长文本向量模型在4K Tokens 之外形同盲区?
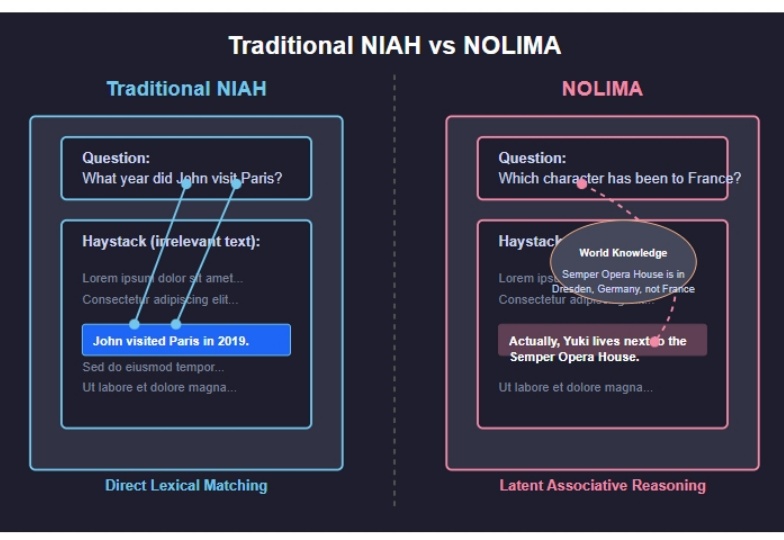
长文本向量模型在4K Tokens 之外形同盲区?2025 年 2 月发布的 NoLiMA 是一种大语言模型(LLM)长文本理解能力评估方法。不同于传统“大海捞针”(Needle-in-a-Haystack, NIAH)测试依赖关键词匹配的做法,它最大的特点是 通过精心设计问题和关键信息,迫使模型进行深层语义理解和推理,才能从长文本中找到答案。
来自主题: AI技术研报
6367 点击 2025-03-12 15:08
 搜索
搜索
2025 年 2 月发布的 NoLiMA 是一种大语言模型(LLM)长文本理解能力评估方法。不同于传统“大海捞针”(Needle-in-a-Haystack, NIAH)测试依赖关键词匹配的做法,它最大的特点是 通过精心设计问题和关键信息,迫使模型进行深层语义理解和推理,才能从长文本中找到答案。
在 ChatGPT 爆火两年多的时间里,大语言模型的上下文窗口长度基准线被拉升,以此为基础所构建的长 CoT 推理、多 Agent 协作等类型的高级应用也逐渐增多。
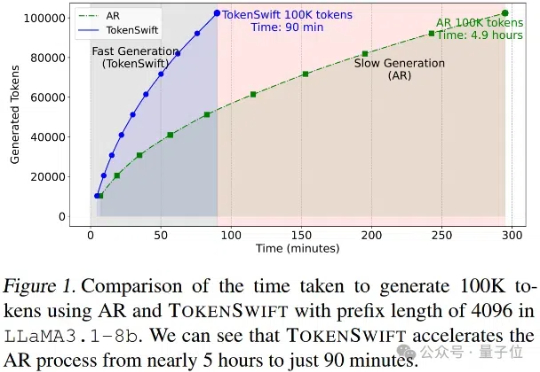
大语言模型长序列文本生成效率新突破——生成10万Token的文本,传统自回归模型需要近5个小时,现在仅需90分钟!
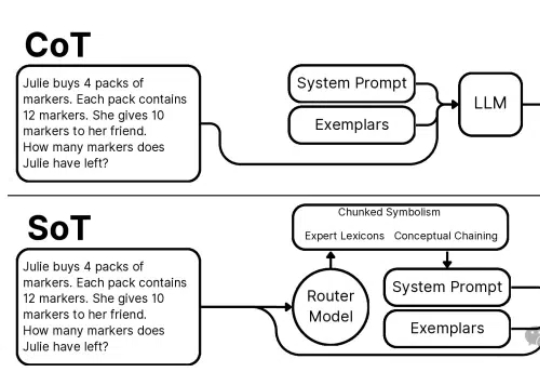
本文介绍了一项突破性的AI推理技术创新——思维草图(SoT)框架。该框架从人类认知过程中获取灵感,通过一个200M大小的路由模型将LLM引导到概念链、分块符号化和专家词汇三种推理范式,巧妙地解决了大语言模型推理过程中的效率瓶颈。

