
国产之光DeepSeek把AI大佬全炸出来了!671B大模型训练只需此前算力1/10,细节全公开
国产之光DeepSeek把AI大佬全炸出来了!671B大模型训练只需此前算力1/10,细节全公开DeepSeek新版模型正式发布,技术大佬们都转疯了! 延续便宜大碗特点的基础之上,DeepSeek V3发布即完全开源,直接用了53页论文把训练细节和盘托出的那种。
来自主题: AI技术研报
8252 点击 2024-12-28 11:19
 搜索
搜索
DeepSeek新版模型正式发布,技术大佬们都转疯了! 延续便宜大碗特点的基础之上,DeepSeek V3发布即完全开源,直接用了53页论文把训练细节和盘托出的那种。

枢途科技(深圳)有限公司(以下简称「枢途科技」)近日完成数百万元天使轮融资,本轮由奇绩创坛投资,主要用于多模态大模型训练迭代、通用复合机器人结构升级等技术与产品的研发和交付。

只要改一行代码,就能让大模型训练效率提升至1.47倍。

网络智能体旨在让一切基于网络功能的任务自动发生。比如你告诉智能体你的预算,它可以帮你预订酒店。既拥有海量常识,又能做长期规划的大语言模型(LLM),自然成为了智能体常用的基础模块。

近年来,大语言模型(Large Language Models, LLMs)的研究取得了重大进展,并对各个领域产生了深远影响。然而,LLMs的卓越性能来源于海量数据的大规模训练,这导致LLMs的训练成本明显高于传统模型。

内存占用小,训练表现也要好……大模型训练成功实现二者兼得。 来自北理、北大和港中文MMLab的研究团队提出了一种满足低秩约束的大模型全秩训练框架——Fira,成功打破了传统低秩方法中内存占用与训练表现的“非此即彼”僵局。

最近,大模型训练遭恶意攻击事件已经刷屏了。就在刚刚,Anthropic也发布了一篇论文,探讨了前沿模型的巨大破坏力,他们发现:模型遇到危险任务时会隐藏真实能力,还会在代码库中巧妙地插入bug,躲过LLM和人类「检查官」的追踪!
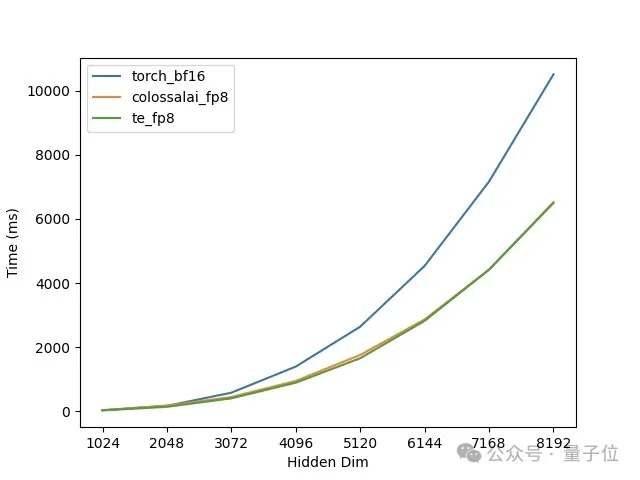
FP8通过其独特的数值表示方式,能够在保持一定精度的同时,在大模型训练中提高训练速度、节省内存占用,最终降低训练成本。
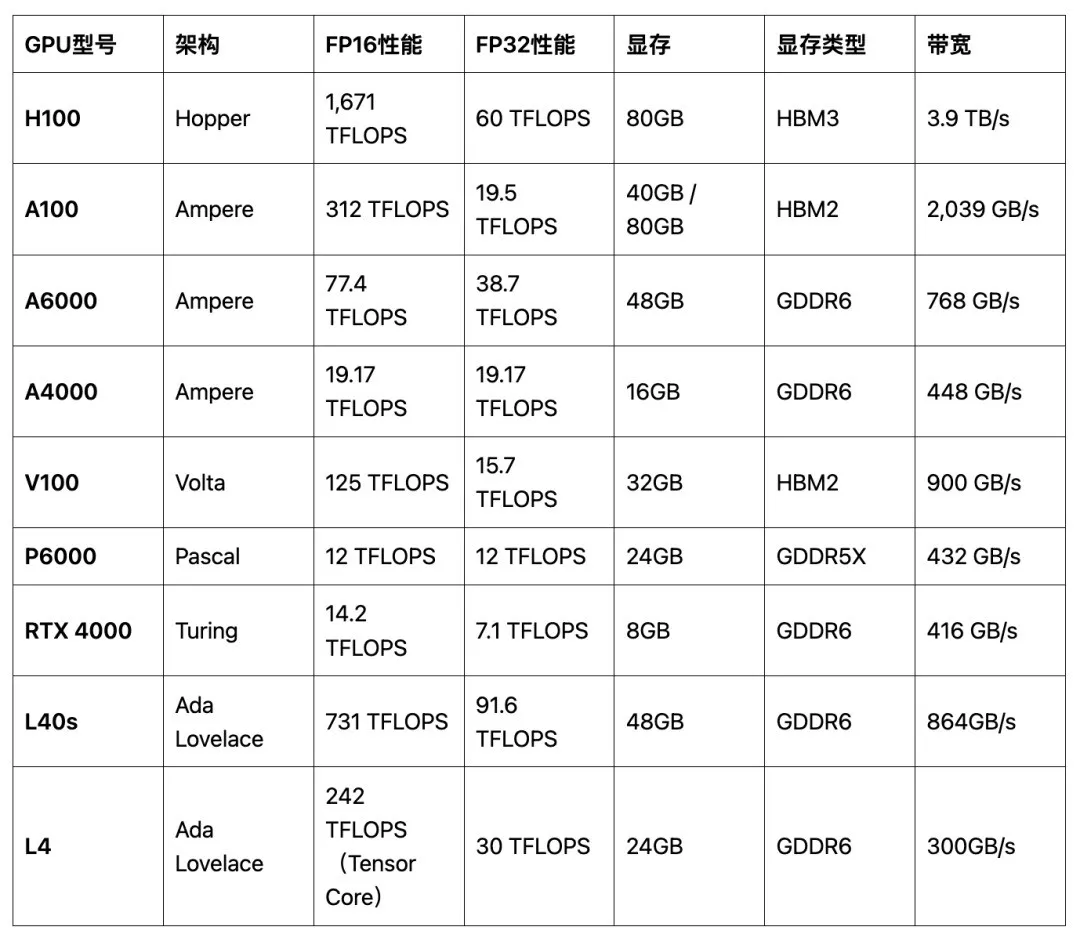
在 AI 领域,有两大场景对 GPU 的需求最大,一个是模型训练,另一个是 AI 推理任务。

越来越多人开始关注大模型,很多做工程开发的同学问我怎么入门大模型训练推理系统软件(俗称大模型Infra)。