开源新王炸!10B多模态小模型屠榜,性能媲美20倍巨无霸
开源新王炸!10B多模态小模型屠榜,性能媲美20倍巨无霸10B参数拥有媲美千亿级模型的多模态推理实力。
来自主题: AI技术研报
7996 点击 2026-01-21 12:02
 搜索
搜索
10B参数拥有媲美千亿级模型的多模态推理实力。
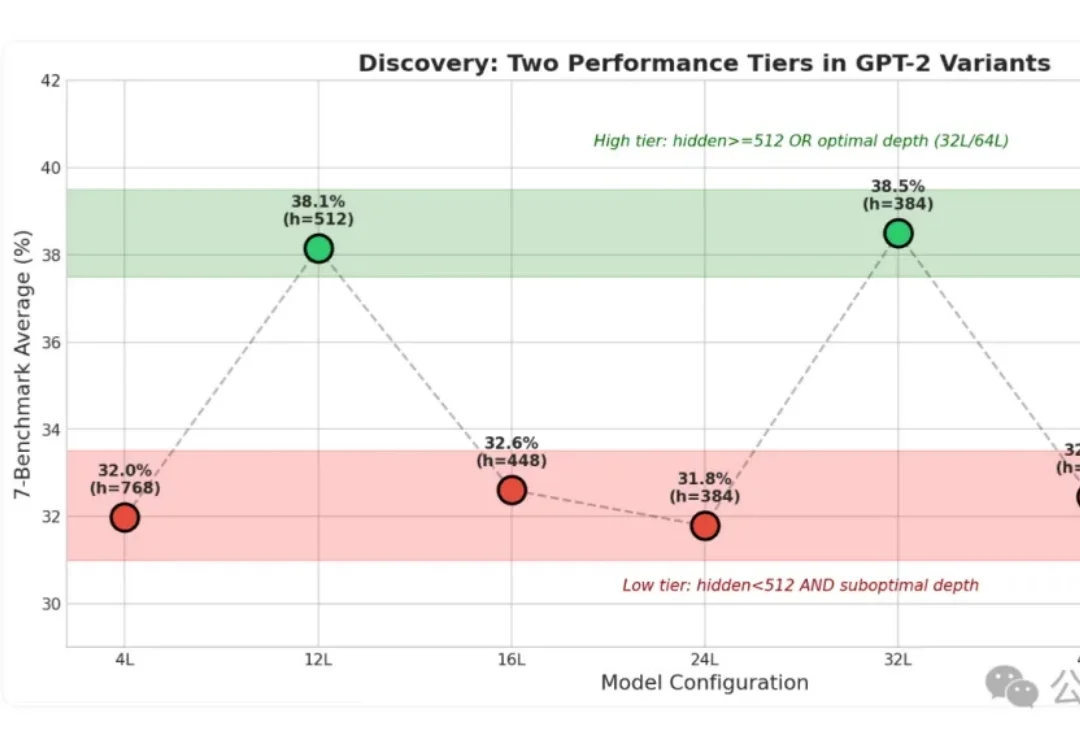
小模型身上的“秘密”这下算是被扒光了!

联想给出的公式是,混合AI=个人智能+企业智能+公共智能。这种模式下,AI智能体应用不再依赖于单一的云端模型,而是云端大模型与本地定制化小模型的深度融合。
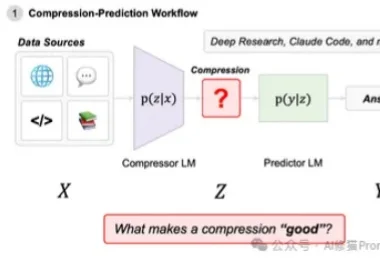
在近一年里,Agentic System(代理系统/智能体系统)正变得无处不在。从Open AI的Deep Research到Claude Code,我们看到越来越多的系统不再依赖单一模型,而是通过多模型协作来完成复杂的长窗口任务。
。过去的行业共识是:端侧只能跑小模型,性能与体验必须妥协;真正的能力仍得依赖云端最强模型。万格智元要打破的,正是这条旧认知。公司正在打造的cPilot端侧算力引擎,选择了一条更难、却更接近未来的路径:通过自研的非GPU推理引擎,让300亿、500亿等超大模型在性能有限制的消费硬件上高效推理

