# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
在过去几年,自动驾驶圈流行一句话:「大模型会说话,但不会开车。」
一方面,大规模视觉语言模型(VLM)在文本理解和逻辑推理上突飞猛进;另一方面,一旦把它们放到真实道路上,让它们处理长尾场景、远距离目标和复杂博弈时,这些 “聪明大脑” 却常常犯低级错误:看不清、定位不准、反应不稳定。深层原因在于 —— 现有 VLM 在空间感知和几何理解上的能力,远远跟不上它们在语义层面的 “表达能力”。
为了让大模型真的能 “看懂世界”,在很多现有方案中,研究者会在训练中加入一些 “感知类 QA” 问题,比如问 “左前方有没有车”“两车距离有多远”。但这类监督更多停留在语义标签和粗略相对关系层面,并没有让模型真正学会可用于控制决策的强 2D/3D 感知能力 —— 例如精确、稳定的检测框、分割结果和 BEV 感知信息。换句话说,今天很多 VLA 仍然停留在「会回答关于世界的问题」,而不是「真的看清这个世界」。这种 “弱感知的大模型”,显然不足以支撑自动驾驶和广义具身智能对空间理解的高要求。
近日,来自引望智能与复旦大学的研究团队联合提出了一个面向自动驾驶的新一代大模型 ——Percept-WAM(Perception-Enhanced World–Awareness–Action Model)。该模型旨在在一个统一的大模型中,将「看见世界(Perception)」「理解世界(World–Awareness)」和「驱动车辆行动(Action)」真正打通,形成一条从感知到决策的完整链路。

在架构设计上,如图 1 所示,Percept-WAM 基于具备通用推理能力的 VLM主干构建,在保留其原有语言与推理优势的同时,引入 World-PV / World-BEV 世界 Token,统一 PV / BEV 视角下的 2D/3D 感知表示:通过可学习的 BEV 级栅格 Token 将多视角 PV 特征隐式映射到 BEV 空间,并采用栅格条件(grid-conditioned)预测机制;在解码侧,则结合 IoU-aware 置信度输出与并行自回归解码等关键技术来提升输出的精度及效率,同时配备轻量级动作解码头,用于高效预测未来行车轨迹。
