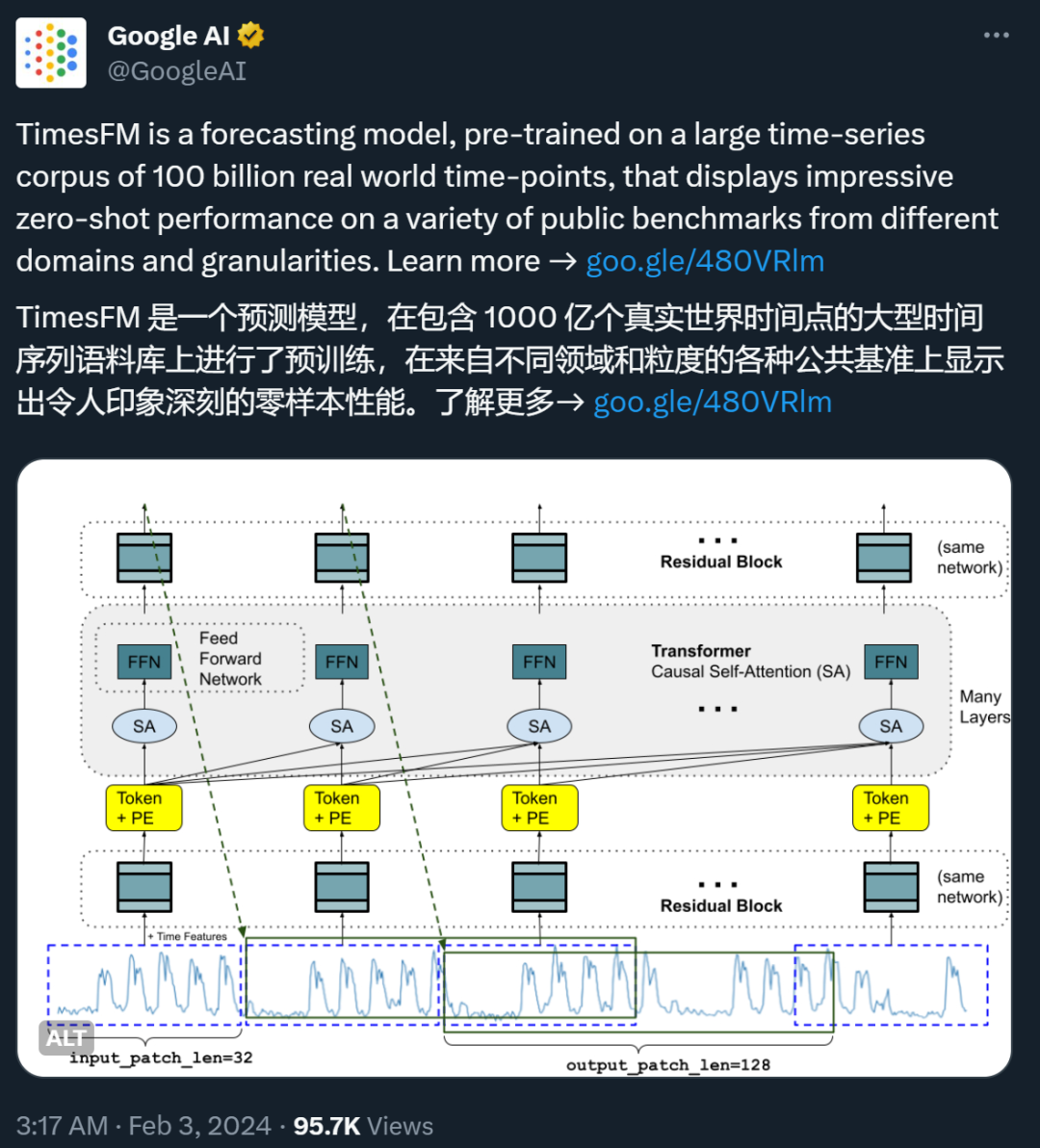
2亿参数时序模型替代LLM?谷歌突破性研究被批「犯新手错误」
2亿参数时序模型替代LLM?谷歌突破性研究被批「犯新手错误」最近,谷歌的一篇论文在 X 等社交媒体平台上引发了一些争议。
来自主题: AI技术研报
8997 点击 2024-02-05 14:33
 搜索
搜索
最近,谷歌的一篇论文在 X 等社交媒体平台上引发了一些争议。

来自UCLA的华人团队提出一种全新的LLM自我对弈系统,能够让LLM自我合成数据,自我微调提升性能,甚至超过了用GPT-4作为专家模型指导的效果。

不用图像,只用文本就能训练出视觉概念表征?用写代码的方式读懂画面,形状、物体、场景都能懂!

使用LLM生成海量任务的文本数据,无需人工标注即可大幅提升文本嵌入的适用度,只需1000训练步即可轻松扩展到100种语言。
在认知科学领域,人类通过持续学习改变认知的过程被称为认知迭代(Cognitive Dynamics)。形象地说,认知迭代就像是我们大脑的「软件更新」过程,手机应用通过不断的更新来修复 bug 和增加新功能,我们的大脑也通过不断学习新知识、经验,来改善和优化思考方式。

美国计划限制中国客户使用美国云计算厂商的服务训练AI大模型,对中国人工智能产业造成潜在破坏。本文分析了中国科技行业追赶的三个因素。

如果语言模型是巫师,代码预训练就是魔杖!

想要AI生成更长的视频?现在,有人提出了一个效果很不错的免调优方法,直接就能作用于预训练好的视频扩散模型。

本文对思维链的推理步长进行了控制变量实验,发现推理步长和答案的准确性是线性相关的,这种影响机制甚至超越了问题本身所产生的差异。

目标跟踪是计算机视觉的一项基础视觉任务,由于计算机视觉的快速发展,单模态 (RGB) 目标跟踪近年来取得了重大进展。考虑到单一成像传感器的局限性,我们需要引入多模态图像 (RGB、红外等) 来弥补这一缺陷,以实现复杂环境下全天候目标跟踪。