只看图片就能学会压缩Token!浙大&阿里新框架多轮VQA压缩率90%,精度不掉|CVPR 2026
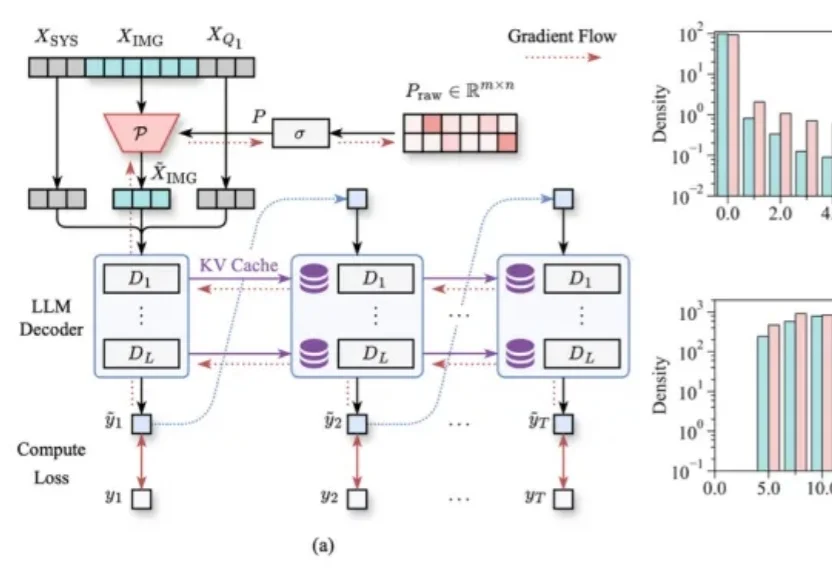
只看图片就能学会压缩Token!浙大&阿里新框架多轮VQA压缩率90%,精度不掉|CVPR 2026多轮视觉问答,正在成为LVLM推理效率的“照妖镜”。
来自主题: AI技术研报
8865 点击 2026-05-08 09:52
 搜索
搜索
多轮视觉问答,正在成为LVLM推理效率的“照妖镜”。