在训练任务上,Percept-WAM 接收多视角流式视频、LiDAR 点云 (可选) 以及文本查询作为输入,在同一模型上联合优化 PV 下的 2D 检测、实例分割、语义分割、单目 3D 检测任务等, BEV 下的 3D 检测与 BEV map 分割任务等,以及基于多帧输入的轨迹预测任务。
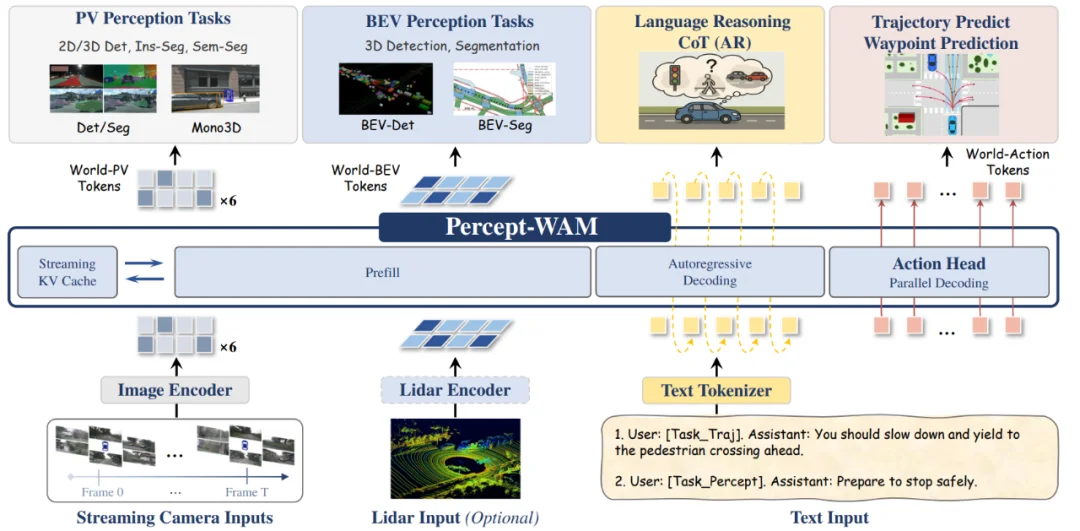
图 1:Percept-WAM 模型整体架构图
Percept-WAM 围绕 World–Awareness–Action 构建统一的世界 token 空间:多视角图像和 3D 场景被压缩为一小组结构化 World tokens。每个 token 显式携带语义特征、空间位置以及置信度,用作 2D/3D 感知、轨迹预测等下游任务的共享世界表征。
在图像平面,World-PV tokens 将每帧图像划分为规则栅格,每个栅格对应输出一组 token,联合编码局部外观与 2D/3D 几何信息(如像素坐标、归一化尺寸、视线方向等)。基于同一组 PV tokens,模型可以统一建模 2D 检测、实例 / 语义分割、单目 3D 检测等任务,后续再叠加栅格条件预测与 IoU-aware 评分机制,提升密集 2D 感知的稳定性和排序质量。
在鸟瞰 (BEV) 视角,World-BEV tokens (根据是否存在 Lidar 点云特征,可选的从 LiDAR 特征初始化或随机初始化) 对应覆盖前方场景的固定分辨率 BEV 网格单元。每个 BEV token 通过与多视角 PV 特征的交互,隐式建模 PV 到 BEV 上的映射,聚合该网格区域的占据状态、语义类别和运动属性(如速度、朝向等),在世界 token 空间中显式刻画道路结构与交通参与者的空间关系。
为支撑城市场景中的高密度目标预测及对应物体预测置信度的矫正,Percept-WAM 在解码端引入 栅格条件预测(Grid-Conditioned Prediction) 和 IoU-aware 置信度回归 两项关键设计。
