符尧:别卷大模型训练了,来卷数据吧!【干货十足】
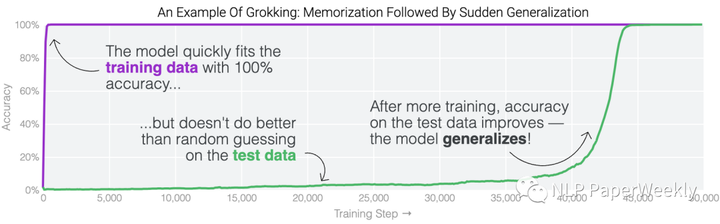
符尧:别卷大模型训练了,来卷数据吧!【干货十足】今天分享一篇符尧大佬的一篇数据工程(Data Engineering)的文章,解释了speed of grokking指标是什么,分析了数据工程
来自主题: AI资讯
10034 点击 2024-01-02 11:13
 搜索
搜索
今天分享一篇符尧大佬的一篇数据工程(Data Engineering)的文章,解释了speed of grokking指标是什么,分析了数据工程
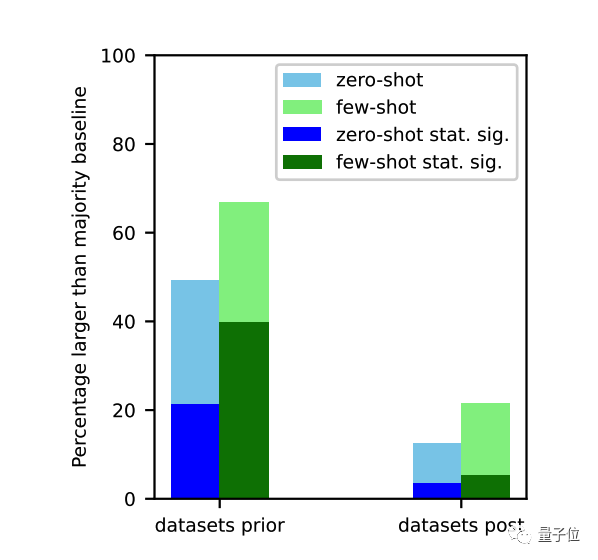
对于ChatGPT变笨原因,学术界又有了一种新解释。加州大学圣克鲁兹分校一项研究指出:在训练数据截止之前的任务上,大模型表现明显更好。

国内首个以国产全功能GPU为底座的大规模算力集群,正式落地了!这便是来自摩尔线程的KUAE智算中心,全国产千卡千亿模型训练平台。

本文探讨了AI对齐在OpenAI公司中被忽视的一部分,以及AI对齐在大模型训练中的重要性和影响。文章揭示了OpenAI内部因AI对齐而产生的分歧,并阐述了AI对齐在保证AI按照人类意图和价值观运作方面的作用。同时,文章指出AI对齐在大模型训练中存在的性能阉割和对齐税等问题,以及AI对齐在大模型发展中的隐藏模型和重要性。
英伟达老黄,带着新一代GPU芯片H200再次炸场。官网毫不客气就直说了,“世界最强GPU,专为AI和超算打造”。
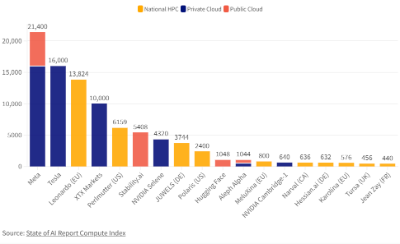
在高性能计算(HPC)、人工智能(AI)、和数据分析等领域,图形处理器(GPUs)正在发挥越来越重要的作用。其中,NVIDIA的 A100尤为引人注目。这是英伟达最强大的显卡处理器,也是当前使用最广泛大模型训练用的显卡。