
4轮暴训,Llama 7B击败GPT-4!Meta等让LLM「分饰三角」自评自进化
4轮暴训,Llama 7B击败GPT-4!Meta等让LLM「分饰三角」自评自进化Meta、UC伯克利、NYU共同提出元奖励语言模型,给「超级对齐」指条明路:让AI自己当裁判,自我改进对齐,效果秒杀自我奖励模型。
来自主题: AI技术研报
10480 点击 2024-07-31 16:05
 搜索
搜索
Meta、UC伯克利、NYU共同提出元奖励语言模型,给「超级对齐」指条明路:让AI自己当裁判,自我改进对齐,效果秒杀自我奖励模型。

为了将大型语言模型(LLM)与人类的价值和意图对齐,学习人类反馈至关重要,这能确保它们是有用的、诚实的和无害的。在对齐 LLM 方面,一种有效的方法是根据人类反馈的强化学习(RLHF)。尽管经典 RLHF 方法的结果很出色,但其多阶段的过程依然带来了一些优化难题,其中涉及到训练一个奖励模型,然后优化一个策略模型来最大化该奖励。
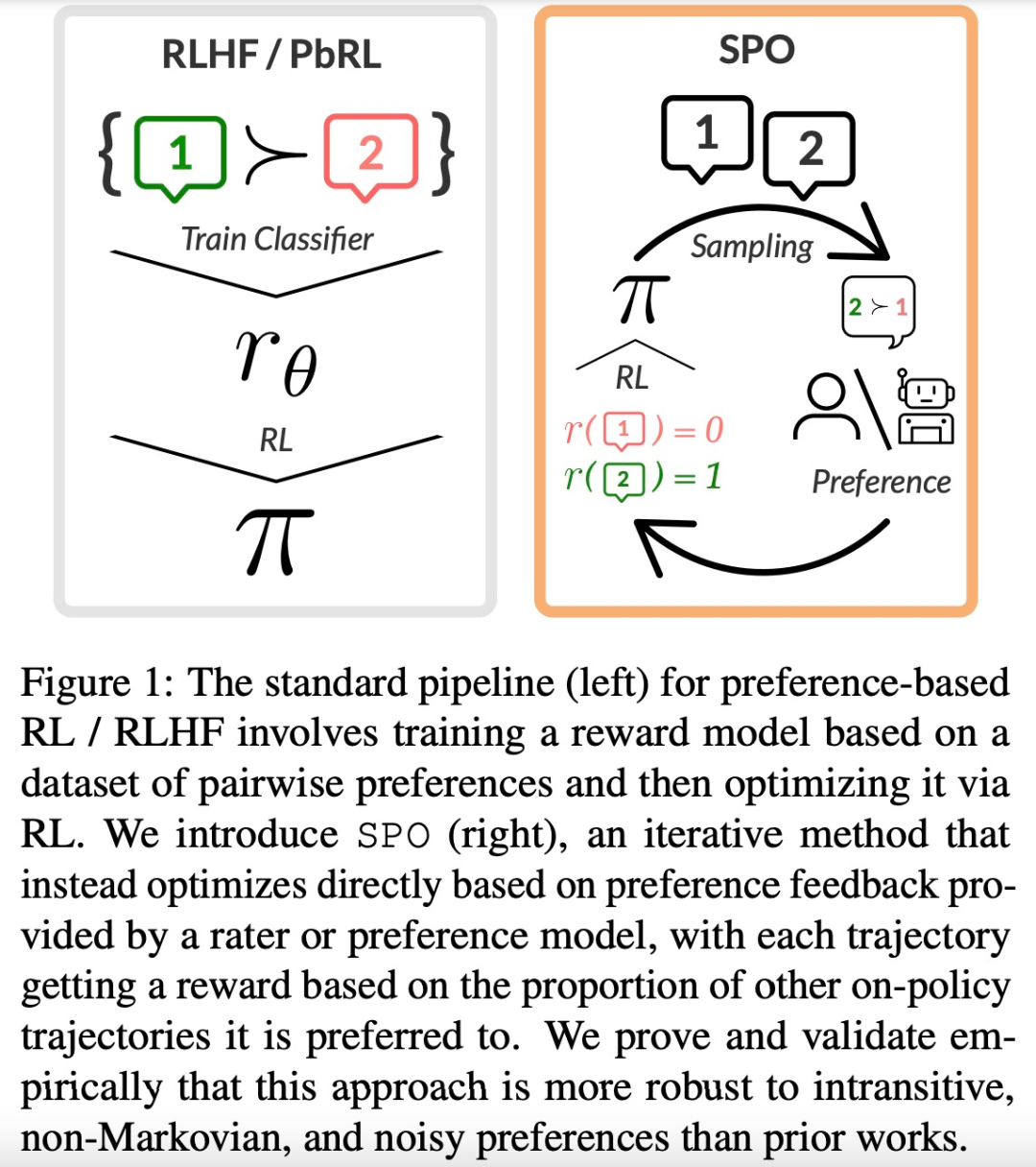
大型语言模型(LLM)的成功离不开「基于人类反馈的强化学习(RLHF)」。RLHF 可以大致可以分为两个阶段,首先,给定一对偏好和不偏好的行为,训练一个奖励模型,通过分类目标为前者分配更高的分数。
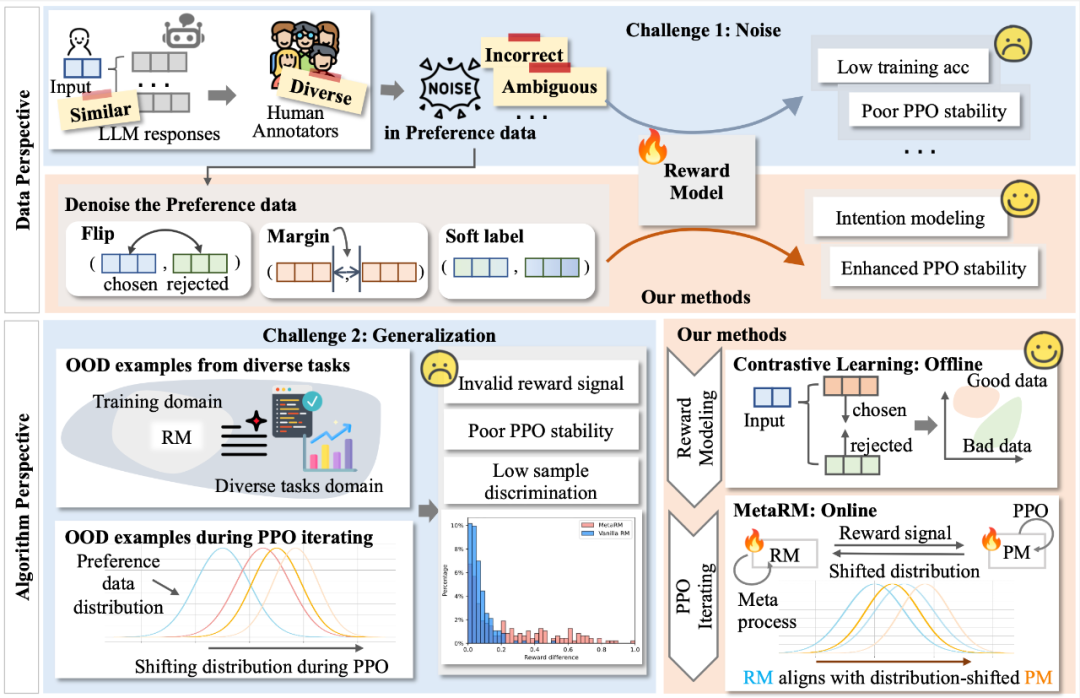
复旦团队进一步挖掘 RLHF 的潜力,重点关注奖励模型(Reward Model)在面对实际应用挑战时的表现和优化途径。

传闻中OpenAI的Q*,已经引得AI大佬轮番下场。AI2研究科学家Nathan Lambert和英伟达高级科学家Jim Fan都激动的写下长文,猜测Q*和思维树、过程奖励模型、AlphaGo有关。人类离AGI,已是临门一脚了?