栅格条件预测借鉴了 UFO [1] 的思想,将整个特征空间按 PV/BEV 栅格划分为多个子区域,并围绕每个栅格构造局部自回归序列,其中 (i) 每个栅格对应一条局部自回归子序列,只回归该区域内对应的候选目标;(ii) 不同栅格之间通过注意力 mask 做隔离,限制跨区域的无关交互,进行并行训练及预测,显著缩短了单序列长度,减轻了超长序列导致的训练不稳定和目标间干扰,提升了高密度场景下的收敛性与训推效率。
IoU-aware 置信度预测则显式建模候选框的定位质量。在训练阶段监督置信度微调数据集(Confidence-tuning Dataset)的分值 token,在推理阶段输出预测框与真实框的 IoU 预测结果,并将该 IoU 置信度分数与分类分数联合用于整体置信度排序。相比仅依赖分类得分的传统方案,这一设计在小目标、远距离目标以及长尾类别上能够提供更一致的候选排序,减少 NMS 阶段的误删与误保留,从而整体提升密集检测的可靠性。
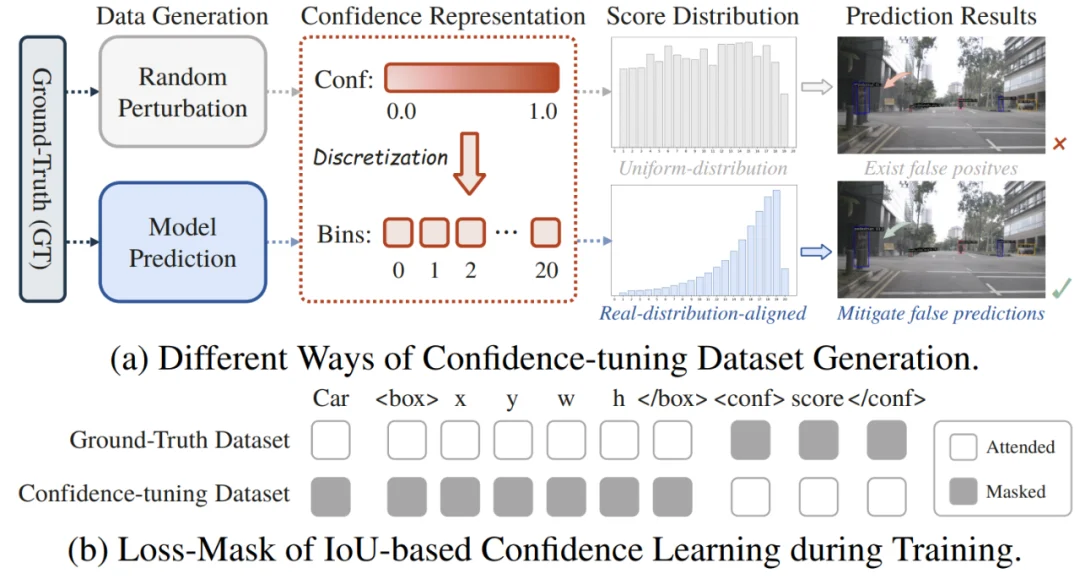
图 2:利用 IoU-aware 置信度来显式建模候选框的定位质量,(a) 不同产生 IoU score 训练数据集的方式对比;(b) 原有训练数据以及带 IoU Score 训练数据的不同 loss mask 方式对比
Percept-WAM 模型在感知类 world tokens 之上进一步引入 World–Action tokens,用于动作与轨迹预测的查询(queries)。这些 tokens 从 World-PV / World-BEV 等感知 tokens 中聚合多视角图像与 BEV 表征(以及可选 LiDAR)的信息,并与历史轨迹、车速、转向等车辆状态融合,在统一坐标系下直接生成未来规划轨迹或控制信号;相比 “先产出 BEV 特征、再交由独立规划网络 (Diffusion)” 的两阶段方案,World–Action 在同一 token 空间内完成从世界建模到决策输出,使感知与规划在表示空间和时空对齐上天然一致。
