
AI与职业这三年:震荡、规律与职业群像
AI与职业这三年:震荡、规律与职业群像2023年春天,一份来自OpenAI的研究论文让“暴露度”这个词进入公众视野。论文用大语言模型的能力去匹配美国劳工部近千个职业的任务描述,得出一份风险排序:数学家、报税员、量化分析师、作家、网页设计师排在前面,编程与写作技能的暴露度接近100%。
来自主题: AI资讯
7060 点击 2026-07-15 11:10
 搜索
搜索
2023年春天,一份来自OpenAI的研究论文让“暴露度”这个词进入公众视野。论文用大语言模型的能力去匹配美国劳工部近千个职业的任务描述,得出一份风险排序:数学家、报税员、量化分析师、作家、网页设计师排在前面,编程与写作技能的暴露度接近100%。
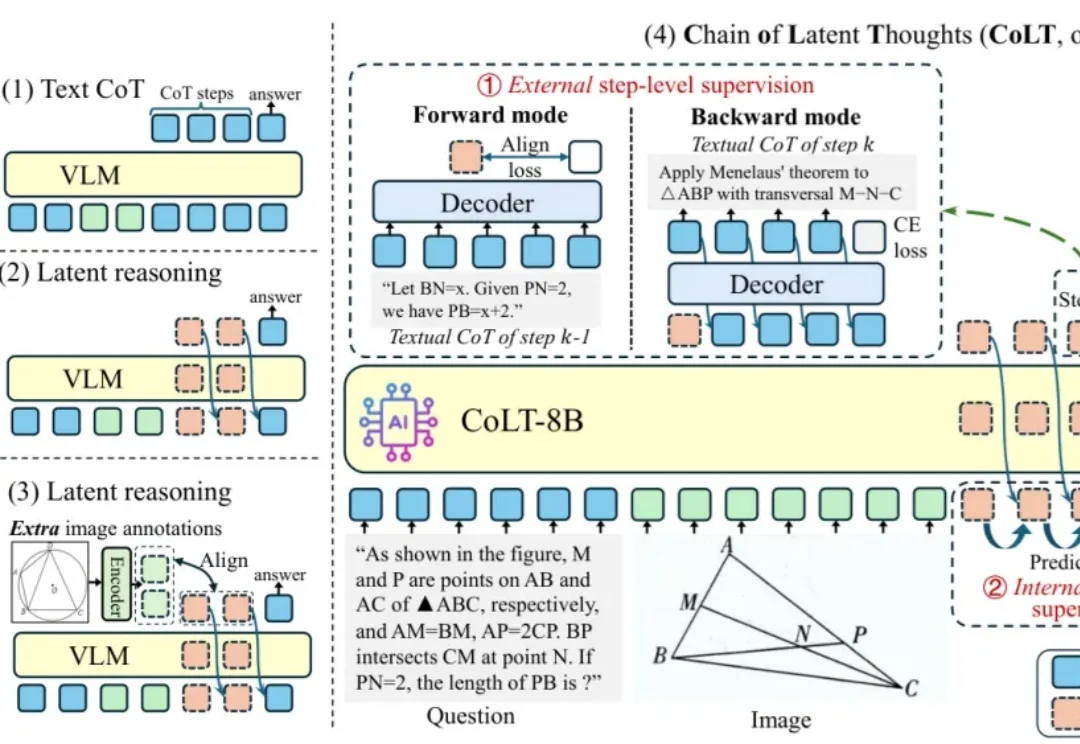
近年来,多模态大语言模型(MLLM)在视觉问答、图表理解、科学推理等任务上取得了令人瞩目的进展。
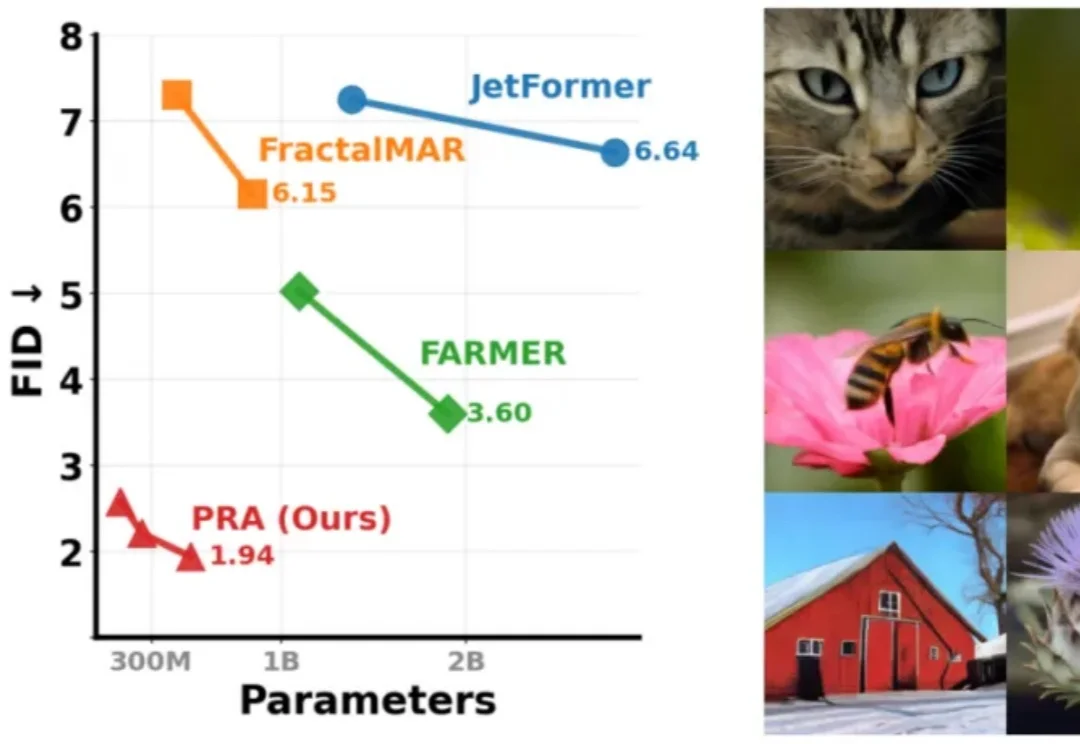
过去几年,扩散模型几乎定义了高质量图像生成:从随机噪声出发,经过多轮迭代,逐步 “雕刻” 出一张图像。但随着大语言模型席卷人工智能领域,另一条路线正迅速走到舞台中央 —— 图像,能否也像语言一样,通过自回归方式逐步生成?