AI不应是巨头游戏,模型也不是越大越聪明。近日,「Transformer八子」中的Ashish Vaswani和Parmar共同推出了一个8B的开源小模型,剑指Scaling Law软肋,为轻量化、开放式AI探索了新方向。
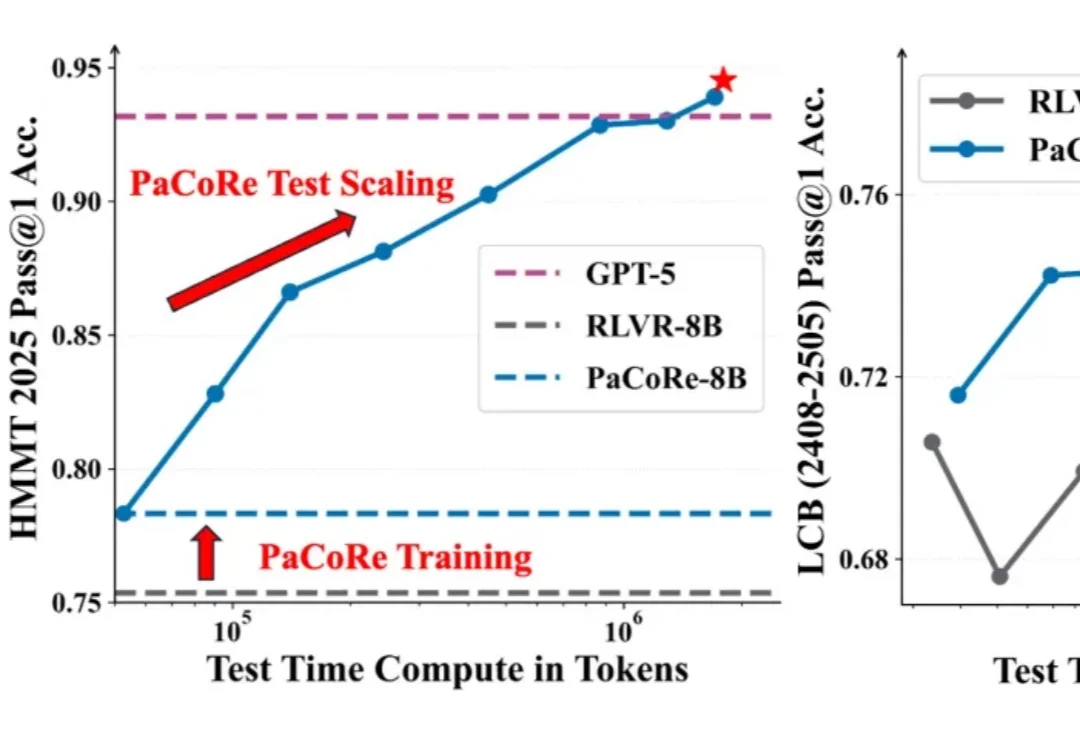
8B 模型在数学竞赛任务上超越 GPT-5!

今天我们正式发布 Jina-VLM,这是一款 2.4B 参数量的视觉语言模型(VLM),在同等规模下达到了多语言视觉问答(Multilingual VQA)任务上的 SOTA 基准。Jina-VLM 对硬件需求较低,可在普通消费级显卡或 Macbook 上流畅运行。
6B小模型,首日下载量高达50万次,上线不到两天直接把HuggingFace两个榜单都冲了个第一。
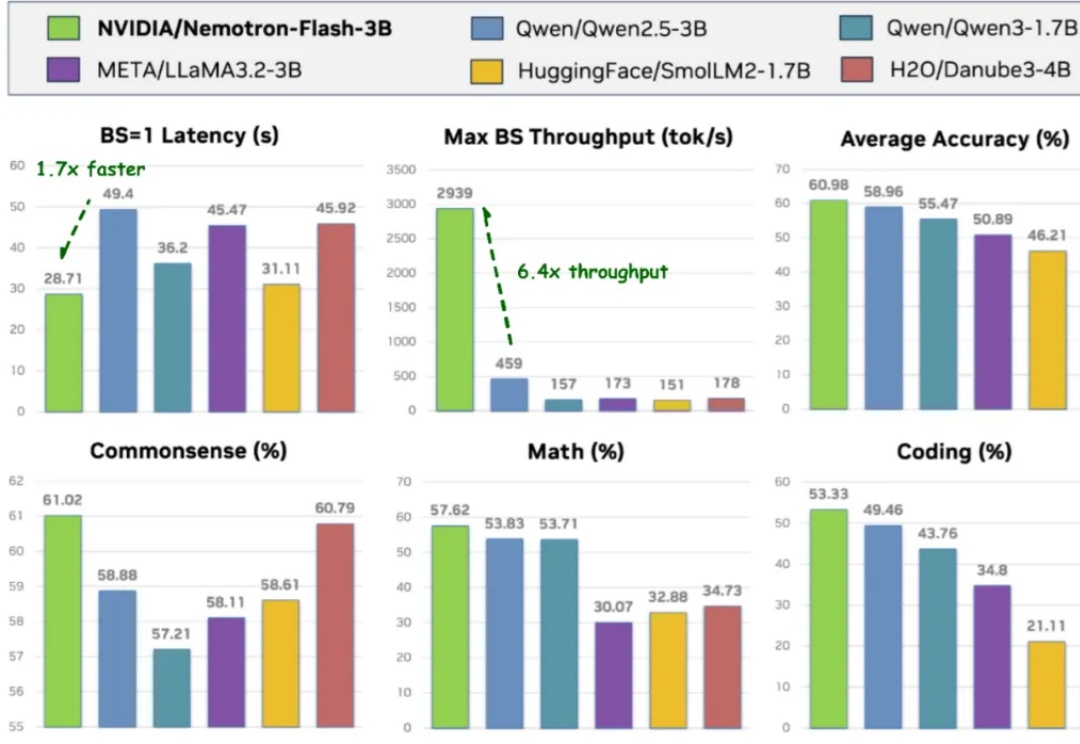
导读 过去两年,小语言模型(SLM)在业界备受关注:参数更少、结构更轻,理应在真实部署中 “更快”。但只要真正把它们跑在 GPU 上,结论往往令人意外 —— 小模型其实没有想象中那么快。