在解码方式上,Percept-WAM 将未来轨迹离散为一系列关键点或片段,结合并行化策略进行加速,避免传统自回归 “一点一点推” 的 AR 推理的效率瓶颈。具体来说,在轨迹解码方式上,Percept-WAM 采用轻量级 MLP 解码头驱动的 query-based 轨迹预测:World–Action 由一组功能不同的查询组成,其中一部分查询仅关注自车状态特征(只与 Ego-state 交互),一部分查询仅关注 PV 侧特征(只与 World-PV 交互),一部分查询仅关注 BEV 侧特征(只与 World-BEV 交互),还有一部分同时汇聚所有输入特征的信息,在融合视角下输出最终轨迹。这种多组查询并行工作的方式,一方面保留了 PV / BEV 各自对局部几何与全局结构的优势,另一方面通过共享的 World tokens 建立统一的世界状态,避免轨迹预测任务过度依赖部分输出特征。
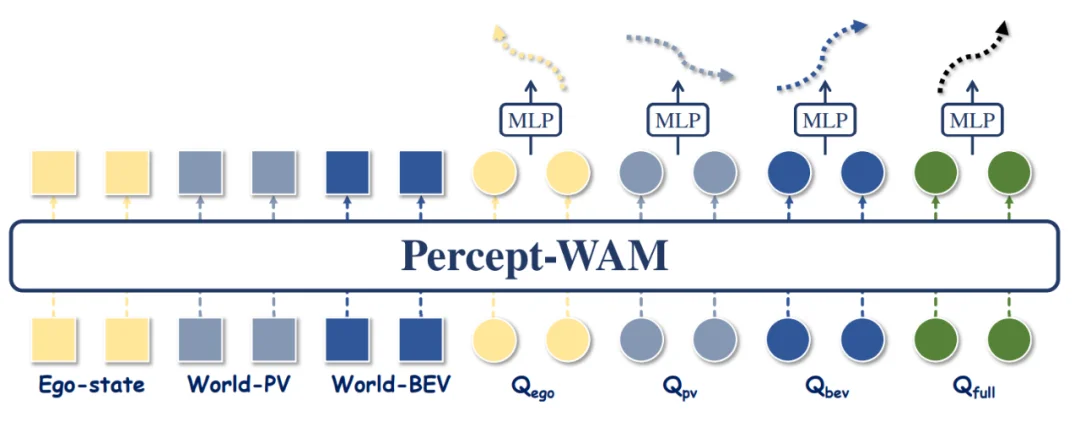
图 3:轨迹解码 head 结构可视化,不同组 query 关注不同的特征 (如自车,PV,BEV 特征),Qfull 关注所有的特征并输出最终轨迹
面向连续驾驶场景,Percept-WAM 引入 streaming inference:在时间维度上采用 streaming KV cache strategy 复用历史帧的注意力缓存,仅对新到达的帧做增量计算;同时通过 longer-clip training scheme 和 dual-recomputation KV cache mechanism 缓解训练–推理范式不一致带来的 distribution drift 与误差累积,从而在几乎不牺牲规划精度的前提下,显著降低多帧多视角端到端推理的时延与计算开销。
在公开基准上,Percept-WAM 在 PV 视角感知、BEV 视角感知以及端到端轨迹规划 三个层面相较于现有模型均展现出强竞争力。
1)PV 视角:统一 PV 场景下感知的 World-PV