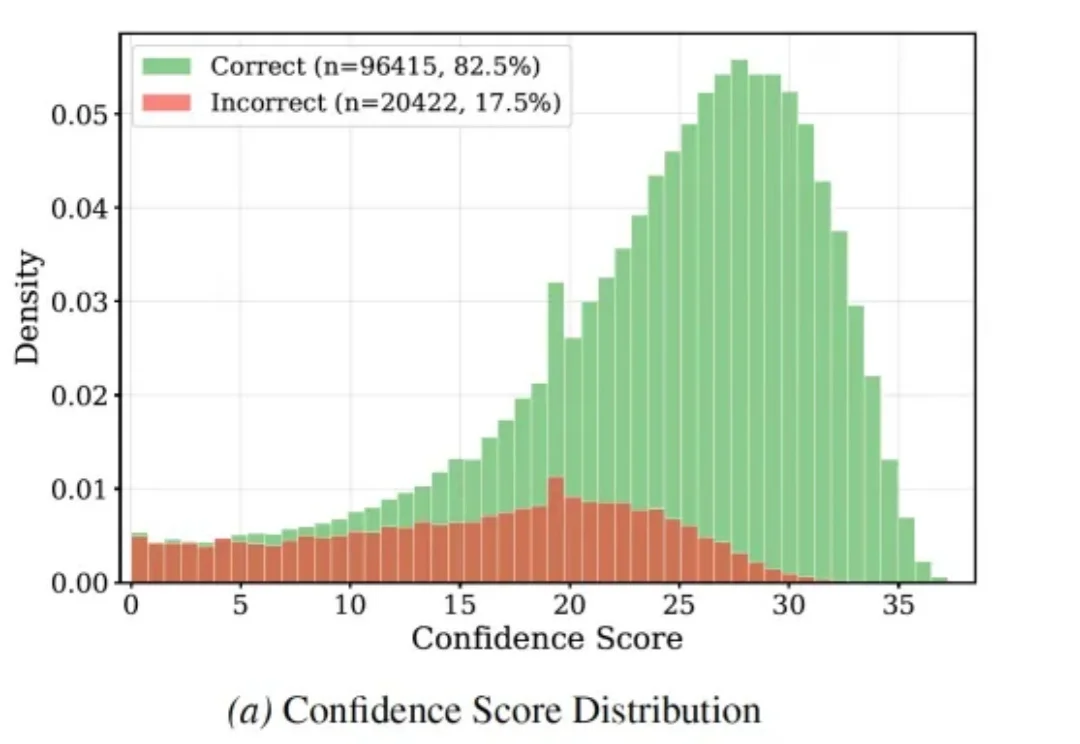
奖励模型(Reward Model, RM)是大语言模型对齐的核心组件,负责为模型输出提供符合人类偏好的评价信号。现有方法各有短板:标量判别式 RM 高效稳定但可解释性有限;生成式 judge 能给出判断理由,却需为每个样本生成长 reasoning,token 与延迟开销显著。

过去几年,大语言模型几乎成为了AI的代名词。从ChatGPT到Google DeepMind推出的Gemini,从Anthropic开发的Claude到中国的DeepSeek,人们讨论更多的是聊天机器人、推理能力和生成内容。但如果问Google DeepMind CEO、2024年诺贝尔化学奖得主Demis Hassabis(下简称“哈萨比斯”)
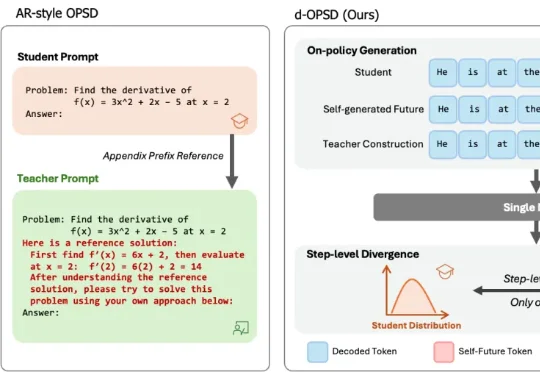
有没有一种更为合适的 OPSD 范式?近期,清华大学和马普所等机构的研究者们联合推出的 d-OPSD,给这一问题提供了完美的答案。这是第一个针对扩散大语言模型的 OPSD 范式,无需参考解,无需额外的教师模型,只需要 RL 十分之一的训练步数,便可以达到或超出 RL 的后训练效果。

