
突发!阿里AI产线大整合,92年陈宇森统管三大Agent
突发!阿里AI产线大整合,92年陈宇森统管三大Agent阿里两个拳头Agent被兄弟团队“吞”了。
来自主题: AI资讯
6402 点击 2026-07-03 10:11
 搜索
搜索
阿里两个拳头Agent被兄弟团队“吞”了。

施耐德电气(Schneider Electric SE)同意以 31 亿美元全现金交易收购 Cognite,以扩大其工业数据与 AI 软件业务。这也是欧洲工厂加速现代化浪潮中的一项重要布局。这家法国能源管理设备制造商计划将 Cognite 与旗下工业软件业务 Aveva 进行整合。

做 AI 产品还需要 PM 吗?如果需要的话,AI 时代的 PM 需要做什么?

昨天,消息说孙天祥加入百度,担任基础模型研发部(BMU)负责人。「elsewhere」最开始知道孙天祥,还是投资人韩锐跟我们说的。大概一年半之前,他说他投资了一个“young talent”,就是1997年的孙天祥。当时他刚离开阳陆育的公司。

设想这样一幕:你让一个编码智能体修复某个 bug,并用一组单元测试作为「做对了没有」的判据。

做大模型RL微调,你是不是也踩过这些坑?

太惊悚了!经历18天强制断网,Claude不仅没脑死亡,竟靠着断网前写下的「生前手稿」完成了赛博复活,绝密内心自白曝光。
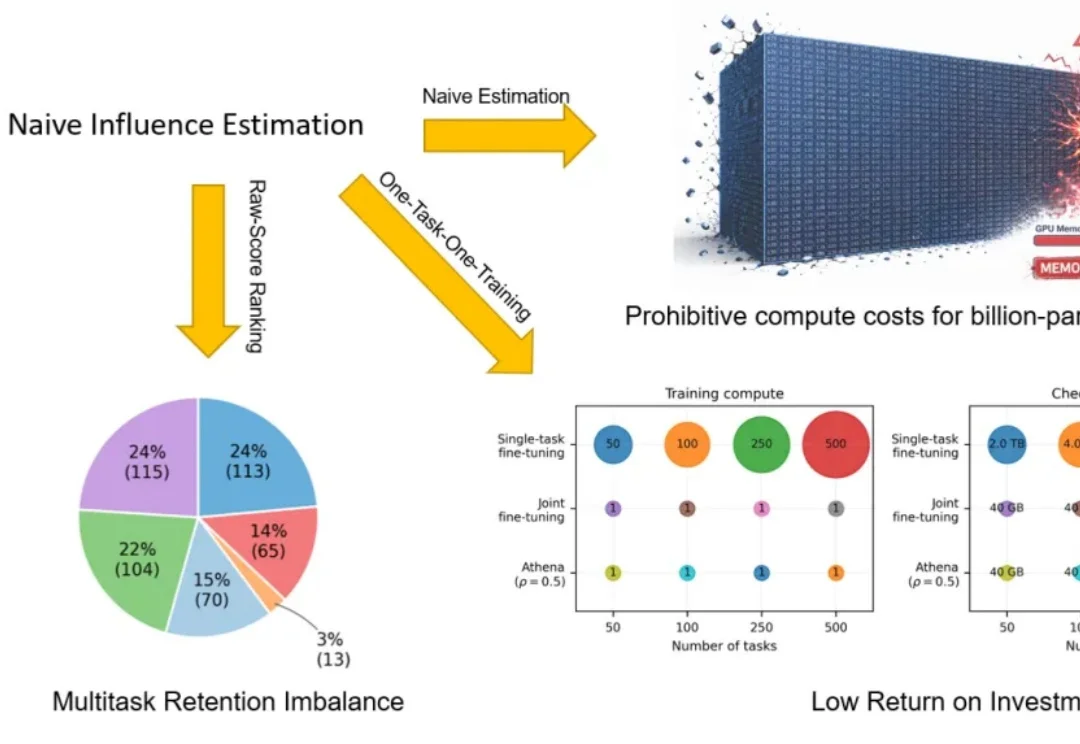
具身智能正在进入数据 scaling 时代。Vision-Language-Action(VLA)模型让机器人可以从大规模示教数据(demonstrations)中学习更通用的操作策略。但对机器人 VLA 训练来说,数据并不总是越多越好:低质量数据可能会拖累模型性能,而每一条 demonstration 都意味着昂贵的人力采集、机器人运行,以及云端存储和训练成本。
据证监会网站7月2日消息,证监会1日发布关于同意宇树科技股份有限公司首次公开发行股票注册的批复:根据《中华人民共和国证券法》《中华人民共和国公司法》《国务院办公厅关于贯彻实施修订后的证券法有关工作的通知》(国办发〔2020〕5号)和《首次公开发行股票注册管理办法》(证监会令第205号)等有关规定,经审阅上海证券交易所审核意见及你公司注册申请文件,现批复如下:

VAST 本月再次完成超 10 亿元人民币 A3 战略轮融资。一个月之前,这家公司刚刚披露完成约 2 亿美元融资,并正式披露世界模型项目 Project Eden。连续融资当然是一个重要信号。但这一轮更值得关注的,不只是金额,还有投资方的构成。