在图像平面上,Percept-WAM 基于 World-PV tokens 统一建模 2D 检测、实例 / 语义分割与单目 3D 感知任务,具体表现为:
如表 1 所示,在 nuImages /nuScenes 的 PV 任务上,Percept-WAM 在 2D 与 Mono 3D 上整体匹配或超过专用模型 —— 在 2D detection 上达到 49.9 mAP,相比 Mask R-CNN 的 47.8 mAP 有明显提升;在 2D instance segmentation 上取得 41.7 mAP,高于 Mask R-CNN 的 38.6 mAP;在 mono 3D detection 上达到 33.0 mAP,同样优于 FCOS3D 的 32.1 mAP。
实验观察到明显的 2D–3D 协同效应:在统一 World-PV 表征下联合建模 2D 与 3D 检测,可带来约 +3.2 mAP 的 2D 检测增益。进一步在自动驾驶 PV 数据集上对所有 PV 任务进行联合训练,各基准上基本维持一致或提升,说明统一的 World-PV token 空间有利于在多任务之间共享有用的几何与语义信息。
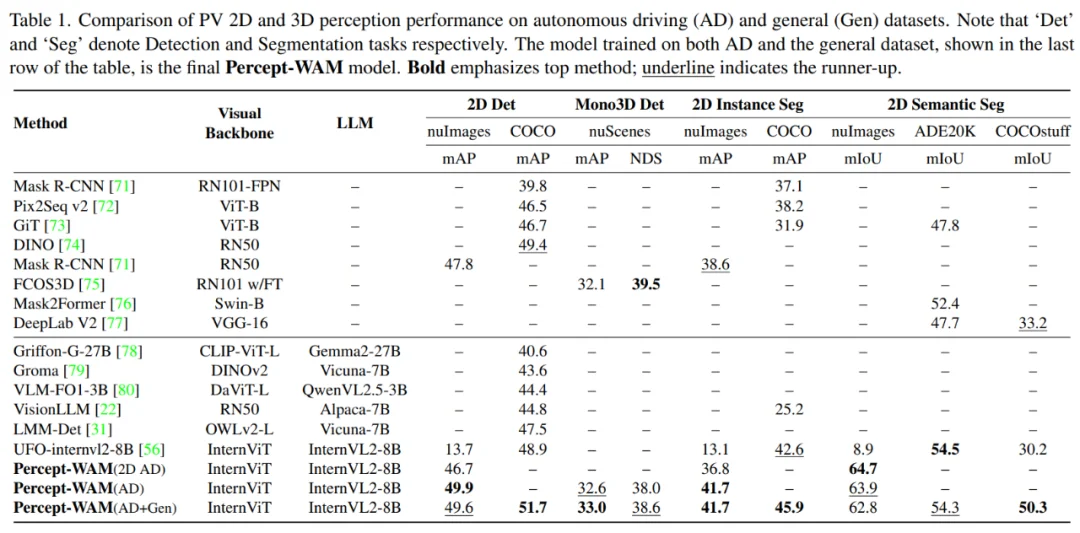
表 1: PV 场景下 Percept-WAM 的效果与其他主流模型的对比
该文章同时可视化了预测的置信度分数(x 轴)与对应框真实 IoU(y 轴)之间的关系。如下图所示,引入 IoU-based confidence prediction 后,散点分布整体向 y = x 附近收敛,而在基于 model-prediction 数据集进行训练的设置下,曲线与对角线的贴合度最高,说明预测分数与真实定位质量更加一致,更适合作为后续筛选与排序的依据。
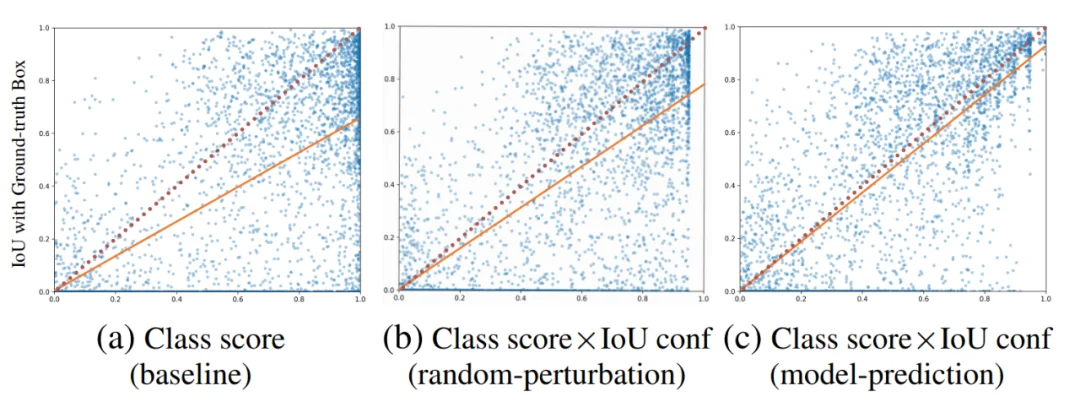
图 4: PV 任务上置信度分数矫正前后分数分布对比,不同图像代表不同的置信度分数构建方式或者不同的带 IoU score 的训练数据生产方式
