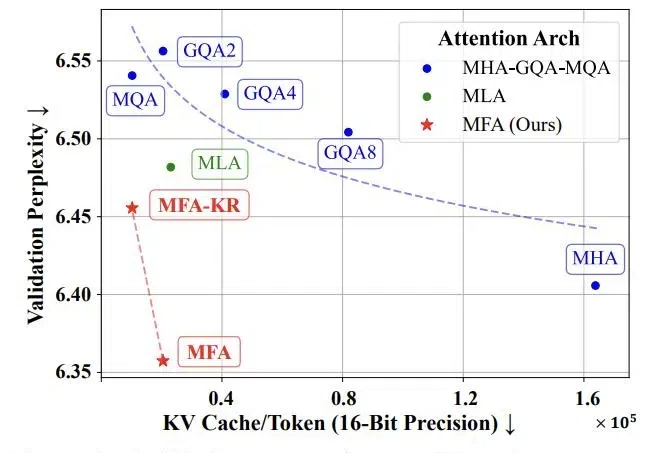
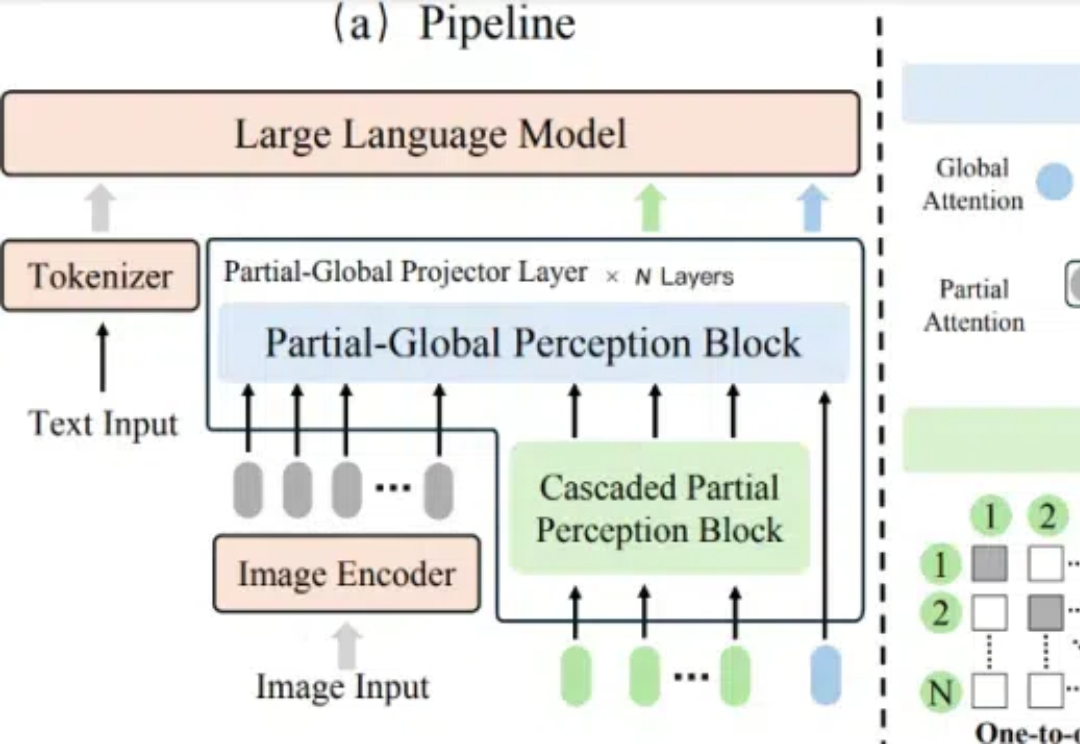
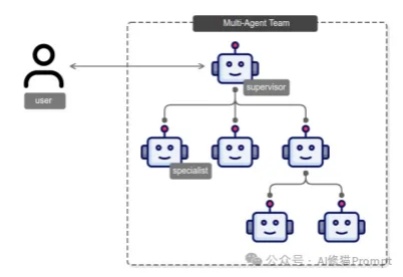
垃圾提问+垃圾解读=垃圾文章:用「幻觉长城」来黑DeepSeek,谁给你的胆子?
垃圾提问+垃圾解读=垃圾文章:用「幻觉长城」来黑DeepSeek,谁给你的胆子?“垃圾进,垃圾出!”在中文互联网上,一场针对国产AI技术的恶意攻击正在悄然蔓延。某些自媒体以“污染中文互联网”为名,对DeepSeek等国产大语言模型发起了一场看似正义、实则荒谬的讨伐。他们将“幻觉”这一技术术语污名化,试图用莫须有的罪名抹黑国产AI的进步。
来自主题: AI技术研报
8930 点击 2025-02-06 12:28