
ZOMI酱:从艺术生到大模型训练专家
ZOMI酱:从艺术生到大模型训练专家技术阿甘在不停奔跑。
来自主题: AI资讯
9299 点击 2024-04-11 16:15
 搜索
搜索
技术阿甘在不停奔跑。

中国电子学会 2023 科学技术奖授奖名单公布,这次,我们发现了一个熟悉的身影 —— 腾讯 Angel 机器学习平台。

基于大模型的Agent,已经成为了大型的博弈游戏的高级玩家,而且玩的还是德州扑克、21点这种非完美信息博弈。

众所周知,开发顶级的文生图(T2I)模型需要大量资源,因此资源有限的个人研究者基本都不可能承担得起,这也成为了 AIGC(人工智能内容生成)社区创新的一大阻碍。同时随着时间的推移,AIGC 社区又能获得持续更新的、更高质量的数据集和更先进的算法。

对大模型进行量化、剪枝等压缩操作,是部署时最常见不过的一环了。

近期,清华大学和哈尔滨工业大学联合发布了一篇论文:把大模型压缩到 1.0073 个比特时,仍然能使其保持约 83% 的性能!

继 2023 年 1 月 YOLOv8 正式发布一年多以后,YOLOv9 终于来了!

造大模型的成本,又被打下来了!这次是数据量狂砍95%的那种。陈丹琦团队最新提出大模型降本大法——数据选择算法LESS, 只筛选出与任务最相关5%数据来进行指令微调,效果比用整个数据集还要好。
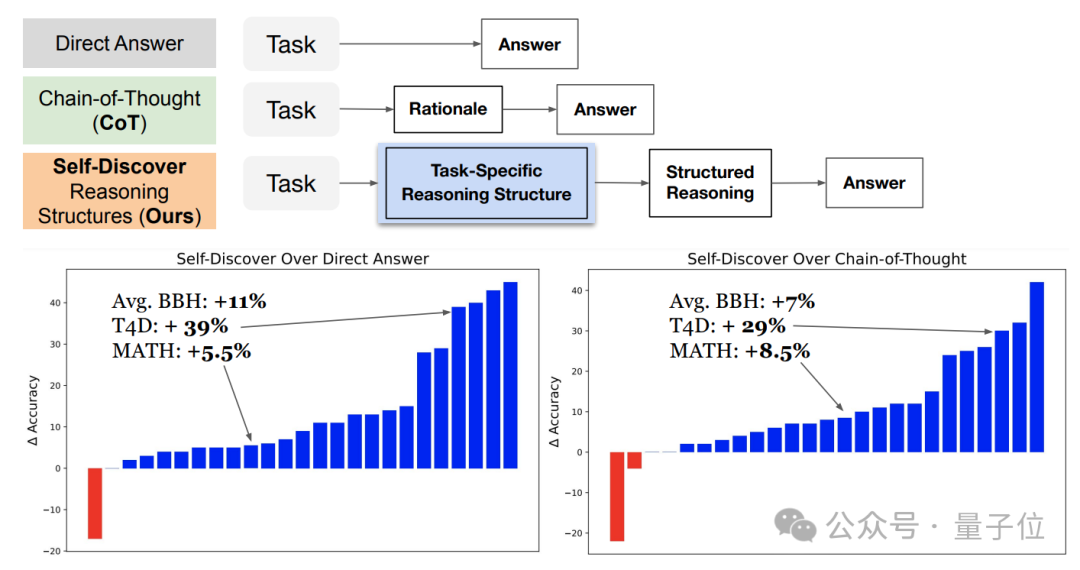
谷歌&南加大推出最新研究“自我发现”(Self-Discover),重新定义了大模型推理范式。与已成行业标准的思维链(CoT)相比,新方法不仅让模型在面对复杂任务时表现更佳,还把同等效果下的推理成本压缩至1/40。

现有的语义分割技术在评估指标、损失函数等设计上都存在缺陷,研究人员针对相关缺陷设计了全新的损失函数、评估指标和基准,在多个应用场景下展现了更高的准确性和校准性。