2)BEV 视角:World-BEV 承载 3D 场景理解
在 BEV 空间中,Percept-WAM 通过 World-BEV tokens 统一建模路面占据、动态目标与地图语义。如表 2 所示,即便在不使用时序信息、且采用相对较低图像分辨率(448×796)的设置下,仍在 nuScenes 上展现出强竞争力的 BEV 感知能力:
在 nuScenes BEV 3D detection 上,Percept-WAM 在无时序、低分辨率输入的条件下依然取得 58.9 mAP,整体表现优于经典 BEV 检测方法,如 PointPillars 与 SECOND 等 specialist 检测器。
在 BEV map segmentation 任务上,基于 World-BEV tokens 的分割头可以同时刻画车道线、可行驶区域、行人横穿区等静态语义要素;在部分关键类别(如 drivable area、pedestrian crossing)上,Percept-WAM 的分割结果可以超过 BEVFusion 等专用 BEV 模型。
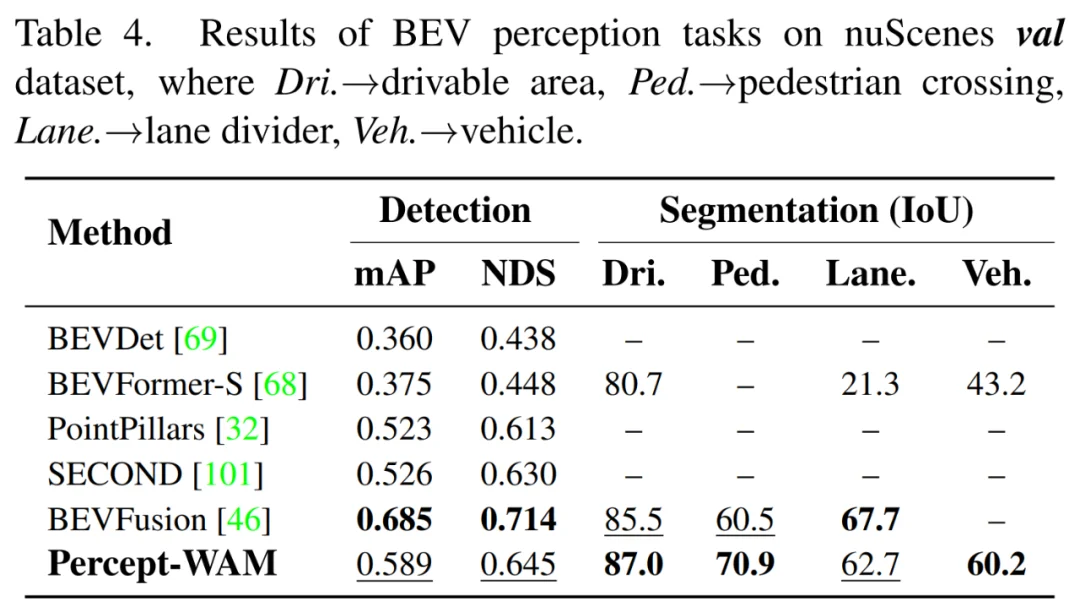
表 2: BEV 场景下 Percept-WAM 的效果与其他主流模型的对比
3)端到端轨迹规划:World–Action 连接世界与控制
在端到端轨迹规划上,如表 3 所示,搭载 World–Action 轨迹解码头的 Percept-WAM 在 nuScenes 与 NAVSIM 上都取得了有竞争力的表现,并优于多种现有 BEV-based 与 VLM-based 方案。具体来看:
在 nuScenes 的 open-loop 轨迹指标上,Percept-WAM 的平均轨迹 L2 误差约为 0.36 m,在同等设置下优于多数 BEV-based 方法(如 UniAD)以及 VLM-based 方法(如 DriveVLM)。
