Deepmind 重磅开源:消除幻觉,让 LLMs 学会规则库和多步推理
Deepmind 重磅开源:消除幻觉,让 LLMs 学会规则库和多步推理大模型的的发布固然令人欣喜,但是各类测评也是忙坏了众多 AI 工作者。大模型推理的幻觉问题向来是 AI 测评的重灾区,诸如 9.9>9.11 的经典幻觉问题,各大厂家恨不得直接把问题用 if-else 写进来。
来自主题: AI技术研报
9267 点击 2024-12-30 10:39
 搜索
搜索
大模型的的发布固然令人欣喜,但是各类测评也是忙坏了众多 AI 工作者。大模型推理的幻觉问题向来是 AI 测评的重灾区,诸如 9.9>9.11 的经典幻觉问题,各大厂家恨不得直接把问题用 if-else 写进来。
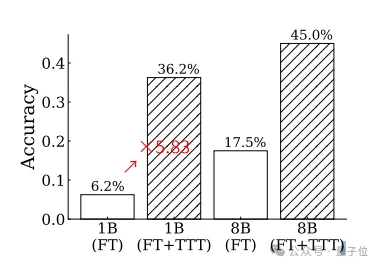
o1不是通向大模型推理的唯一路径! MIT的新研究发现,在测试时对大模型进行训练,可以让推理水平大幅提升。

改进KV缓存压缩,大模型推理显存瓶颈迎来新突破—— 中科大研究团队提出Ada-KV,通过自适应预算分配算法来优化KV缓存的驱逐过程,以提高推理效率。

PPIO推出新AI产品,助力分布式云计算及AIGC应用。
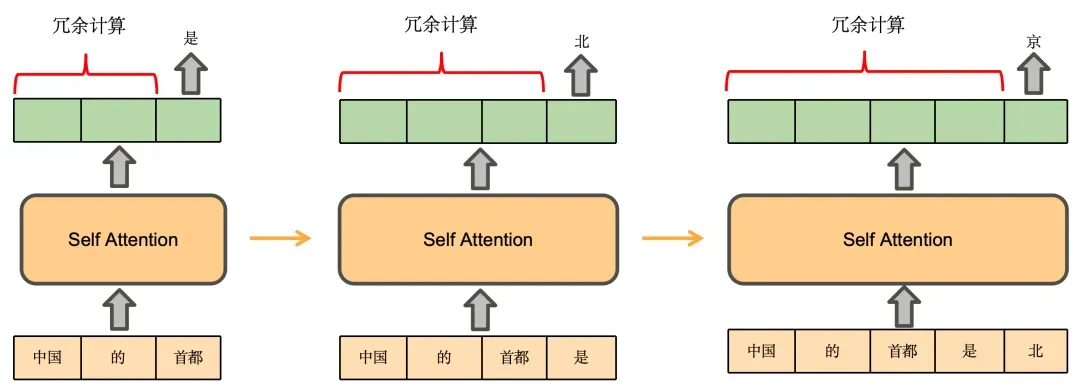
KV Cache 是大模型推理性能优化的一个常用技术,该技术可以在不影响任何计算精度的前提下,通过空间换时间的思想,提高推理性能。

2024年,落地,无疑是大模型最重要的主题。

千亿参数规模的大模型推理,服务器仅用4颗CPU就能实现!

最近,新加坡国立大学联合南洋理工大学和哈工深的研究人员共同提出了一个全新的视频推理框架,这也是首次大模型推理社区提出的面向视频的思维链框架(Video-of-Thought, VoT)。视频思维链VoT让视频多模态大语言模型在复杂视频的理解和推理性能上大幅提升。该工作已被ICML 2024录用为Oral paper。
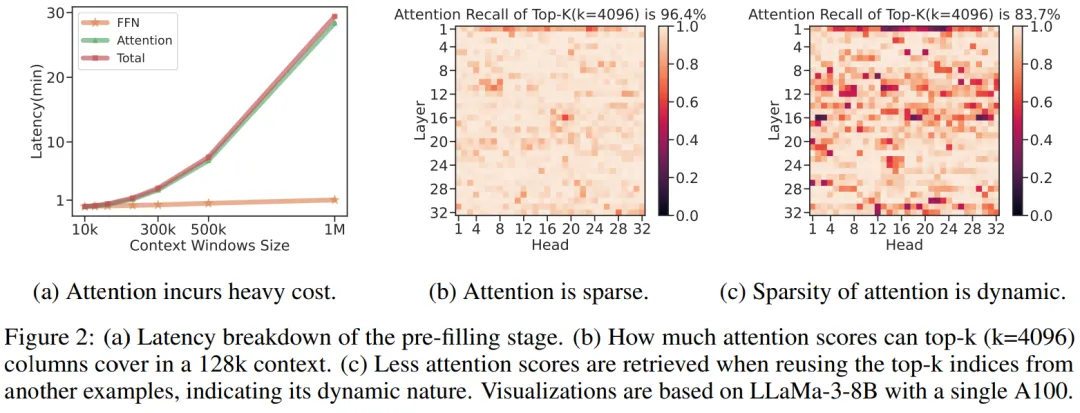
微软的这项研究让开发者可以在单卡机器上以 10 倍的速度处理超过 1M 的输入文本。

如何在有限的内存下实现高效的大模型推理,是端侧AI发展的重要任务。