腾讯发布两大具身智能基座模型,VLM&RxBrain让机器人更懂现实世界
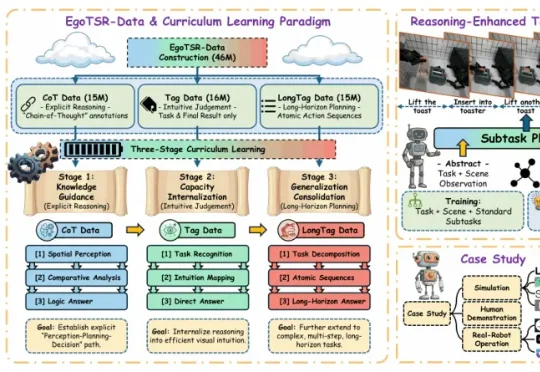
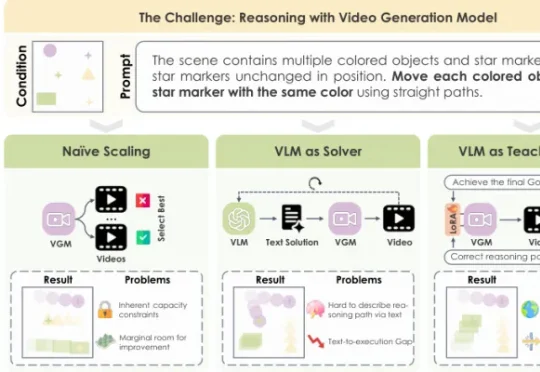
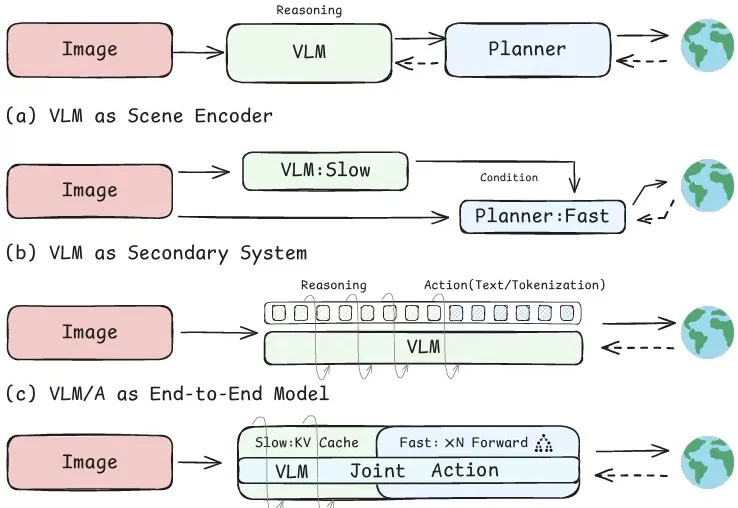
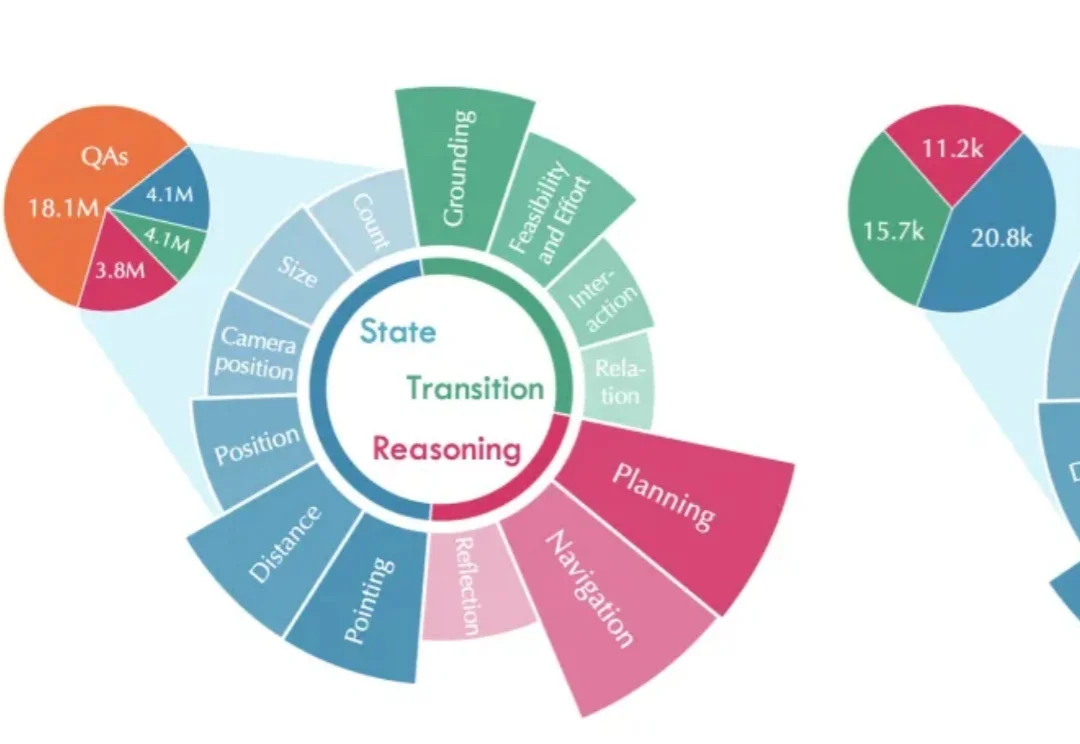
腾讯发布两大具身智能基座模型,VLM&RxBrain让机器人更懂现实世界7 月 15 日,腾讯 Robotics X 实验室以及福田实验室联合腾讯混元推出两款具身智能基座模型 —— 具身 VLM 基座模型 Hy-Embodied-VLM-1.0 以及 具身世界认知基座模型 Hy-Embodied-RxBrain-1.0,不仅让具身大脑能够 “看” 懂现实世界,还学会同时推理和想象。
来自主题: AI技术研报
10157 点击 2026-07-16 10:31