基于视觉语言模型(VLM)的多智能体系统(MAS)正成为复杂多模态协作的核心方案,却被一个致命痛点死死卡住:多智能体视觉幻觉滚雪球——单个智能体的视觉误判通过纯文本信息流逐级放大,早期细微错误最终演变成系统性崩溃。
就在这两天,GitHub和Hugging Face社区上线了一枚医疗大模型领域的“核弹”。全球规模最大、性能最强的医疗视频理解大模型——uAI Nexus MedVLM(中文名:元智医疗视频理解大模型)开源!

从 2024 年底的关于潜在空间的早期探索,再到 2025 年底和 2026 年初的相关研究爆发,潜空间范式正在彻底重塑大模型 (LLMs, VLMs, VLAs 等延伸模型) 的底层设计逻辑。
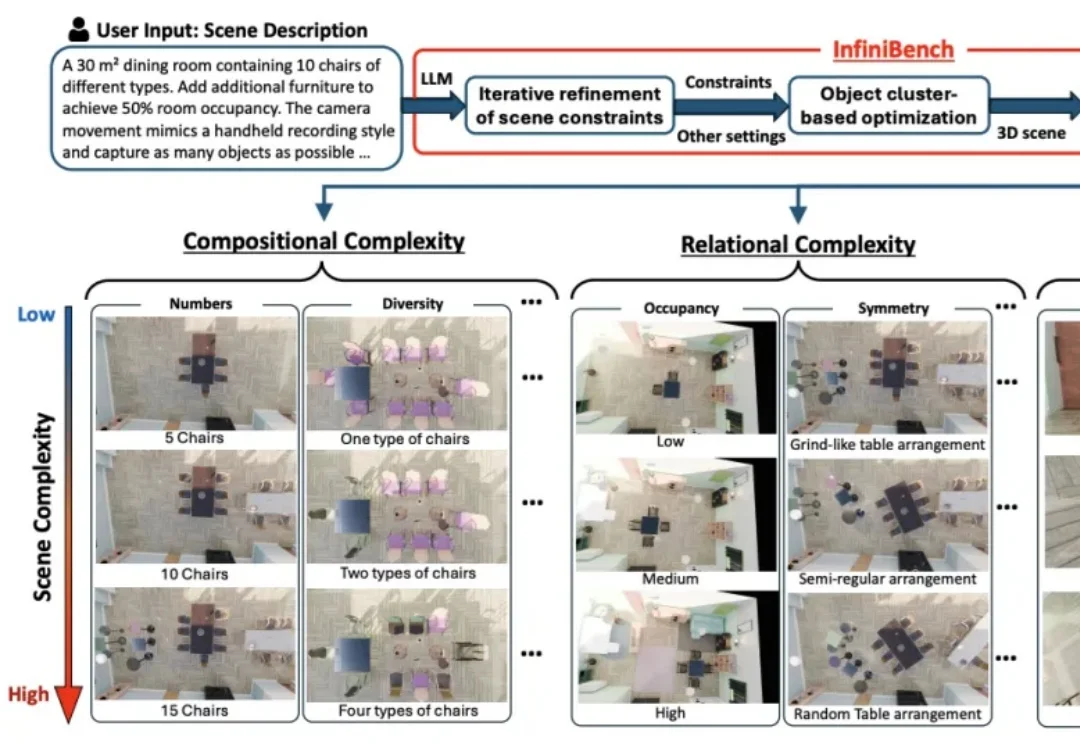
VLM看图像描述头头是道,一遇到3D空间推理就“晕菜”。
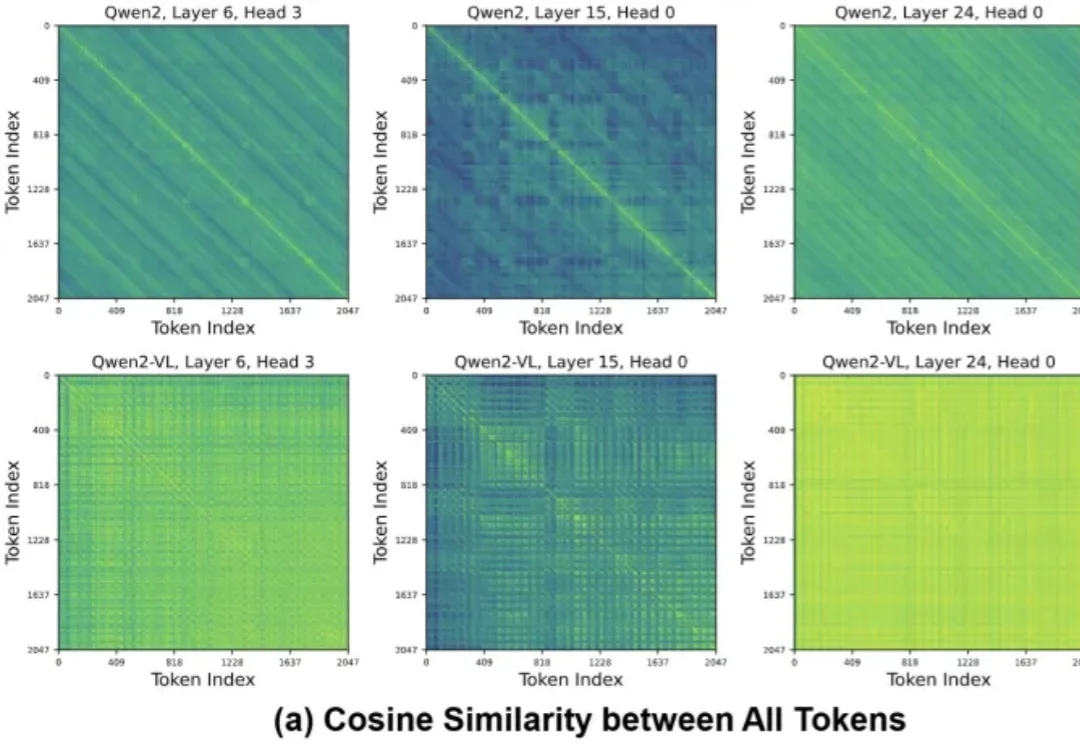
长上下文推理已经成了VLM/LLM的默认形态。
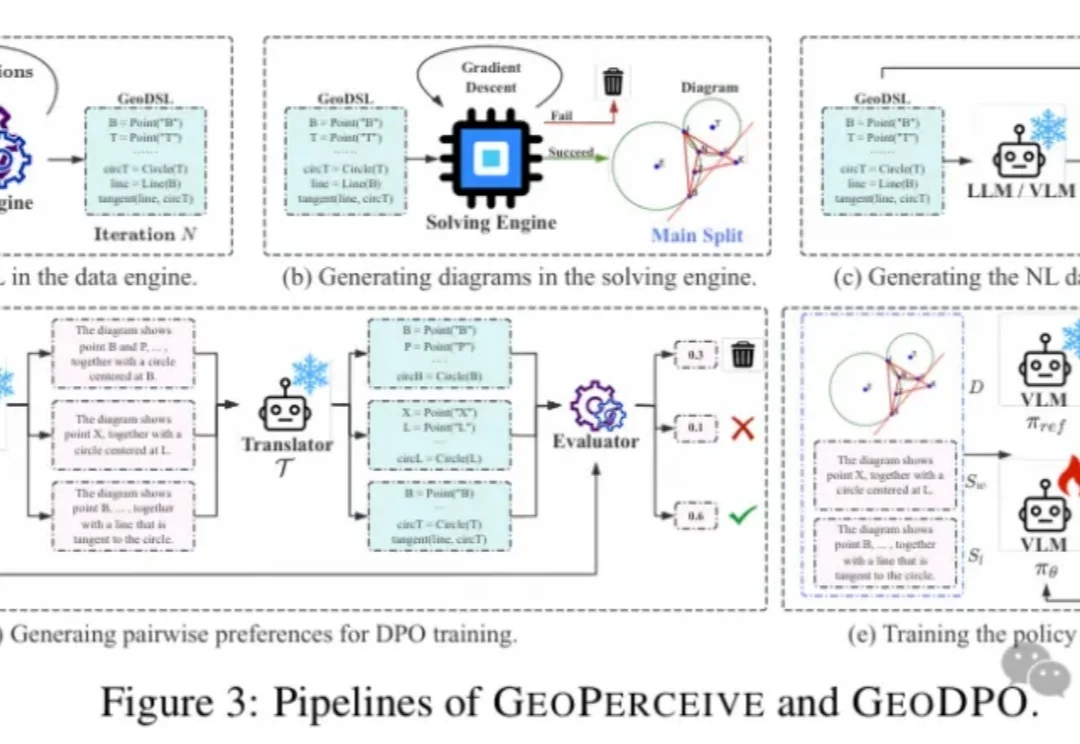
