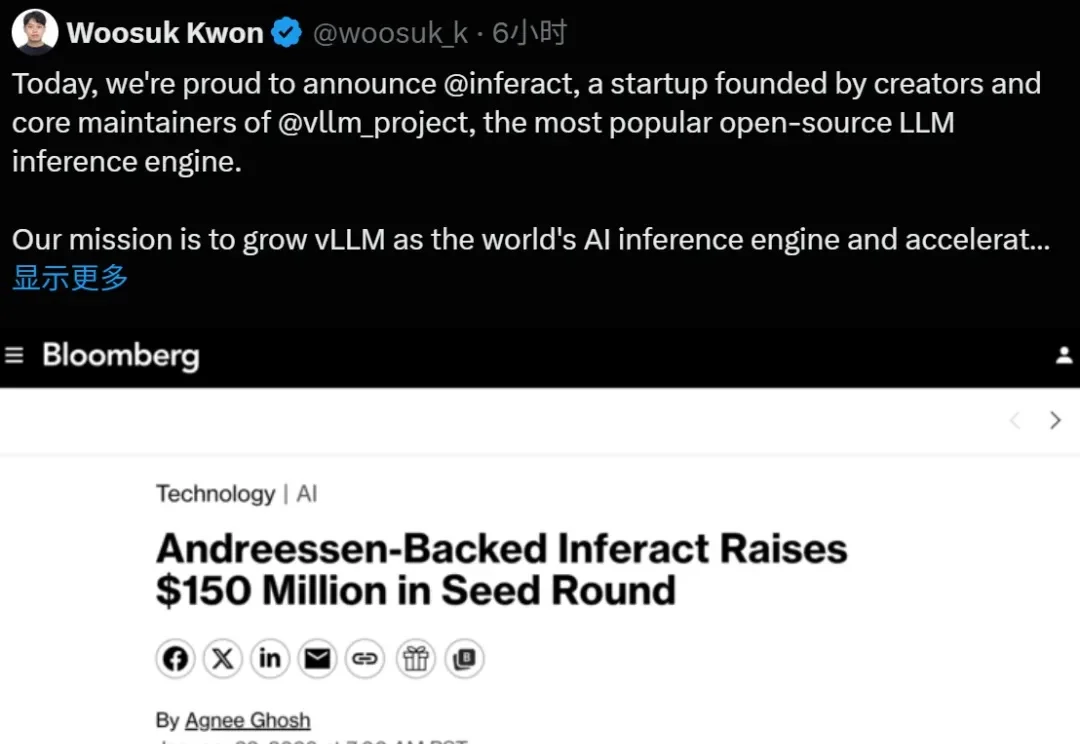
大模型推理的基石 vLLM,现在成为创业公司了。

“与AGI太过遥远的炒作相比,我非常喜欢这种 3 到 5 年的时间窗口。”“AI 现在最大的问题,已经不是不够聪明,而是太难真正落地。”这些非常务实的观点,并不是出自AI怀疑论者。相反,它出自硅谷圈内那位“工程与学术”的双修神话:

大模型推理的爆发,实际源于 scaling 范式的转变:从 train-time scaling 到 test-time scaling(TTS),即将更多的算力消耗部署在 inference 阶段。典型的实现是以 DeepSeek r1 为代表的 long CoT 方法:通过增加思维链的长度来获得答案精度的提升。那么 long CoT 是 TTS 的唯一实现吗?