据 The Information 报道,MiniMax 正在研发一款参数规模达 2.7 万亿的大语言模型,内部代号暂定为 M3 Pro,最快有望于今年第三季度发布,并计划同步开源。相较于现有旗舰模型 M3 的 4280 亿参数,M3 Pro 的规模实现了数量级跃升,预计将在复杂推理、多步骤任务处理及长上下文理解等能力上进一步增强。
智东西获悉,OpenAI前研究员田永龙(Yonglong Tian)已确认于近期加入腾讯大语言模型部,后续将参与VLM(视觉语言模型)相关研发。在OpenAI期间,田永龙曾参与GPT-5的研发工作。加入OpenAI之前,他在Google Research和DeepMind长期从事视觉表征学习和对比学习等方向研究,对后续视觉模型以及多模态表征学习的发展产生了广泛影响。
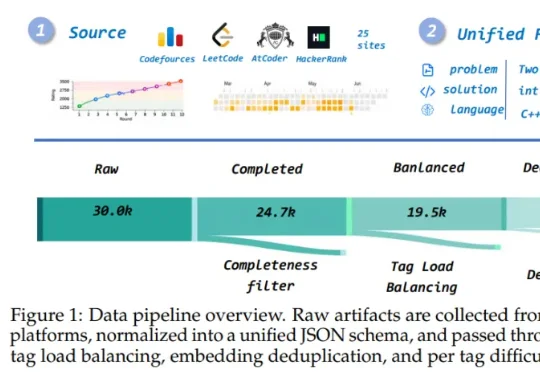
大语言模型在代码生成上的能力不断增强,但在复杂算法题,尤其是竞赛编程场景中,仍然容易因为算法选择错误、边界条件遗漏、复杂度判断失误或隐藏测试覆盖不足而失败。Solvita是一款面向竞赛编程的智能体框架,通过四个角色(Planner、Solver、Oracle、Hacker)形成闭环系统,并利用可训练的图结构知识网络积累经验。

「不如直接数字人」 私以为,世界模型这个概念的发展经过了三个非常幽默的阶段。 第一阶段:硅谷真懂行的老登如杨立昆、李飞飞,觉得大语言模型在讲故事上没啥空间了,所以从学术圈拽了个新概念过来尝试弯道超车。