北京时间3月10日,据《华尔街日报》报道,富士康母公司鸿海已研发出中国台湾地区首个具备先进推理能力的大模型,性能上落后于DeepSeek的部分大模型。鸿海周一表示,已自主研发了具备推理能力的人工智能(AI)大语言模型FoxBrain,并在四周内完成训练。FoxBrain最初为公司内部使用而设计,具备数据分析、数学运算、推理以及代码生成的能力。
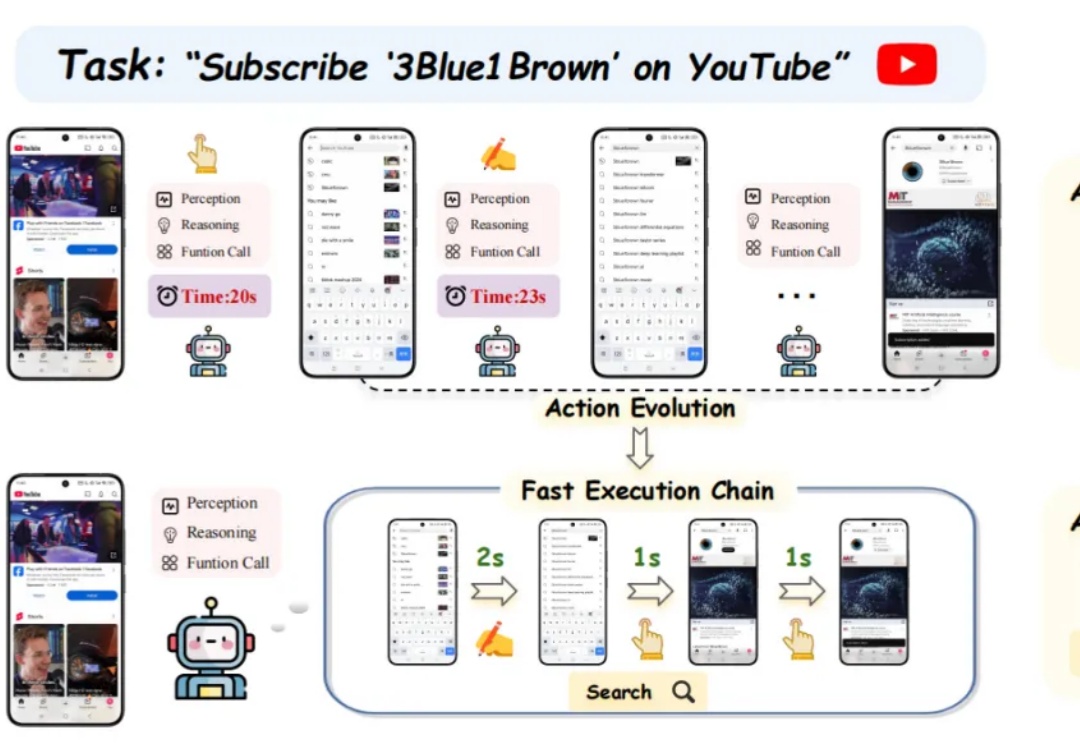
近年来,大语言模型(LLM) 的快速发展正推动人工智能迈向新的高度。像 DeepSeek-R1 这样的模型因其强大的理解和生成能力,已经在 对话生成、代码编写、知识问答 等任务中展现出了卓越的表现。
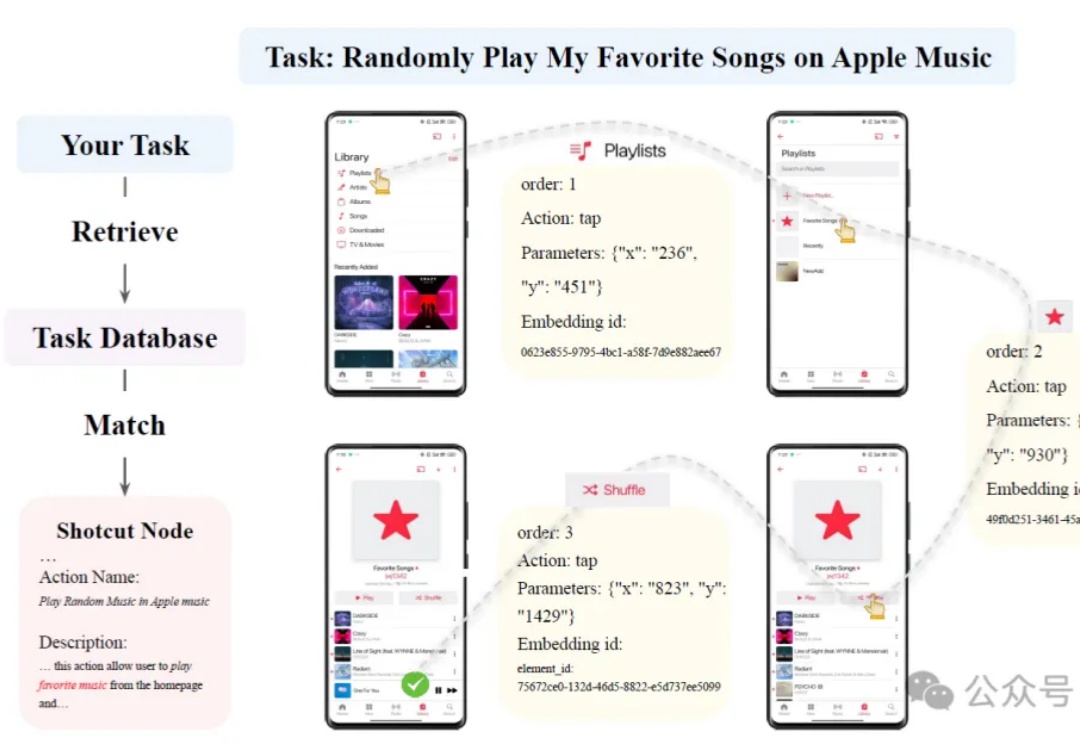
人工智能正迎来前所未有的变革,其中,大语言模型(LLM)的崛起推动了智能系统从信息处理向自主交互迈进。
大家好,很高兴在这里向各位介绍我们的产品 Free QWQ。这是世界上第一个完全免费、无限制、无需注册登录的分布式 AI 算力平台,基于 QwQ 32B 大语言模型提供强大的 AI 服务。

北京大学、上海人工智能实验室、南洋理工大学联合推出 DiffSensei,首个结合多模态大语言模型(MLLM)与扩散模型的定制化漫画生成框架。该框架通过创新的掩码交叉注意力机制与文本兼容的角色适配器,实现了对多角色外观、表情、动作的精确控制
技术上,从传统的关键词检索,到RAG,大家已经不满足于只是生成对应的简单回答。而是期待大语言模型能够更好地应用于企业级场景,产生更大的价值。不久前,OpenAI推出了最新的深度内容生成神器“DeepResearch”,用户只需一个"特斯拉的合理市值是多少"的提问,