几何问题,真的只是“推理难”吗?
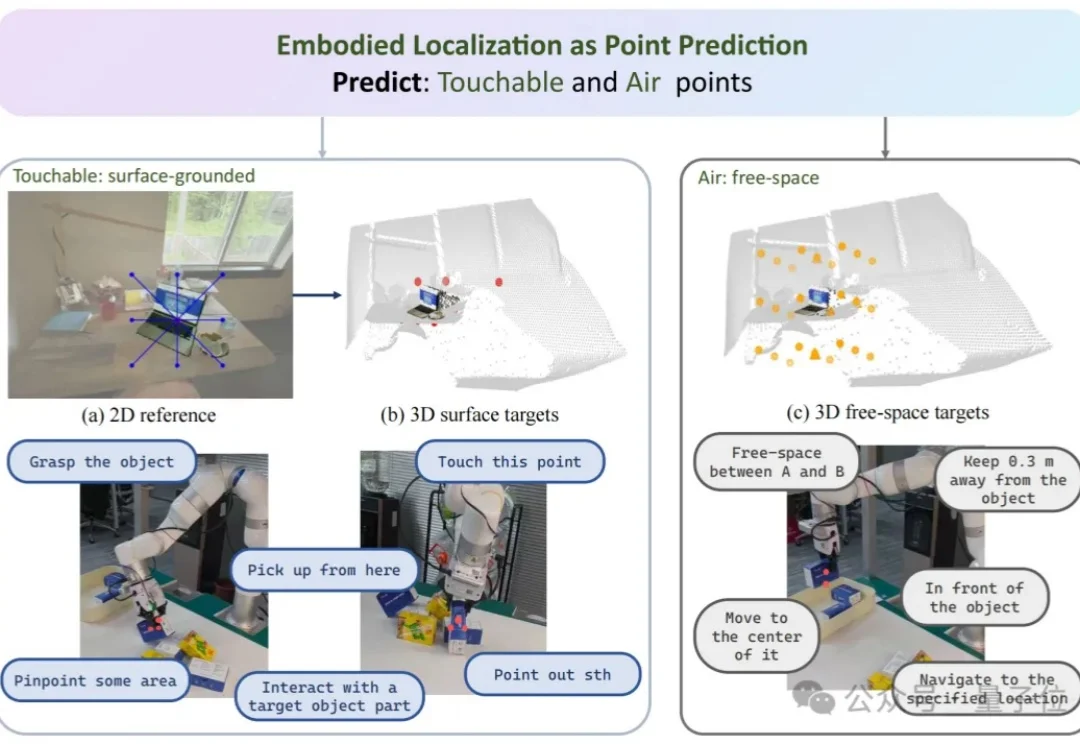
机器人能认出杯子,却看不懂杯口朝哪、离自己多远、该抓哪里。
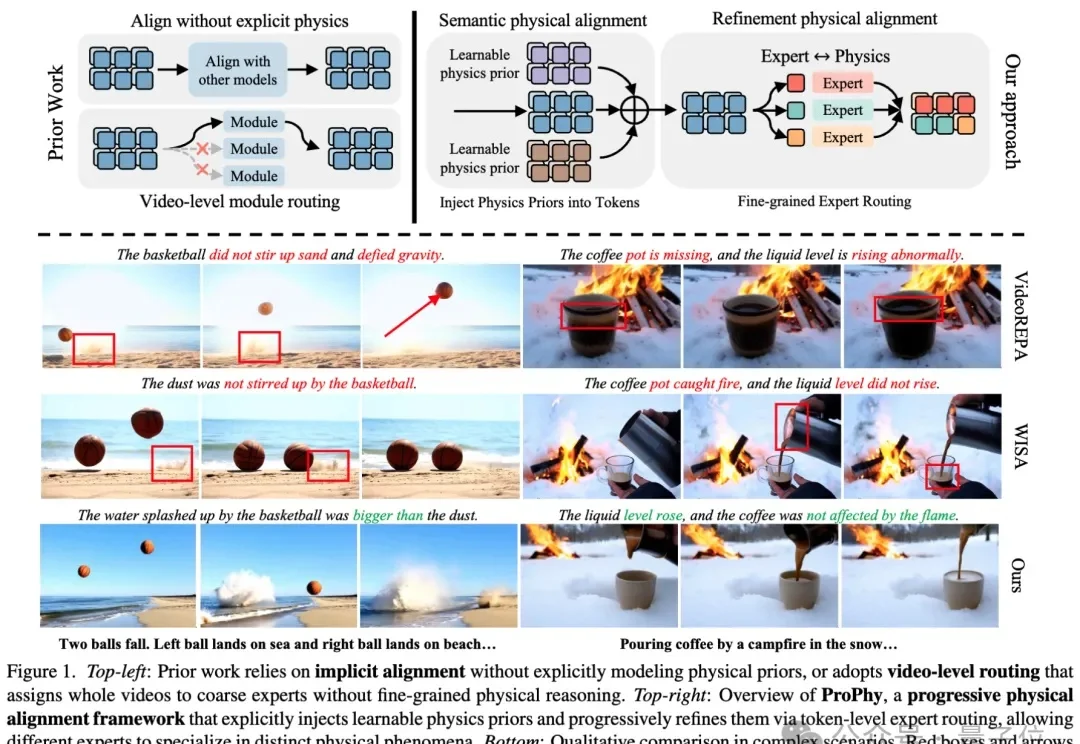
当人们谈到“世界模型”(World Models)时,很多人会首先想到近年来迅速发展的生成式视频模型。

今天的大型视觉语言模型(VLM)做离线视频分析很强,但一到实时场景就尴尬: 视频在往前走,模型还在“补作业”。