直接轨迹模仿学习难以兼顾开环与闭环指标,因此在 NAVSIM 的 closed-loop 评测中,Percept-WAM 采用对聚类轨迹打分的方式,获得约 90.2 的综合得分,同样优于大部分现有端到端方法。实验同时表明,两阶段训练策略(先在感知与中间任务上预训练,再在规划任务上进一步微调)可以进一步提升端到端驾驶性能。
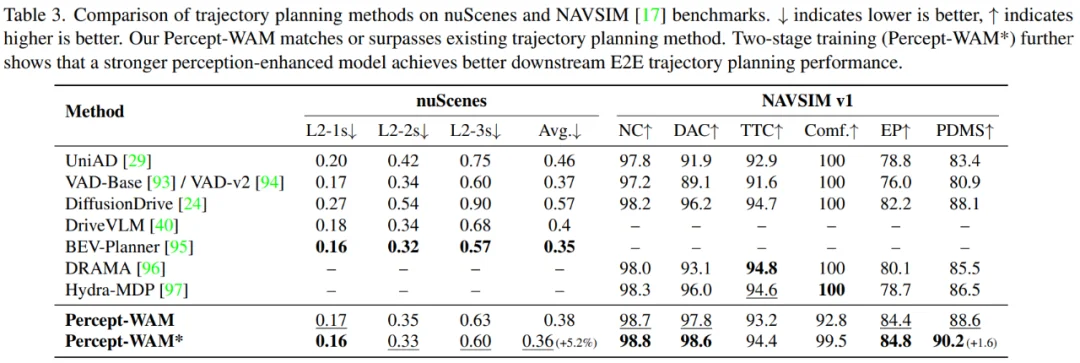
表 3: 轨迹预测场景下 Percept-WAM 的效果与其他主流模型的对比
在定量结果之外,我们还给出三类代表性可视化示例:(i)PV 视角下的 2D 检测 / 实例分割与 mono 3D 检测结果,(ii)BEV 视角下的 3D 检测与 map 分割,(iii)NAVSIM /nuScenes 场景中的端到端规划轨迹。
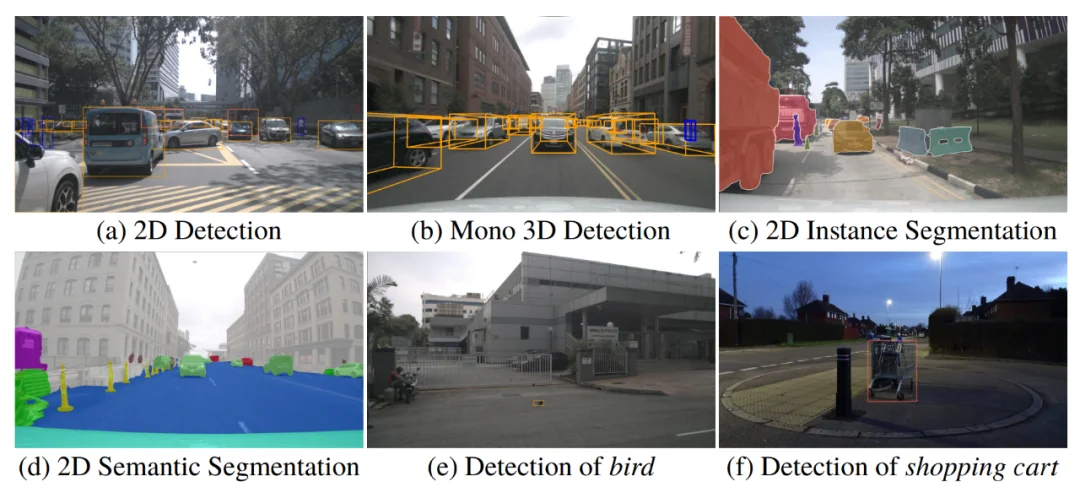
图 5: PV 感知上 Percept-WAM 预测结果可视化,图中展现了不同任务的可视化结果以及对道路上非白名单障碍物的检测情况

图 6: BEV 感知上 Percept-WAM 的 3D 检测及 Map Segmentation 结果

图 7: 轨迹预测任务上针对于路面难例 case,Percept-WAM 具有较强的预测鲁棒性
总结来看,Percept-WAM 指出了一条面向未来的演进路径:在统一大模型中做强世界感知,用 World tokens 一体化打通世界表征与行为决策,逐步沉淀可持续演进的自动驾驶世界模型。它的价值不在于 “又多了一个更大的模型”,而在于给出了一个更完整、工程上可落地的范式 —— 自动驾驶的大模型不应该只是会聊天、会问答的 “语文老师”,而应该是一个真正能构建世界、理解世界并在其中安全行动的 “世界大脑”。
参考文献:
[1] UFO: A Unified Approach to Fine-grained Visual Perception via Open-ended Language Interface
文章来自于微信公众号 “机器之心”,作者 “机器之心”



【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
